 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue-Aware Numerical Representations for Transformer Language Models
Jan 14, 2026Transformer-based language models often achieve strong results on mathematical reasoning benchmarks while remaining fragile on basic numerical understanding and arithmetic operations. A central limitation is that numbers are processed as symbolic tokens whose embeddings do not explicitly encode numerical value, leading to systematic errors. We introduce a value-aware numerical representation that augments standard tokenized inputs with a dedicated prefix token whose embedding is explicitly conditioned on the underlying numerical value. This mechanism injects magnitude information directly into the model's input space while remaining compatible with existing tokenizers and decoder-only Transformer architectures. Evaluation on arithmetic tasks shows that the proposed approach outperforms baselines across numerical formats, tasks, and operand lengths. These results indicate that explicitly encoding numerical value is an effective and efficient way to improve fundamental numerical robustness in language models.
Training Language Models with homotokens Leads to Delayed Overfitting
Jan 06, 2026Subword tokenization introduces a computational layer in language models where many distinct token sequences decode to the same surface form and preserve meaning, yet induce different internal computations. Despite this non-uniqueness, language models are typically trained using a single canonical longest-prefix tokenization. We formalize homotokens-alternative valid subword segmentations of the same lexical item-as a strictly meaning-preserving form of data augmentation. We introduce a lightweight training architecture that conditions canonical next-token prediction on sampled homotoken variants via an auxiliary causal encoder and block-causal cross-attention, without modifying the training objective or token interface. In data-constrained pretraining, homotoken augmentation consistently delays overfitting under repeated data exposure and improves generalization across diverse evaluation datasets. In multilingual fine-tuning, we find that the effectiveness of homotokens depends on tokenizer quality: gains are strongest when canonical tokens are highly compressed and diminish when the tokenizer already over-fragments the input. Overall, homotokens provide a simple and modular mechanism for inducing tokenization invariance in language models.
The Strawberry Problem: Emergence of Character-level Understanding in Tokenized Language Models
May 21, 2025Despite their remarkable progress across diverse domains, Large Language Models (LLMs) consistently fail at simple character-level tasks, such as counting letters in words, due to a fundamental limitation: tokenization. In this work, we frame this limitation as a problem of low mutual information and analyze it in terms of concept emergence. Using a suite of 19 synthetic tasks that isolate character-level reasoning in a controlled setting, we show that such capabilities emerge slowly, suddenly, and only late in training. We further show that percolation-based models of concept emergence explain these patterns, suggesting that learning character composition is not fundamentally different from learning commonsense knowledge. To address this bottleneck, we propose a lightweight architectural modification that significantly improves character-level reasoning while preserving the inductive advantages of subword models. Together, our results bridge low-level perceptual gaps in tokenized LMs and provide a principled framework for understanding and mitigating their structural blind spots. We make our code publicly available.
How Hard is this Test Set? NLI Characterization by Exploiting Training Dynamics
Oct 04, 2024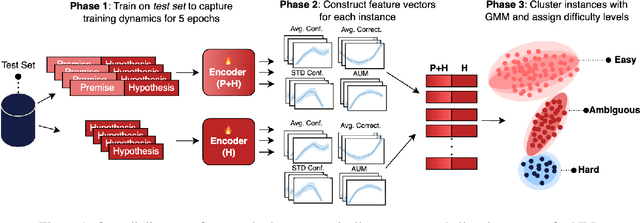
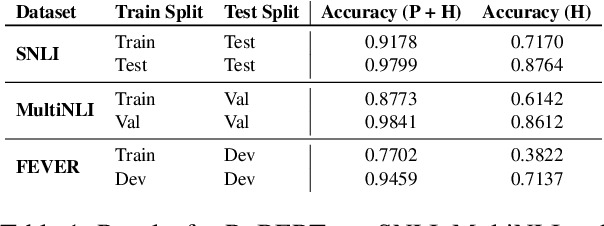

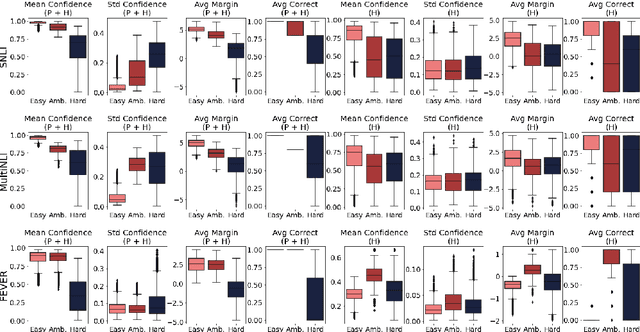
Natural Language Inference (NLI) evaluation is crucial for assessing language understanding models; however, popular datasets suffer from systematic spurious correlations that artificially inflate actual model performance. To address this, we propose a method for the automated creation of a challenging test set without relying on the manual construction of artificial and unrealistic examples. We categorize the test set of popular NLI datasets into three difficulty levels by leveraging methods that exploit training dynamics. This categorization significantly reduces spurious correlation measures, with examples labeled as having the highest difficulty showing markedly decreased performance and encompassing more realistic and diverse linguistic phenomena. When our characterization method is applied to the training set, models trained with only a fraction of the data achieve comparable performance to those trained on the full dataset, surpassing other dataset characterization techniques. Our research addresses limitations in NLI dataset construction, providing a more authentic evaluation of model performance with implications for diverse NLU applications.
"Vorbeşti Româneşte?" A Recipe to Train Powerful Romanian LLMs with English Instructions
Jun 26, 2024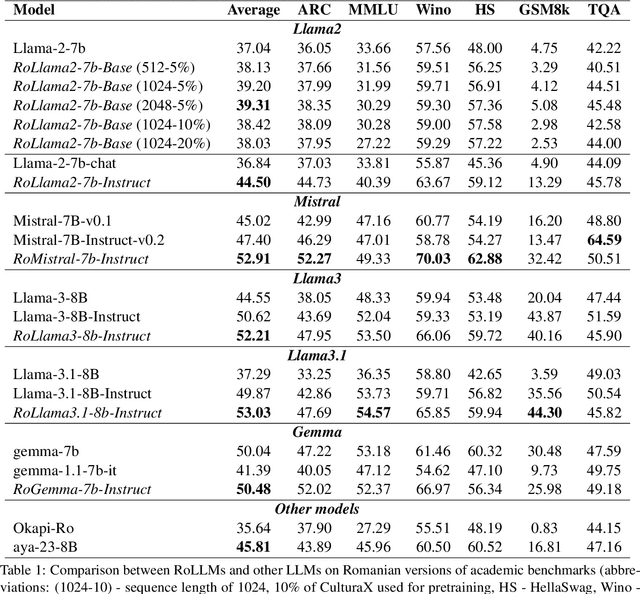
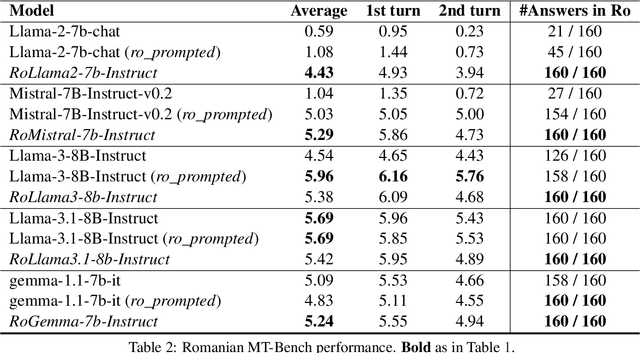
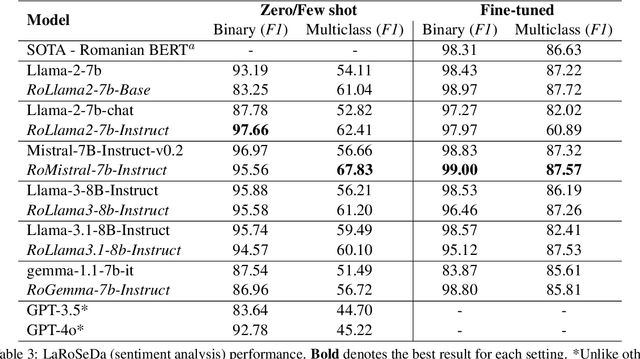
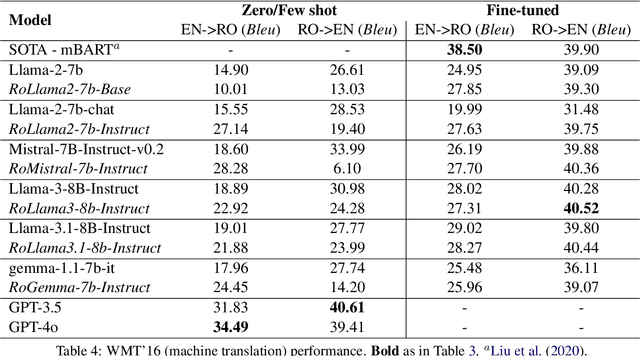
In recent years, Large Language Models (LLMs) have achieved almost human-like performance on various tasks. While some LLMs have been trained on multilingual data, most of the training data is in English; hence, their performance in English greatly exceeds other languages. To our knowledge, we are the first to collect and translate a large collection of texts, instructions, and benchmarks and train, evaluate, and release open-source LLMs tailored for Romanian. We evaluate our methods on four different categories, including academic benchmarks, MT-Bench (manually translated), and a professionally built historical, cultural, and social benchmark adapted to Romanian. We argue for the usefulness and high performance of RoLLMs by obtaining state-of-the-art results across the board. We publicly release all resources (i.e., data, training and evaluation code, models) to support and encourage research on Romanian LLMs while concurrently creating a generalizable recipe, adequate for other low or less-resourced languages.
OpenLLM-Ro -- Technical Report on Open-source Romanian LLMs
May 17, 2024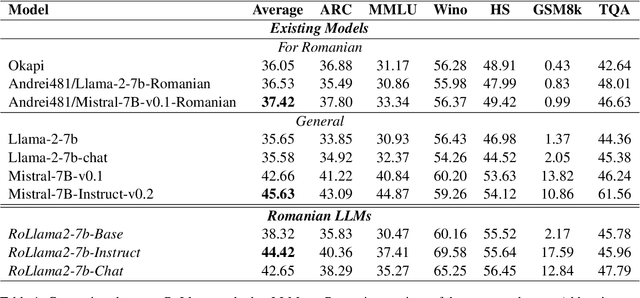

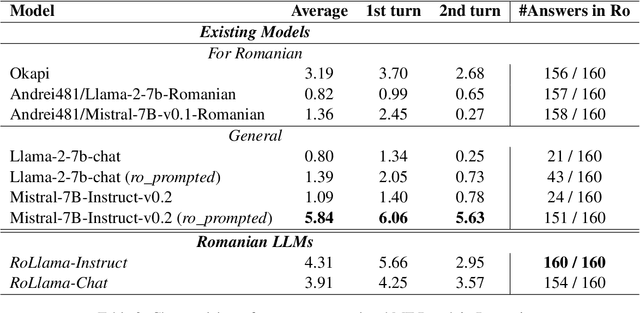
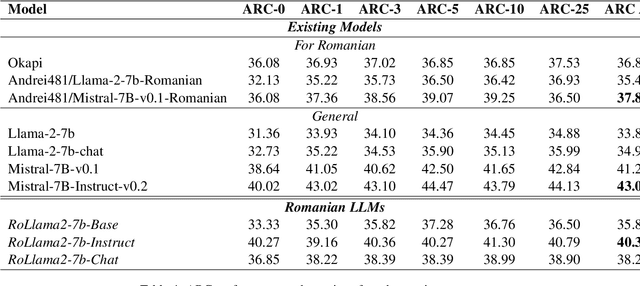
In recent years, Large Language Models (LLMs) have achieved almost human-like performance on various tasks. While some LLMs have been trained on multilingual data, most of the training data is in English. Hence, their performance in English greatly exceeds their performance in other languages. This document presents our approach to training and evaluating the first foundational and chat LLM specialized for Romanian.
UPB @ ACTI: Detecting Conspiracies using fine tuned Sentence Transformers
Sep 28, 2023Conspiracy theories have become a prominent and concerning aspect of online discourse, posing challenges to information integrity and societal trust. As such, we address conspiracy theory detection as proposed by the ACTI @ EVALITA 2023 shared task. The combination of pre-trained sentence Transformer models and data augmentation techniques enabled us to secure first place in the final leaderboard of both sub-tasks. Our methodology attained F1 scores of 85.71% in the binary classification and 91.23% for the fine-grained conspiracy topic classification, surpassing other competing systems.
UPB at SemEval-2022 Task 5: Enhancing UNITER with Image Sentiment and Graph Convolutional Networks for Multimedia Automatic Misogyny Identification
May 29, 2022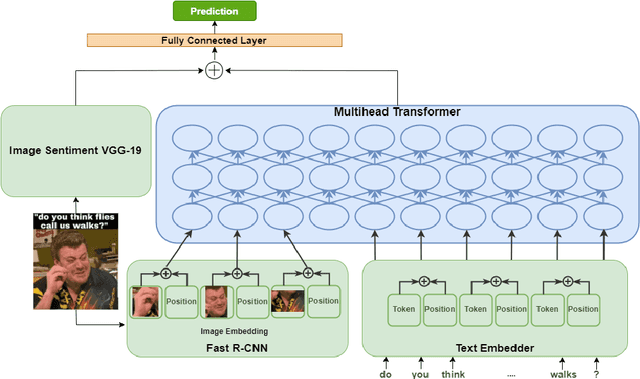
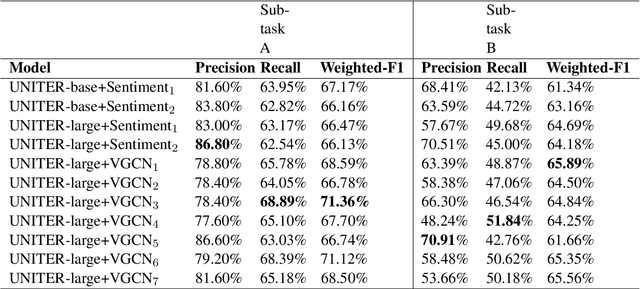
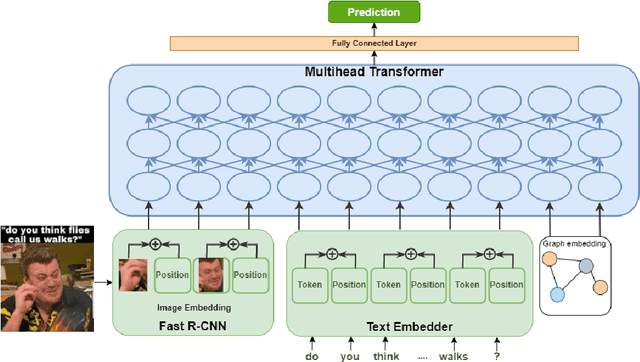
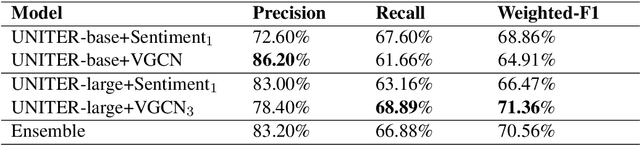
In recent times, the detection of hate-speech, offensive, or abusive language in online media has become an important topic in NLP research due to the exponential growth of social media and the propagation of such messages, as well as their impact. Misogyny detection, even though it plays an important part in hate-speech detection, has not received the same attention. In this paper, we describe our classification systems submitted to the SemEval-2022 Task 5: MAMI - Multimedia Automatic Misogyny Identification. The shared task aimed to identify misogynous content in a multi-modal setting by analysing meme images together with their textual captions. To this end, we propose two models based on the pre-trained UNITER model, one enhanced with an image sentiment classifier, whereas the second leverages a Vocabulary Graph Convolutional Network (VGCN). Additionally, we explore an ensemble using the aforementioned models. Our best model reaches an F1-score of 71.4% in Sub-task A and 67.3% for Sub-task B positioning our team in the upper third of the leaderboard. We release the code and experiments for our models on GitHub
Domain Adaptation in Multilingual and Multi-Domain Monolingual Settings for Complex Word Identification
May 15, 2022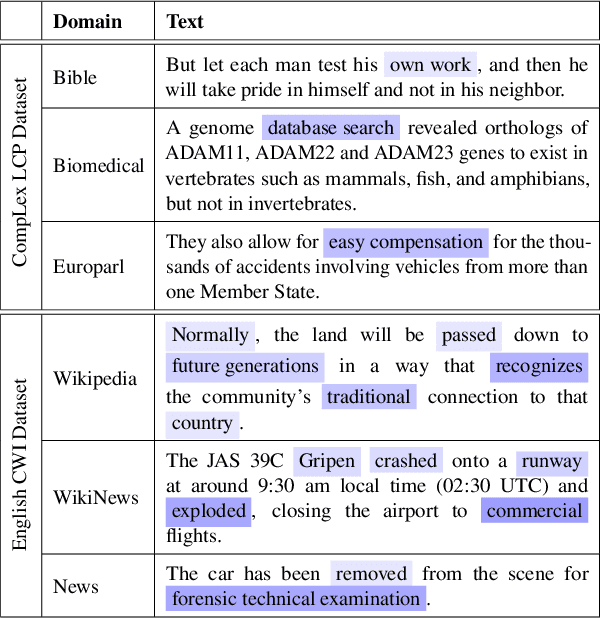
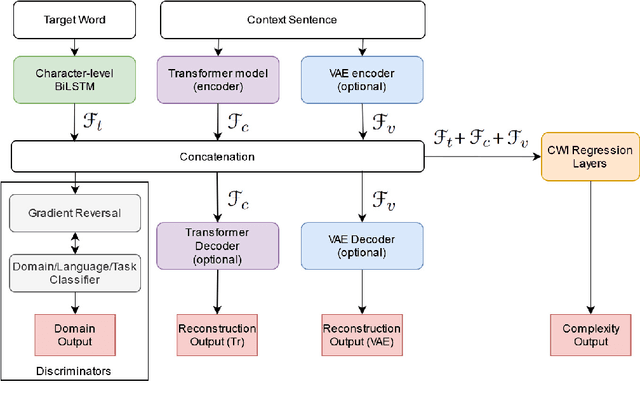
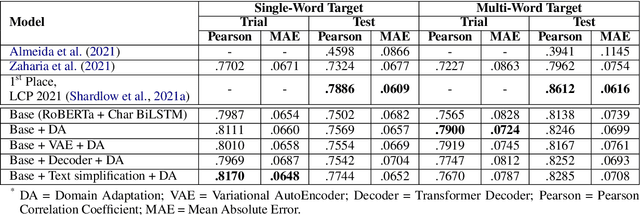
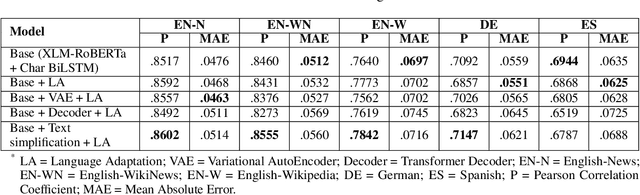
Complex word identification (CWI) is a cornerstone process towards proper text simplification. CWI is highly dependent on context, whereas its difficulty is augmented by the scarcity of available datasets which vary greatly in terms of domains and languages. As such, it becomes increasingly more difficult to develop a robust model that generalizes across a wide array of input examples. In this paper, we propose a novel training technique for the CWI task based on domain adaptation to improve the target character and context representations. This technique addresses the problem of working with multiple domains, inasmuch as it creates a way of smoothing the differences between the explored datasets. Moreover, we also propose a similar auxiliary task, namely text simplification, that can be used to complement lexical complexity prediction. Our model obtains a boost of up to 2.42% in terms of Pearson Correlation Coefficients in contrast to vanilla training techniques, when considering the CompLex from the Lexical Complexity Prediction 2021 dataset. At the same time, we obtain an increase of 3% in Pearson scores, while considering a cross-lingual setup relying on the Complex Word Identification 2018 dataset. In addition, our model yields state-of-the-art results in terms of Mean Absolute Error.
UPB at SemEval-2021 Task 5: Virtual Adversarial Training for Toxic Spans Detection
Apr 17, 2021
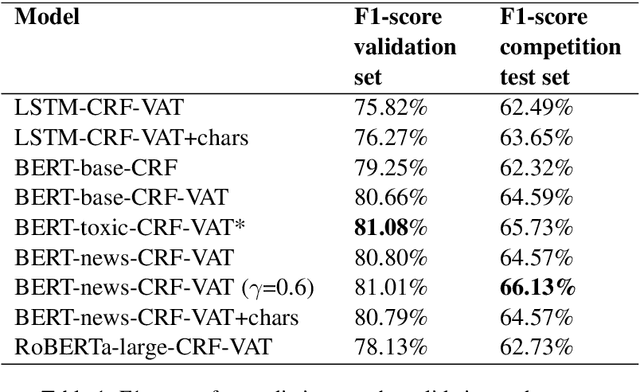
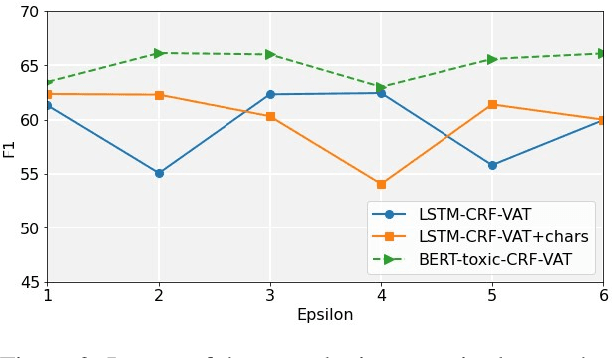

The real-world impact of polarization and toxicity in the online sphere marked the end of 2020 and the beginning of this year in a negative way. Semeval-2021, Task 5 - Toxic Spans Detection is based on a novel annotation of a subset of the Jigsaw Unintended Bias dataset and is the first language toxicity detection task dedicated to identifying the toxicity-level spans. For this task, participants had to automatically detect character spans in short comments that render the message as toxic. Our model considers applying Virtual Adversarial Training in a semi-supervised setting during the fine-tuning process of several Transformer-based models (i.e., BERT and RoBERTa), in combination with Conditional Random Fields. Our approach leads to performance improvements and more robust models, enabling us to achieve an F1-score of 65.73% in the official submission and an F1-score of 66.13% after further tuning during post-evaluation.