 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation in Multilingual and Multi-Domain Monolingual Settings for Complex Word Identification
May 15, 2022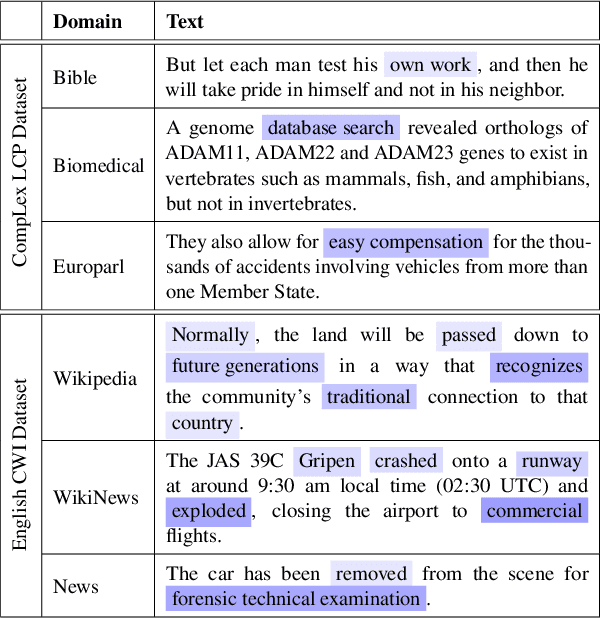
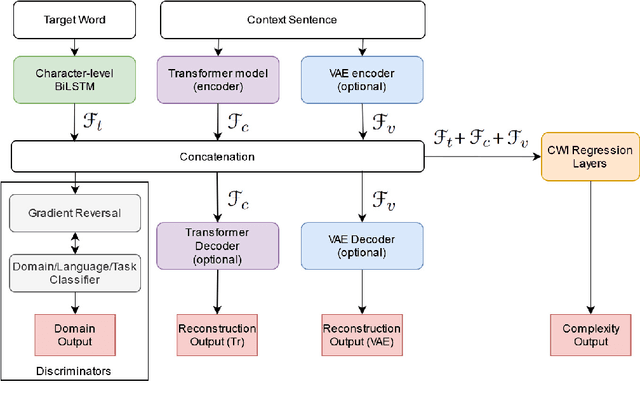
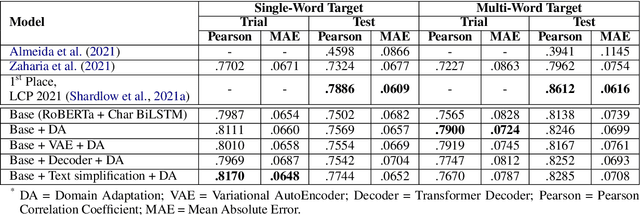
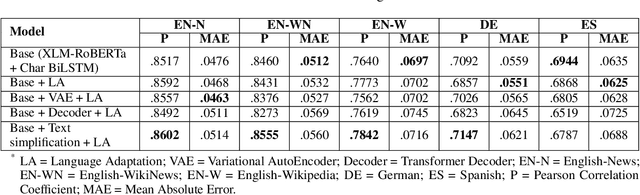
Complex word identification (CWI) is a cornerstone process towards proper text simplification. CWI is highly dependent on context, whereas its difficulty is augmented by the scarcity of available datasets which vary greatly in terms of domains and languages. As such, it becomes increasingly more difficult to develop a robust model that generalizes across a wide array of input examples. In this paper, we propose a novel training technique for the CWI task based on domain adaptation to improve the target character and context representations. This technique addresses the problem of working with multiple domains, inasmuch as it creates a way of smoothing the differences between the explored datasets. Moreover, we also propose a similar auxiliary task, namely text simplification, that can be used to complement lexical complexity prediction. Our model obtains a boost of up to 2.42% in terms of Pearson Correlation Coefficients in contrast to vanilla training techniques, when considering the CompLex from the Lexical Complexity Prediction 2021 dataset. At the same time, we obtain an increase of 3% in Pearson scores, while considering a cross-lingual setup relying on the Complex Word Identification 2018 dataset. In addition, our model yields state-of-the-art results in terms of Mean Absolute Error.
UPB at SemEval-2021 Task 1: Combining Deep Learning and Hand-Crafted Features for Lexical Complexity Prediction
Apr 14, 2021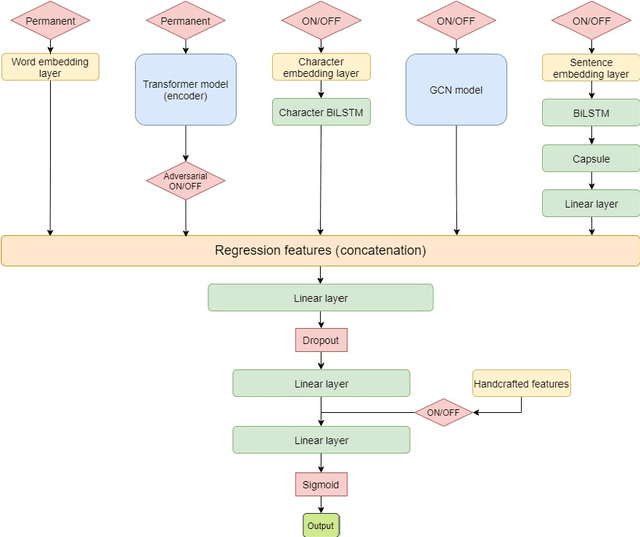

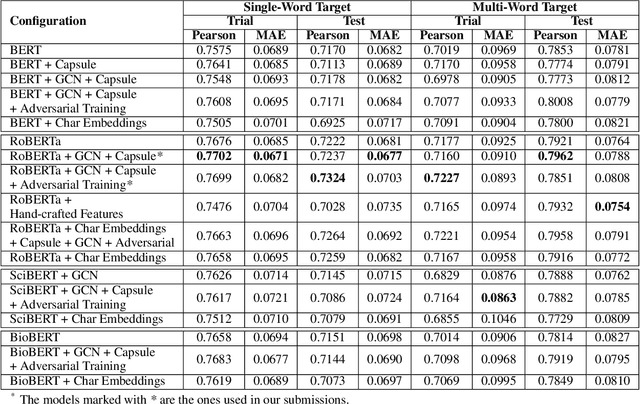

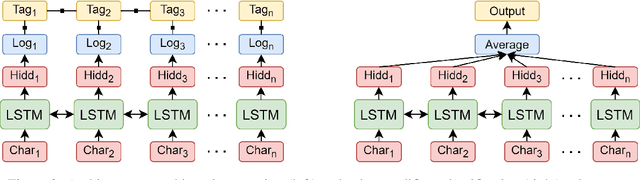
Reading is a complex process which requires proper understanding of texts in order to create coherent mental representations. However, comprehension problems may arise due to hard-to-understand sections, which can prove troublesome for readers, while accounting for their specific language skills. As such, steps towards simplifying these sections can be performed, by accurately identifying and evaluating difficult structures. In this paper, we describe our approach for the SemEval-2021 Task 1: Lexical Complexity Prediction competition that consists of a mixture of advanced NLP techniques, namely Transformer-based language models, pre-trained word embeddings, Graph Convolutional Networks, Capsule Networks, as well as a series of hand-crafted textual complexity features. Our models are applicable on both subtasks and achieve good performance results, with a MAE below 0.07 and a Person correlation of .73 for single word identification, as well as a MAE below 0.08 and a Person correlation of .79 for multiple word targets. Our results are just 5.46% and 6.5% lower than the top scores obtained in the competition on the first and the second subtasks, respectively.
UPB at SemEval-2021 Task 8: Extracting Semantic Information on Measurements as Multi-Turn Question Answering
Apr 09, 2021


Extracting semantic information on measurements and counts is an important topic in terms of analyzing scientific discourses. The 8th task of SemEval-2021: Counts and Measurements (MeasEval) aimed to boost research in this direction by providing a new dataset on which participants train their models to extract meaningful information on measurements from scientific texts. The competition is composed of five subtasks that build on top of each other: (1) quantity span identification, (2) unit extraction from the identified quantities and their value modifier classification, (3) span identification for measured entities and measured properties, (4) qualifier span identification, and (5) relation extraction between the identified quantities, measured entities, measured properties, and qualifiers. We approached these challenges by first identifying the quantities, extracting their units of measurement, classifying them with corresponding modifiers, and afterwards using them to jointly solve the last three subtasks in a multi-turn question answering manner. Our best performing model obtained an overlapping F1-score of 36.91% on the test set.
Cross-Lingual Transfer Learning for Complex Word Identification
Oct 02, 2020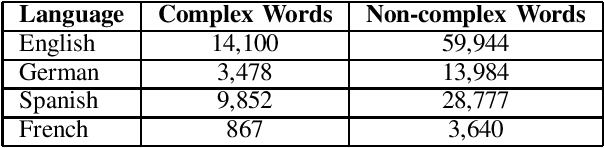
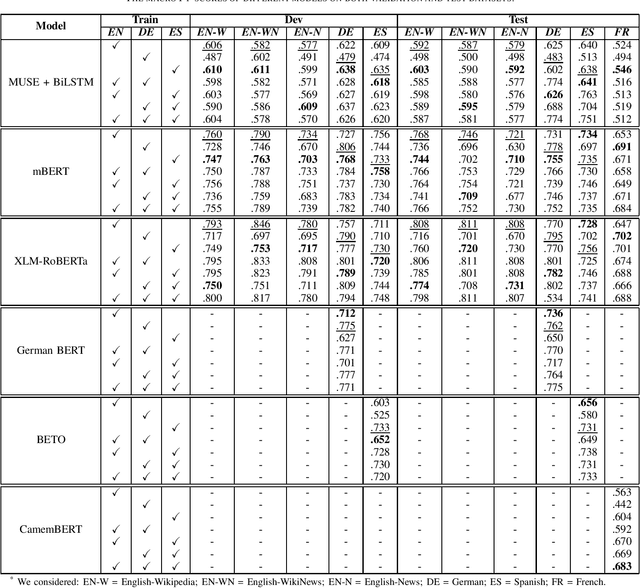
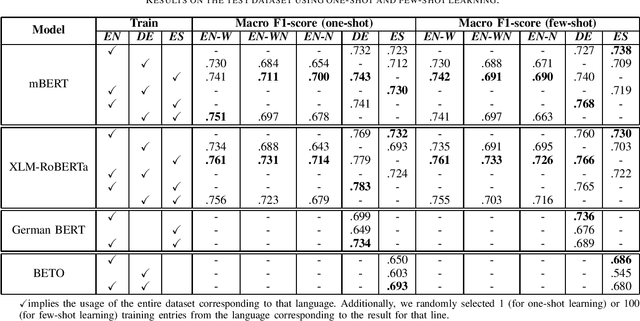
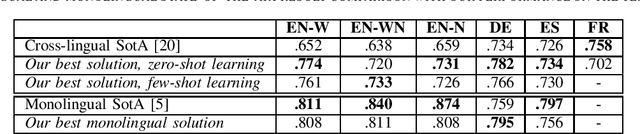
Complex Word Identification (CWI) is a task centered on detecting hard-to-understand words, or groups of words, in texts from different areas of expertise. The purpose of CWI is to highlight problematic structures that non-native speakers would usually find difficult to understand. Our approach uses zero-shot, one-shot, and few-shot learning techniques, alongside state-of-the-art solutions for Natural Language Processing (NLP) tasks (i.e., Transformers). Our aim is to provide evidence that the proposed models can learn the characteristics of complex words in a multilingual environment by relying on the CWI shared task 2018 dataset available for four different languages (i.e., English, German, Spanish, and also French). Our approach surpasses state-of-the-art cross-lingual results in terms of macro F1-score on English (0.774), German (0.782), and Spanish (0.734) languages, for the zero-shot learning scenario. At the same time, our model also outperforms the state-of-the-art monolingual result for German (0.795 macro F1-score).
UPB at SemEval-2020 Task 9: Identifying Sentiment in Code-Mixed Social Media Texts using Transformers and Multi-Task Learning
Sep 06, 2020
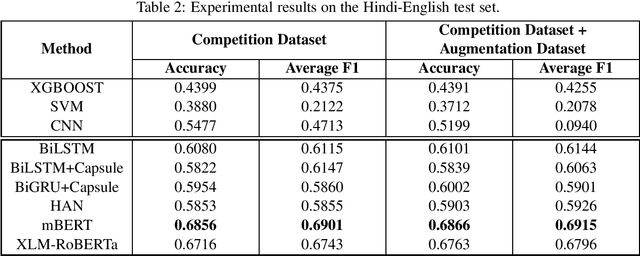


Sentiment analysis is a process widely used in opinion mining campaigns conducted today. This phenomenon presents applications in a variety of fields, especially in collecting information related to the attitude or satisfaction of users concerning a particular subject. However, the task of managing such a process becomes noticeably more difficult when it is applied in cultures that tend to combine two languages in order to express ideas and thoughts. By interleaving words from two languages, the user can express with ease, but at the cost of making the text far less intelligible for those who are not familiar with this technique, but also for standard opinion mining algorithms. In this paper, we describe the systems developed by our team for SemEval-2020 Task 9 that aims to cover two well-known code-mixed languages: Hindi-English and Spanish-English. We intend to solve this issue by introducing a solution that takes advantage of several neural network approaches, as well as pre-trained word embeddings. Our approach (multlingual BERT) achieves promising performance on the Hindi-English task, with an average F1-score of 0.6850, registered on the competition leaderboard, ranking our team 16th out of 62 participants. For the Spanish-English task, we obtained an average F1-score of 0.7064 ranking our team 17th out of 29 participants by using another multilingual Transformer-based model, XLM-RoBERTa.
UPB at SemEval-2020 Task 8: Joint Textual and Visual Modeling in a Multi-Task Learning Architecture for Memotion Analysis
Sep 06, 2020

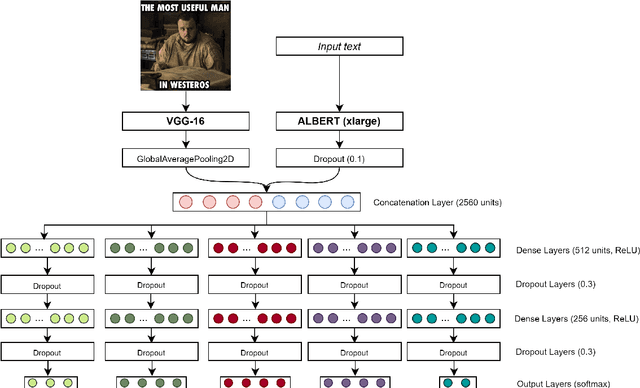

Users from the online environment can create different ways of expressing their thoughts, opinions, or conception of amusement. Internet memes were created specifically for these situations. Their main purpose is to transmit ideas by using combinations of images and texts such that they will create a certain state for the receptor, depending on the message the meme has to send. These posts can be related to various situations or events, thus adding a funny side to any circumstance our world is situated in. In this paper, we describe the system developed by our team for SemEval-2020 Task 8: Memotion Analysis. More specifically, we introduce a novel system to analyze these posts, a multimodal multi-task learning architecture that combines ALBERT for text encoding with VGG-16 for image representation. In this manner, we show that the information behind them can be properly revealed. Our approach achieves good performance on each of the three subtasks of the current competition, ranking 11th for Subtask A (0.3453 macro F1-score), 1st for Subtask B (0.5183 macro F1-score), and 3rd for Subtask C (0.3171 macro F1-score) while exceeding the official baseline results by high margins.