 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn In-Vitro Study on Cross-Lingual Generalization in Language Models
May 26, 2026Cross-lingual transfer in language models is difficult to study in natural corpora because lexical overlap, morphology, data imbalance, and tokenization are entangled. We introduce an in-vitro framework with two procedurally generated languages that share the same ontology, typed grammar, and compositional structure, but differ in surface realization. This lets us independently vary lexical distance, minority-language proportion, tokenizer training regime, and vocabulary size, while evaluating transfer on a masked minority-language condition whose lexical forms are never observed during training. Across 700 controlled runs, we find that transfer is governed less by tokenizer balance or raw lexical similarity than by whether tokenization preserves reusable cross-lingual substructure. Smaller vocabularies often improve masked transfer by keeping words decomposable into shared fragments, whereas larger vocabularies can turn forms into language-specific atoms. We further show that transfer emerges as a staged process: grammatical and type-level competence precede masked lexical generalization. Finally, we attempt to explain this mechanism through tokenizer bridges and show that bridge strength correlates strongly with masked reachability.
What Makes a Good Doctor Response? An Analysis on a Romanian Telemedicine Platform
Feb 19, 2026Text-based telemedicine has become a common mode of care, requiring clinicians to deliver medical advice clearly and effectively in writing. As platforms increasingly rely on patient ratings and feedback, clinicians face growing pressure to maintain satisfaction scores, even though these evaluations often reflect communication quality more than clinical accuracy. We analyse patient satisfaction signals in Romanian text-based telemedicine. Using a sample of 77,334 anonymised patient question--doctor response pairs, we model feedback as a binary outcome, treating thumbs-up responses as positive and grouping negative or absent feedback into the other class. We extract interpretable, predominantly language-agnostic features (e.g., length, structural characteristics, readability proxies), along with Romanian LIWC psycholinguistic features and politeness/hedging markers where available. We train a classifier with a time-based split and perform SHAP-based analyses, which indicate that patient and clinician history features dominate prediction, functioning as strong priors, while characteristics of the response text provide a smaller but, crucially, actionable signal. In subgroup correlation analyses, politeness and hedging are consistently positively associated with patient feedback, whereas lexical diversity shows a negative association.
Automatic Prompt Optimization for Dataset-Level Feature Discovery
Jan 20, 2026Feature extraction from unstructured text is a critical step in many downstream classification pipelines, yet current approaches largely rely on hand-crafted prompts or fixed feature schemas. We formulate feature discovery as a dataset-level prompt optimization problem: given a labelled text corpus, the goal is to induce a global set of interpretable and discriminative feature definitions whose realizations optimize a downstream supervised learning objective. To this end, we propose a multi-agent prompt optimization framework in which language-model agents jointly propose feature definitions, extract feature values, and evaluate feature quality using dataset-level performance and interpretability feedback. Instruction prompts are iteratively refined based on this structured feedback, enabling optimization over prompts that induce shared feature sets rather than per-example predictions. This formulation departs from prior prompt optimization methods that rely on per-sample supervision and provides a principled mechanism for automatic feature discovery from unstructured text.
Training Language Models with homotokens Leads to Delayed Overfitting
Jan 06, 2026Subword tokenization introduces a computational layer in language models where many distinct token sequences decode to the same surface form and preserve meaning, yet induce different internal computations. Despite this non-uniqueness, language models are typically trained using a single canonical longest-prefix tokenization. We formalize homotokens-alternative valid subword segmentations of the same lexical item-as a strictly meaning-preserving form of data augmentation. We introduce a lightweight training architecture that conditions canonical next-token prediction on sampled homotoken variants via an auxiliary causal encoder and block-causal cross-attention, without modifying the training objective or token interface. In data-constrained pretraining, homotoken augmentation consistently delays overfitting under repeated data exposure and improves generalization across diverse evaluation datasets. In multilingual fine-tuning, we find that the effectiveness of homotokens depends on tokenizer quality: gains are strongest when canonical tokens are highly compressed and diminish when the tokenizer already over-fragments the input. Overall, homotokens provide a simple and modular mechanism for inducing tokenization invariance in language models.
MoME: Estimating Psychological Traits from Gait with Multi-Stage Mixture of Movement Experts
Oct 06, 2025



Gait encodes rich biometric and behavioural information, yet leveraging the manner of walking to infer psychological traits remains a challenging and underexplored problem. We introduce a hierarchical Multi-Stage Mixture of Movement Experts (MoME) architecture for multi-task prediction of psychological attributes from gait sequences represented as 2D poses. MoME processes the walking cycle in four stages of movement complexity, employing lightweight expert models to extract spatio-temporal features and task-specific gating modules to adaptively weight experts across traits and stages. Evaluated on the PsyMo benchmark covering 17 psychological traits, our method outperforms state-of-the-art gait analysis models, achieving a 37.47% weighted F1 score at the run level and 44.6% at the subject level. Our experiments show that integrating auxiliary tasks such as identity recognition, gender prediction, and BMI estimation further improves psychological trait estimation. Our findings demonstrate the viability of multi-task gait-based learning for psychological trait estimation and provide a foundation for future research on movement-informed psychological inference.
The Strawberry Problem: Emergence of Character-level Understanding in Tokenized Language Models
May 21, 2025Despite their remarkable progress across diverse domains, Large Language Models (LLMs) consistently fail at simple character-level tasks, such as counting letters in words, due to a fundamental limitation: tokenization. In this work, we frame this limitation as a problem of low mutual information and analyze it in terms of concept emergence. Using a suite of 19 synthetic tasks that isolate character-level reasoning in a controlled setting, we show that such capabilities emerge slowly, suddenly, and only late in training. We further show that percolation-based models of concept emergence explain these patterns, suggesting that learning character composition is not fundamentally different from learning commonsense knowledge. To address this bottleneck, we propose a lightweight architectural modification that significantly improves character-level reasoning while preserving the inductive advantages of subword models. Together, our results bridge low-level perceptual gaps in tokenized LMs and provide a principled framework for understanding and mitigating their structural blind spots. We make our code publicly available.
Database-Agnostic Gait Enrollment using SetTransformers
May 05, 2025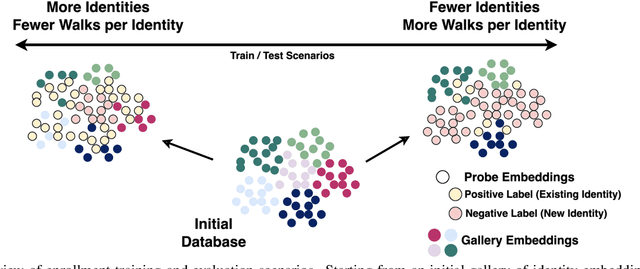



Gait recognition has emerged as a powerful tool for unobtrusive and long-range identity analysis, with growing relevance in surveillance and monitoring applications. Although recent advances in deep learning and large-scale datasets have enabled highly accurate recognition under closed-set conditions, real-world deployment demands open-set gait enrollment, which means determining whether a new gait sample corresponds to a known identity or represents a previously unseen individual. In this work, we introduce a transformer-based framework for open-set gait enrollment that is both dataset-agnostic and recognition-architecture-agnostic. Our method leverages a SetTransformer to make enrollment decisions based on the embedding of a probe sample and a context set drawn from the gallery, without requiring task-specific thresholds or retraining for new environments. By decoupling enrollment from the main recognition pipeline, our model is generalized across different datasets, gallery sizes, and identity distributions. We propose an evaluation protocol that uses existing datasets in different ratios of identities and walks per identity. We instantiate our method using skeleton-based gait representations and evaluate it on two benchmark datasets (CASIA-B and PsyMo), using embeddings from three state-of-the-art recognition models (GaitGraph, GaitFormer, and GaitPT). We show that our method is flexible, is able to accurately perform enrollment in different scenarios, and scales better with data compared to traditional approaches. We will make the code and dataset scenarios publicly available.
On Model and Data Scaling for Skeleton-based Self-Supervised Gait Recognition
Apr 10, 2025Gait recognition from video streams is a challenging problem in computer vision biometrics due to the subtle differences between gaits and numerous confounding factors. Recent advancements in self-supervised pretraining have led to the development of robust gait recognition models that are invariant to walking covariates. While neural scaling laws have transformed model development in other domains by linking performance to data, model size, and compute, their applicability to gait remains unexplored. In this work, we conduct the first empirical study scaling on skeleton-based self-supervised gait recognition to quantify the effect of data quantity, model size and compute on downstream gait recognition performance. We pretrain multiple variants of GaitPT - a transformer-based architecture - on a dataset of 2.7 million walking sequences collected in the wild. We evaluate zero-shot performance across four benchmark datasets to derive scaling laws for data, model size, and compute. Our findings demonstrate predictable power-law improvements in performance with increased scale and confirm that data and compute scaling significantly influence downstream accuracy. We further isolate architectural contributions by comparing GaitPT with GaitFormer under controlled compute budgets. These results provide practical insights into resource allocation and performance estimation for real-world gait recognition systems.
A Retrieval-Based Approach to Medical Procedure Matching in Romanian
Mar 26, 2025Accurately mapping medical procedure names from healthcare providers to standardized terminology used by insurance companies is a crucial yet complex task. Inconsistencies in naming conventions lead to missclasified procedures, causing administrative inefficiencies and insurance claim problems in private healthcare settings. Many companies still use human resources for manual mapping, while there is a clear opportunity for automation. This paper proposes a retrieval-based architecture leveraging sentence embeddings for medical name matching in the Romanian healthcare system. This challenge is significantly more difficult in underrepresented languages such as Romanian, where existing pretrained language models lack domain-specific adaptation to medical text. We evaluate multiple embedding models, including Romanian, multilingual, and medical-domain-specific representations, to identify the most effective solution for this task. Our findings contribute to the broader field of medical NLP for low-resource languages such as Romanian.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.