 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes a Good Doctor Response? An Analysis on a Romanian Telemedicine Platform
Feb 19, 2026Text-based telemedicine has become a common mode of care, requiring clinicians to deliver medical advice clearly and effectively in writing. As platforms increasingly rely on patient ratings and feedback, clinicians face growing pressure to maintain satisfaction scores, even though these evaluations often reflect communication quality more than clinical accuracy. We analyse patient satisfaction signals in Romanian text-based telemedicine. Using a sample of 77,334 anonymised patient question--doctor response pairs, we model feedback as a binary outcome, treating thumbs-up responses as positive and grouping negative or absent feedback into the other class. We extract interpretable, predominantly language-agnostic features (e.g., length, structural characteristics, readability proxies), along with Romanian LIWC psycholinguistic features and politeness/hedging markers where available. We train a classifier with a time-based split and perform SHAP-based analyses, which indicate that patient and clinician history features dominate prediction, functioning as strong priors, while characteristics of the response text provide a smaller but, crucially, actionable signal. In subgroup correlation analyses, politeness and hedging are consistently positively associated with patient feedback, whereas lexical diversity shows a negative association.
Training Language Models with homotokens Leads to Delayed Overfitting
Jan 06, 2026Subword tokenization introduces a computational layer in language models where many distinct token sequences decode to the same surface form and preserve meaning, yet induce different internal computations. Despite this non-uniqueness, language models are typically trained using a single canonical longest-prefix tokenization. We formalize homotokens-alternative valid subword segmentations of the same lexical item-as a strictly meaning-preserving form of data augmentation. We introduce a lightweight training architecture that conditions canonical next-token prediction on sampled homotoken variants via an auxiliary causal encoder and block-causal cross-attention, without modifying the training objective or token interface. In data-constrained pretraining, homotoken augmentation consistently delays overfitting under repeated data exposure and improves generalization across diverse evaluation datasets. In multilingual fine-tuning, we find that the effectiveness of homotokens depends on tokenizer quality: gains are strongest when canonical tokens are highly compressed and diminish when the tokenizer already over-fragments the input. Overall, homotokens provide a simple and modular mechanism for inducing tokenization invariance in language models.
The Strawberry Problem: Emergence of Character-level Understanding in Tokenized Language Models
May 21, 2025Despite their remarkable progress across diverse domains, Large Language Models (LLMs) consistently fail at simple character-level tasks, such as counting letters in words, due to a fundamental limitation: tokenization. In this work, we frame this limitation as a problem of low mutual information and analyze it in terms of concept emergence. Using a suite of 19 synthetic tasks that isolate character-level reasoning in a controlled setting, we show that such capabilities emerge slowly, suddenly, and only late in training. We further show that percolation-based models of concept emergence explain these patterns, suggesting that learning character composition is not fundamentally different from learning commonsense knowledge. To address this bottleneck, we propose a lightweight architectural modification that significantly improves character-level reasoning while preserving the inductive advantages of subword models. Together, our results bridge low-level perceptual gaps in tokenized LMs and provide a principled framework for understanding and mitigating their structural blind spots. We make our code publicly available.
A Retrieval-Based Approach to Medical Procedure Matching in Romanian
Mar 26, 2025Accurately mapping medical procedure names from healthcare providers to standardized terminology used by insurance companies is a crucial yet complex task. Inconsistencies in naming conventions lead to missclasified procedures, causing administrative inefficiencies and insurance claim problems in private healthcare settings. Many companies still use human resources for manual mapping, while there is a clear opportunity for automation. This paper proposes a retrieval-based architecture leveraging sentence embeddings for medical name matching in the Romanian healthcare system. This challenge is significantly more difficult in underrepresented languages such as Romanian, where existing pretrained language models lack domain-specific adaptation to medical text. We evaluate multiple embedding models, including Romanian, multilingual, and medical-domain-specific representations, to identify the most effective solution for this task. Our findings contribute to the broader field of medical NLP for low-resource languages such as Romanian.
RoMath: A Mathematical Reasoning Benchmark in Romanian
Sep 17, 2024



Mathematics has long been conveyed through natural language, primarily for human understanding. With the rise of mechanized mathematics and proof assistants, there is a growing need to understand informal mathematical text, yet most existing benchmarks focus solely on English, overlooking other languages. This paper introduces RoMath, a Romanian mathematical reasoning benchmark suite comprising three datasets: RoMath-Baccalaureate, RoMath-Competitions and RoMath-Synthetic, which cover a range of mathematical domains and difficulty levels, aiming to improve non-English language models and promote multilingual AI development. By focusing on Romanian, a low-resource language with unique linguistic features, RoMath addresses the limitations of Anglo-centric models and emphasizes the need for dedicated resources beyond simple automatic translation. We benchmark several open-weight language models, highlighting the importance of creating resources for underrepresented languages. We make the code and dataset available.
Aligning Actions and Walking to LLM-Generated Textual Descriptions
Apr 18, 2024



Large Language Models (LLMs) have demonstrated remarkable capabilities in various domains, including data augmentation and synthetic data generation. This work explores the use of LLMs to generate rich textual descriptions for motion sequences, encompassing both actions and walking patterns. We leverage the expressive power of LLMs to align motion representations with high-level linguistic cues, addressing two distinct tasks: action recognition and retrieval of walking sequences based on appearance attributes. For action recognition, we employ LLMs to generate textual descriptions of actions in the BABEL-60 dataset, facilitating the alignment of motion sequences with linguistic representations. In the domain of gait analysis, we investigate the impact of appearance attributes on walking patterns by generating textual descriptions of motion sequences from the DenseGait dataset using LLMs. These descriptions capture subtle variations in walking styles influenced by factors such as clothing choices and footwear. Our approach demonstrates the potential of LLMs in augmenting structured motion attributes and aligning multi-modal representations. The findings contribute to the advancement of comprehensive motion understanding and open up new avenues for leveraging LLMs in multi-modal alignment and data augmentation for motion analysis. We make the code publicly available at https://github.com/Radu1999/WalkAndText
Gait Recognition from Highly Compressed Videos
Apr 18, 2024Surveillance footage represents a valuable resource and opportunities for conducting gait analysis. However, the typical low quality and high noise levels in such footage can severely impact the accuracy of pose estimation algorithms, which are foundational for reliable gait analysis. Existing literature suggests a direct correlation between the efficacy of pose estimation and the subsequent gait analysis results. A common mitigation strategy involves fine-tuning pose estimation models on noisy data to improve robustness. However, this approach may degrade the downstream model's performance on the original high-quality data, leading to a trade-off that is undesirable in practice. We propose a processing pipeline that incorporates a task-targeted artifact correction model specifically designed to pre-process and enhance surveillance footage before pose estimation. Our artifact correction model is optimized to work alongside a state-of-the-art pose estimation network, HRNet, without requiring repeated fine-tuning of the pose estimation model. Furthermore, we propose a simple and robust method for obtaining low quality videos that are annotated with poses in an automatic manner with the purpose of training the artifact correction model. We systematically evaluate the performance of our artifact correction model against a range of noisy surveillance data and demonstrate that our approach not only achieves improved pose estimation on low-quality surveillance footage, but also preserves the integrity of the pose estimation on high resolution footage. Our experiments show a clear enhancement in gait analysis performance, supporting the viability of the proposed method as a superior alternative to direct fine-tuning strategies. Our contributions pave the way for more reliable gait analysis using surveillance data in real-world applications, regardless of data quality.
GaitFormer: Learning Gait Representations with Noisy Multi-Task Learning
Oct 30, 2023Gait analysis is proven to be a reliable way to perform person identification without relying on subject cooperation. Walking is a biometric that does not significantly change in short periods of time and can be regarded as unique to each person. So far, the study of gait analysis focused mostly on identification and demographics estimation, without considering many of the pedestrian attributes that appearance-based methods rely on. In this work, alongside gait-based person identification, we explore pedestrian attribute identification solely from movement patterns. We propose DenseGait, the largest dataset for pretraining gait analysis systems containing 217K anonymized tracklets, annotated automatically with 42 appearance attributes. DenseGait is constructed by automatically processing video streams and offers the full array of gait covariates present in the real world. We make the dataset available to the research community. Additionally, we propose GaitFormer, a transformer-based model that after pretraining in a multi-task fashion on DenseGait, achieves 92.5% accuracy on CASIA-B and 85.33% on FVG, without utilizing any manually annotated data. This corresponds to a +14.2% and +9.67% accuracy increase compared to similar methods. Moreover, GaitFormer is able to accurately identify gender information and a multitude of appearance attributes utilizing only movement patterns. The code to reproduce the experiments is made publicly.
Learning to Simplify Spatial-Temporal Graphs in Gait Analysis
Oct 05, 2023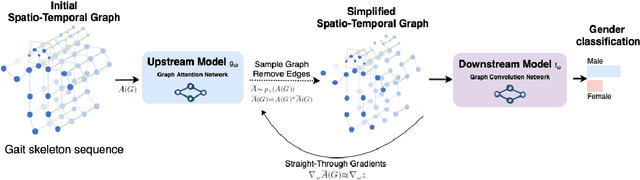
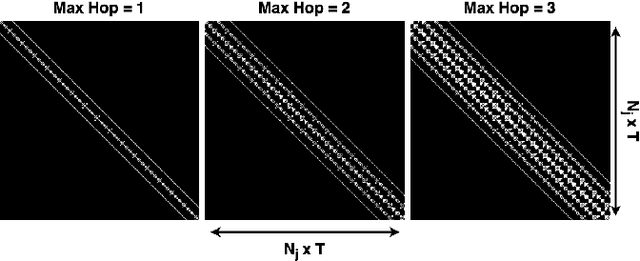
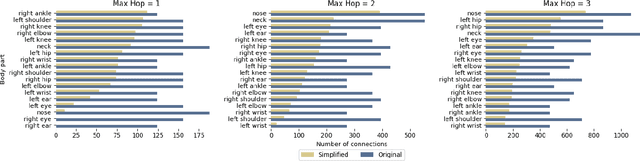
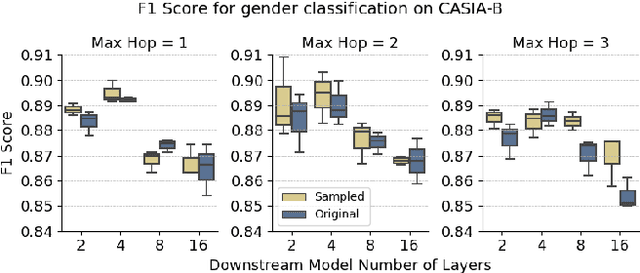
Gait analysis leverages unique walking patterns for person identification and assessment across multiple domains. Among the methods used for gait analysis, skeleton-based approaches have shown promise due to their robust and interpretable features. However, these methods often rely on hand-crafted spatial-temporal graphs that are based on human anatomy disregarding the particularities of the dataset and task. This paper proposes a novel method to simplify the spatial-temporal graph representation for gait-based gender estimation, improving interpretability without losing performance. Our approach employs two models, an upstream and a downstream model, that can adjust the adjacency matrix for each walking instance, thereby removing the fixed nature of the graph. By employing the Straight-Through Gumbel-Softmax trick, our model is trainable end-to-end. We demonstrate the effectiveness of our approach on the CASIA-B dataset for gait-based gender estimation. The resulting graphs are interpretable and differ qualitatively from fixed graphs used in existing models. Our research contributes to enhancing the explainability and task-specific adaptability of gait recognition, promoting more efficient and reliable gait-based biometrics.
PsyMo: A Dataset for Estimating Self-Reported Psychological Traits from Gait
Aug 21, 2023Psychological trait estimation from external factors such as movement and appearance is a challenging and long-standing problem in psychology, and is principally based on the psychological theory of embodiment. To date, attempts to tackle this problem have utilized private small-scale datasets with intrusive body-attached sensors. Potential applications of an automated system for psychological trait estimation include estimation of occupational fatigue and psychology, and marketing and advertisement. In this work, we propose PsyMo (Psychological traits from Motion), a novel, multi-purpose and multi-modal dataset for exploring psychological cues manifested in walking patterns. We gathered walking sequences from 312 subjects in 7 different walking variations and 6 camera angles. In conjunction with walking sequences, participants filled in 6 psychological questionnaires, totalling 17 psychometric attributes related to personality, self-esteem, fatigue, aggressiveness and mental health. We propose two evaluation protocols for psychological trait estimation. Alongside the estimation of self-reported psychological traits from gait, the dataset can be used as a drop-in replacement to benchmark methods for gait recognition. We anonymize all cues related to the identity of the subjects and publicly release only silhouettes, 2D / 3D human skeletons and 3D SMPL human meshes.