 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuSaRoNews: A Multidomain, Multimodal Satire Dataset from Romanian News Articles
Apr 10, 2025



Satire and fake news can both contribute to the spread of false information, even though both have different purposes (one if for amusement, the other is to misinform). However, it is not enough to rely purely on text to detect the incongruity between the surface meaning and the actual meaning of the news articles, and, often, other sources of information (e.g., visual) provide an important clue for satire detection. This work introduces a multimodal corpus for satire detection in Romanian news articles named MuSaRoNews. Specifically, we gathered 117,834 public news articles from real and satirical news sources, composing the first multimodal corpus for satire detection in the Romanian language. We conducted experiments and showed that the use of both modalities improves performance.
SaRoHead: A Dataset for Satire Detection in Romanian Multi-Domain News Headlines
Apr 10, 2025The headline is an important part of a news article, influenced by expressiveness and connection to the exposed subject. Although most news outlets aim to present reality objectively, some publications prefer a humorous approach in which stylistic elements of satire, irony, and sarcasm blend to cover specific topics. Satire detection can be difficult because a headline aims to expose the main idea behind a news article. In this paper, we propose SaRoHead, the first corpus for satire detection in Romanian multi-domain news headlines. Our findings show that the clickbait used in some non-satirical headlines significantly influences the model.
GRAF: Graph Retrieval Augmented by Facts for Legal Question Answering
Dec 05, 2024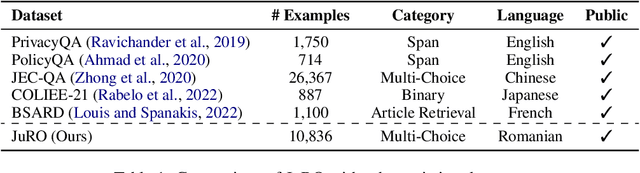
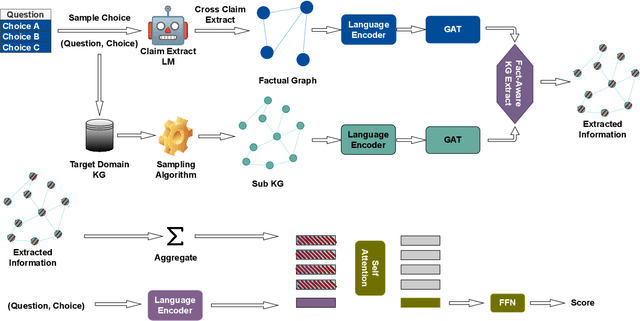

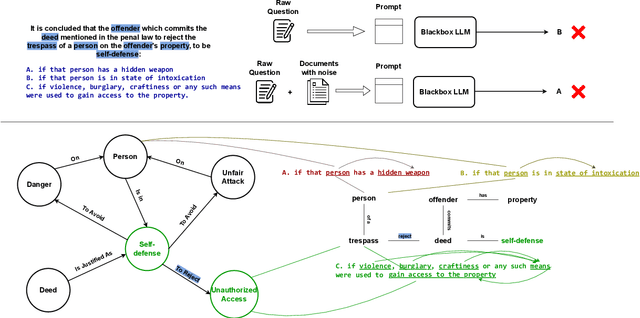
Pre-trained Language Models (PLMs) have shown remarkable performances in recent years, setting a new paradigm for NLP research and industry. The legal domain has received some attention from the NLP community partly due to its textual nature. Some tasks from this domain are represented by question-answering (QA) tasks. This work explores the legal domain Multiple-Choice QA (MCQA) for a low-resource language. The contribution of this work is multi-fold. We first introduce JuRO, the first openly available Romanian legal MCQA dataset, comprising three different examinations and a number of 10,836 total questions. Along with this dataset, we introduce CROL, an organized corpus of laws that has a total of 93 distinct documents with their modifications from 763 time spans, that we leveraged in this work for Information Retrieval (IR) techniques. Moreover, we are the first to propose Law-RoG, a Knowledge Graph (KG) for the Romanian language, and this KG is derived from the aforementioned corpus. Lastly, we propose a novel approach for MCQA, Graph Retrieval Augmented by Facts (GRAF), which achieves competitive results with generally accepted SOTA methods and even exceeds them in most settings.
Investigating Large Language Models for Complex Word Identification in Multilingual and Multidomain Setups
Nov 03, 2024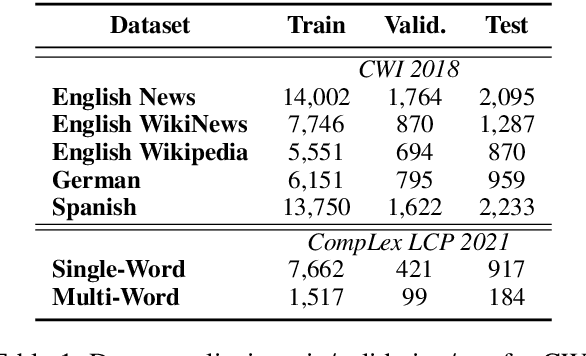
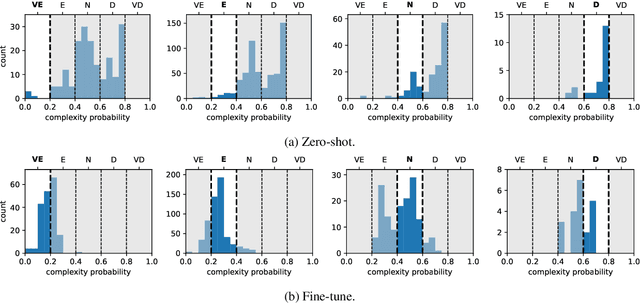
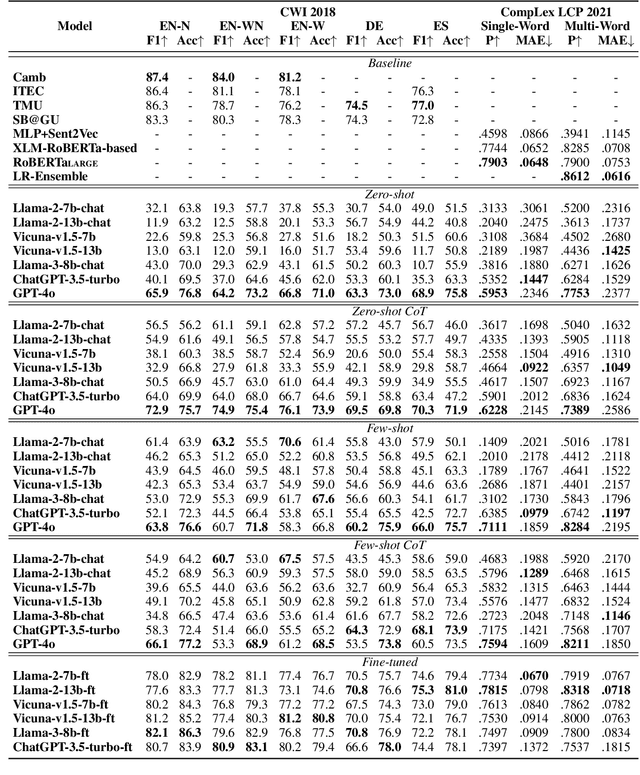
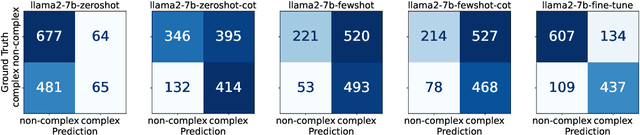
Complex Word Identification (CWI) is an essential step in the lexical simplification task and has recently become a task on its own. Some variations of this binary classification task have emerged, such as lexical complexity prediction (LCP) and complexity evaluation of multi-word expressions (MWE). Large language models (LLMs) recently became popular in the Natural Language Processing community because of their versatility and capability to solve unseen tasks in zero/few-shot settings. Our work investigates LLM usage, specifically open-source models such as Llama 2, Llama 3, and Vicuna v1.5, and closed-source, such as ChatGPT-3.5-turbo and GPT-4o, in the CWI, LCP, and MWE settings. We evaluate zero-shot, few-shot, and fine-tuning settings and show that LLMs struggle in certain conditions or achieve comparable results against existing methods. In addition, we provide some views on meta-learning combined with prompt learning. In the end, we conclude that the current state of LLMs cannot or barely outperform existing methods, which are usually much smaller.
A Cross-Lingual Meta-Learning Method Based on Domain Adaptation for Speech Emotion Recognition
Oct 06, 2024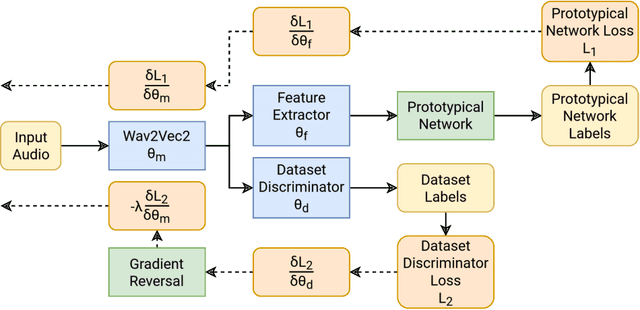
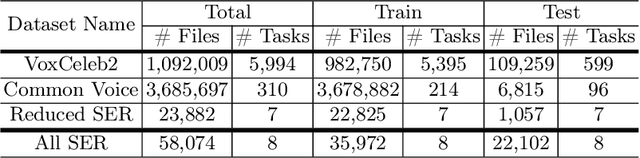
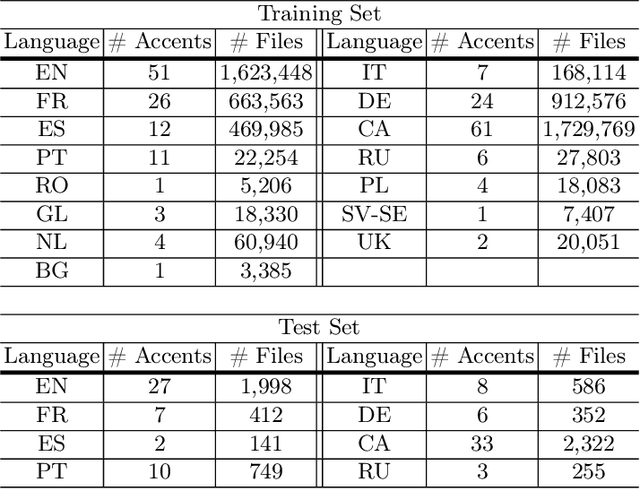
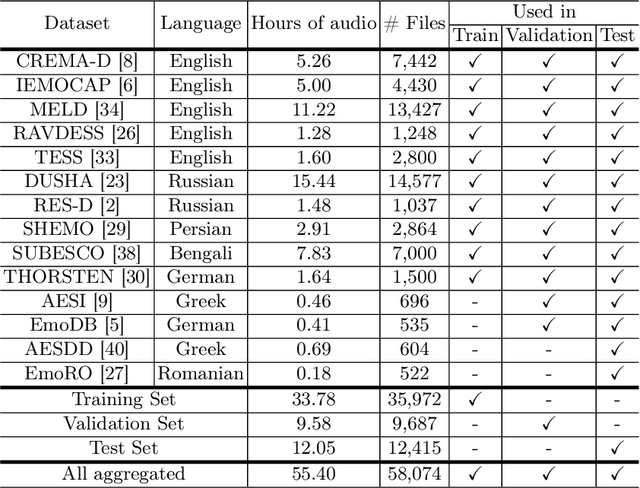
Best-performing speech models are trained on large amounts of data in the language they are meant to work for. However, most languages have sparse data, making training models challenging. This shortage of data is even more prevalent in speech emotion recognition. Our work explores the model's performance in limited data, specifically for speech emotion recognition. Meta-learning specializes in improving the few-shot learning. As a result, we employ meta-learning techniques on speech emotion recognition tasks, accent recognition, and person identification. To this end, we propose a series of improvements over the multistage meta-learning method. Unlike other works focusing on smaller models due to the high computational cost of meta-learning algorithms, we take a more practical approach. We incorporate a large pre-trained backbone and a prototypical network, making our methods more feasible and applicable. Our most notable contribution is an improved fine-tuning technique during meta-testing that significantly boosts the performance on out-of-distribution datasets. This result, together with incremental improvements from several other works, helped us achieve accuracy scores of 83.78% and 56.30% for Greek and Romanian speech emotion recognition datasets not included in the training or validation splits in the context of 4-way 5-shot learning.
Enhancing Romanian Offensive Language Detection through Knowledge Distillation, Multi-Task Learning, and Data Augmentation
Sep 30, 2024This paper highlights the significance of natural language processing (NLP) within artificial intelligence, underscoring its pivotal role in comprehending and modeling human language. Recent advancements in NLP, particularly in conversational bots, have garnered substantial attention and adoption among developers. This paper explores advanced methodologies for attaining smaller and more efficient NLP models. Specifically, we employ three key approaches: (1) training a Transformer-based neural network to detect offensive language, (2) employing data augmentation and knowledge distillation techniques to increase performance, and (3) incorporating multi-task learning with knowledge distillation and teacher annealing using diverse datasets to enhance efficiency. The culmination of these methods has yielded demonstrably improved outcomes.
End-to-End Lip Reading in Romanian with Cross-Lingual Domain Adaptation and Lateral Inhibition
Oct 07, 2023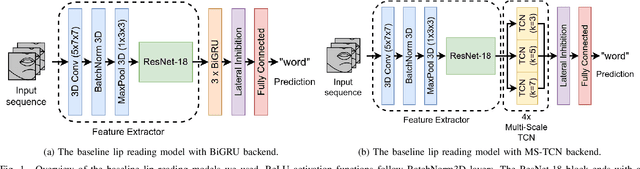
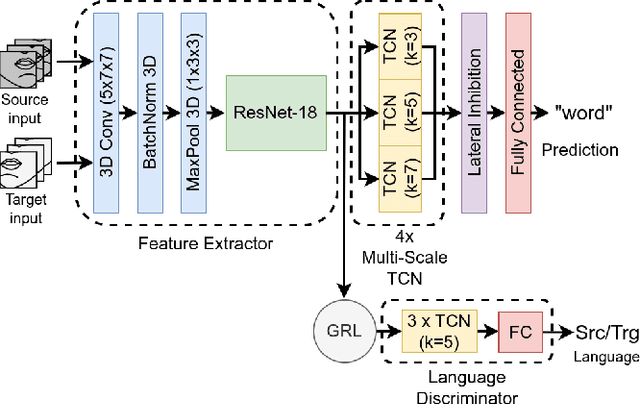
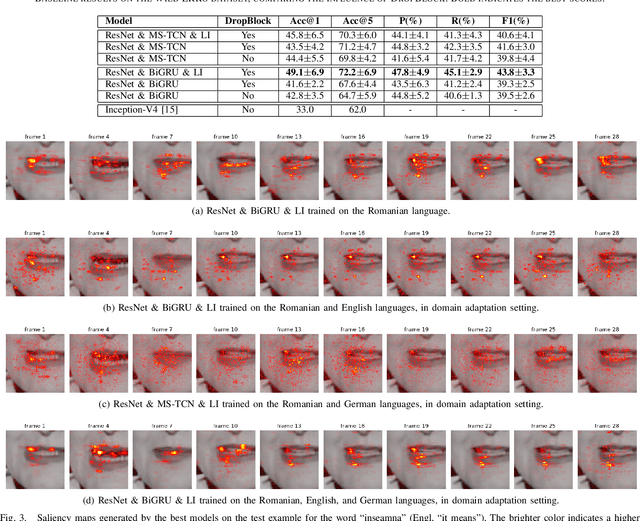
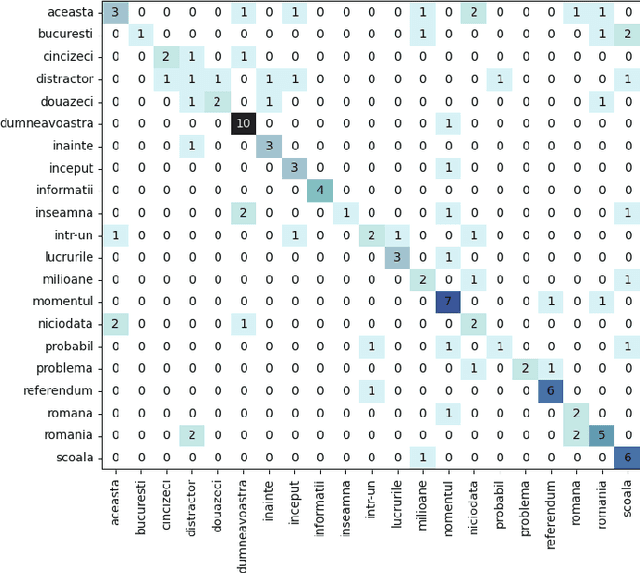
Lip reading or visual speech recognition has gained significant attention in recent years, particularly because of hardware development and innovations in computer vision. While considerable progress has been obtained, most models have only been tested on a few large-scale datasets. This work addresses this shortcoming by analyzing several architectures and optimizations on the underrepresented, short-scale Romanian language dataset called Wild LRRo. Most notably, we compare different backend modules, demonstrating the effectiveness of adding ample regularization methods. We obtain state-of-the-art results using our proposed method, namely cross-lingual domain adaptation and unlabeled videos from English and German datasets to help the model learn language-invariant features. Lastly, we assess the performance of adding a layer inspired by the neural inhibition mechanism.
From Fake to Hyperpartisan News Detection Using Domain Adaptation
Aug 04, 2023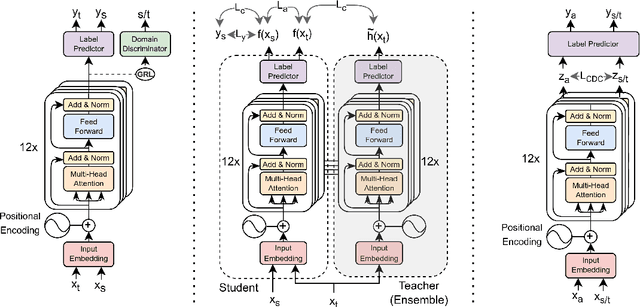
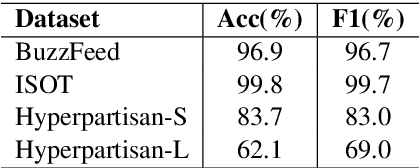

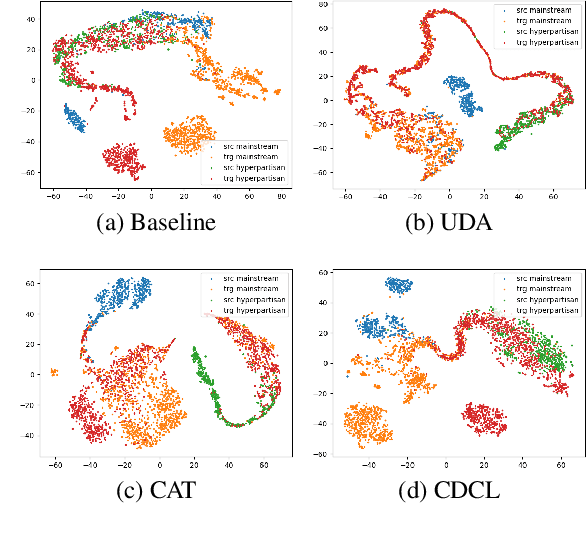
Unsupervised Domain Adaptation (UDA) is a popular technique that aims to reduce the domain shift between two data distributions. It was successfully applied in computer vision and natural language processing. In the current work, we explore the effects of various unsupervised domain adaptation techniques between two text classification tasks: fake and hyperpartisan news detection. We investigate the knowledge transfer from fake to hyperpartisan news detection without involving target labels during training. Thus, we evaluate UDA, cluster alignment with a teacher, and cross-domain contrastive learning. Extensive experiments show that these techniques improve performance, while including data augmentation further enhances the results. In addition, we combine clustering and topic modeling algorithms with UDA, resulting in improved performances compared to the initial UDA setup.
Towards Improving the Performance of Pre-Trained Speech Models for Low-Resource Languages Through Lateral Inhibition
Jun 30, 2023


With the rise of bidirectional encoder representations from Transformer models in natural language processing, the speech community has adopted some of their development methodologies. Therefore, the Wav2Vec models were introduced to reduce the data required to obtain state-of-the-art results. This work leverages this knowledge and improves the performance of the pre-trained speech models by simply replacing the fine-tuning dense layer with a lateral inhibition layer inspired by the biological process. Our experiments on Romanian, a low-resource language, show an average improvement of 12.5% word error rate (WER) using the lateral inhibition layer. In addition, we obtain state-of-the-art results on both the Romanian Speech Corpus and the Robin Technical Acquisition Corpus with 1.78% WER and 29.64% WER, respectively.
Adversarial Capsule Networks for Romanian Satire Detection and Sentiment Analysis
Jun 13, 2023Satire detection and sentiment analysis are intensively explored natural language processing (NLP) tasks that study the identification of the satirical tone from texts and extracting sentiments in relationship with their targets. In languages with fewer research resources, an alternative is to produce artificial examples based on character-level adversarial processes to overcome dataset size limitations. Such samples are proven to act as a regularization method, thus improving the robustness of models. In this work, we improve the well-known NLP models (i.e., Convolutional Neural Networks, Long Short-Term Memory (LSTM), Bidirectional LSTM, Gated Recurrent Units (GRUs), and Bidirectional GRUs) with adversarial training and capsule networks. The fine-tuned models are used for satire detection and sentiment analysis tasks in the Romanian language. The proposed framework outperforms the existing methods for the two tasks, achieving up to 99.08% accuracy, thus confirming the improvements added by the capsule layers and the adversarial training in NLP approaches.