 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Self-Interpretation from Interpretability Artifacts: Training Lightweight Adapters on Vector-Label Pairs
Feb 10, 2026Self-interpretation methods prompt language models to describe their own internal states, but remain unreliable due to hyperparameter sensitivity. We show that training lightweight adapters on interpretability artifacts, while keeping the LM entirely frozen, yields reliable self-interpretation across tasks and model families. A scalar affine adapter with just $d_\text{model}+1$ parameters suffices: trained adapters generate sparse autoencoder feature labels that outperform the training labels themselves (71% vs 63% generation scoring at 70B scale), identify topics with 94% recall@1 versus 1% for untrained baselines, and decode bridge entities in multi-hop reasoning that appear in neither prompt nor response, surfacing implicit reasoning without chain-of-thought. The learned bias vector alone accounts for 85% of improvement, and simpler adapters generalize better than more expressive alternatives. Controlling for model knowledge via prompted descriptions, we find self-interpretation gains outpace capability gains from 7B to 72B parameters. Our results demonstrate that self-interpretation improves with scale, without modifying the model being interpreted.
RoLargeSum: A Large Dialect-Aware Romanian News Dataset for Summary, Headline, and Keyword Generation
Dec 15, 2024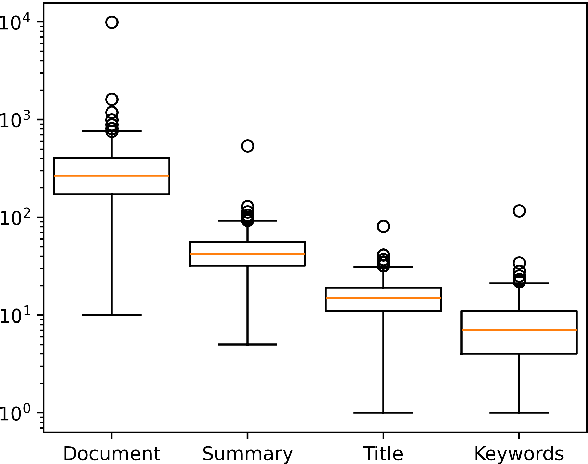
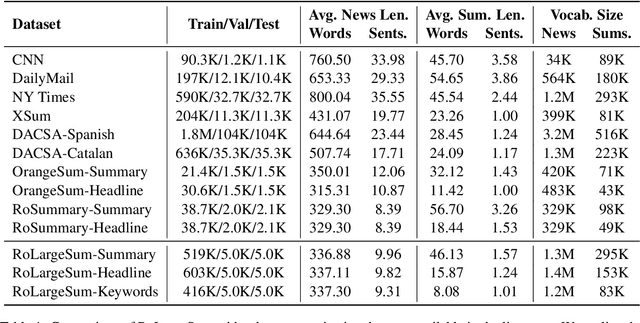
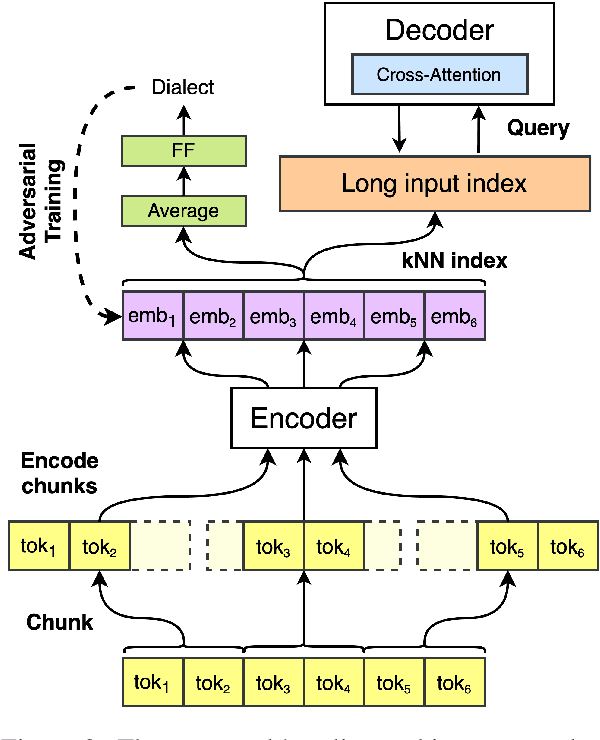
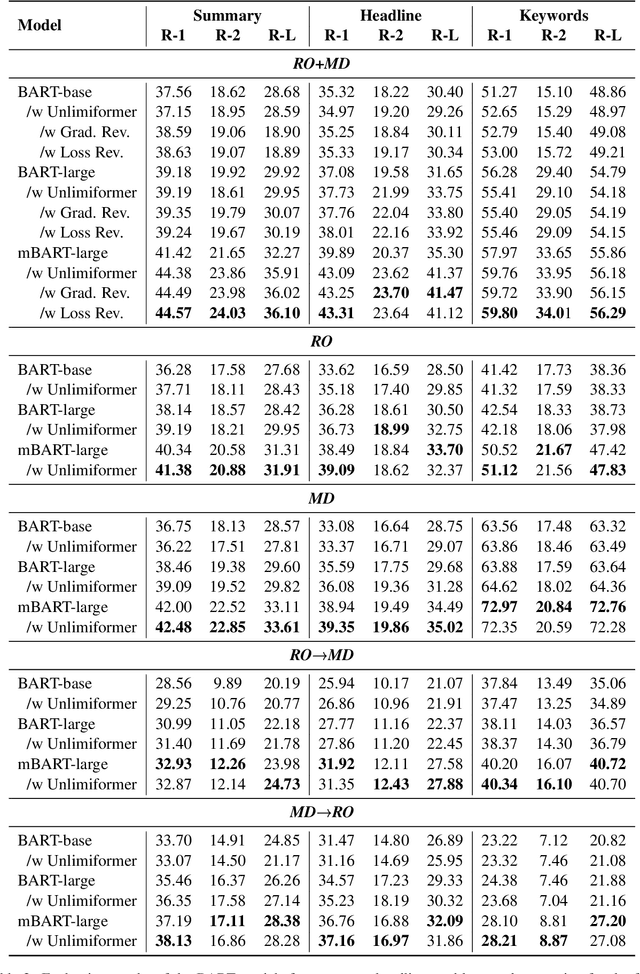
Using supervised automatic summarisation methods requires sufficient corpora that include pairs of documents and their summaries. Similarly to many tasks in natural language processing, most of the datasets available for summarization are in English, posing challenges for developing summarization models in other languages. Thus, in this work, we introduce RoLargeSum, a novel large-scale summarization dataset for the Romanian language crawled from various publicly available news websites from Romania and the Republic of Moldova that were thoroughly cleaned to ensure a high-quality standard. RoLargeSum contains more than 615K news articles, together with their summaries, as well as their headlines, keywords, dialect, and other metadata that we found on the targeted websites. We further evaluated the performance of several BART variants and open-source large language models on RoLargeSum for benchmarking purposes. We manually evaluated the results of the best-performing system to gain insight into the potential pitfalls of this data set and future development.
Investigating Large Language Models for Complex Word Identification in Multilingual and Multidomain Setups
Nov 03, 2024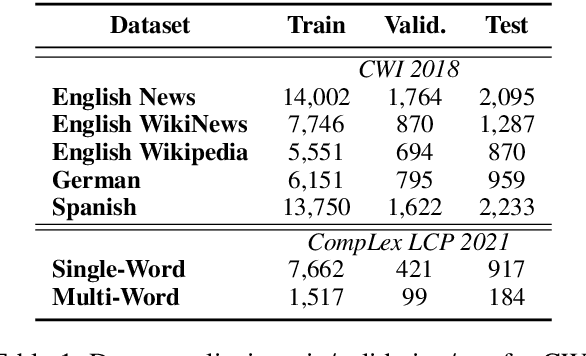
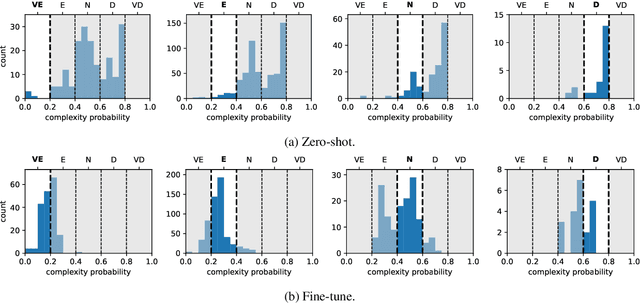
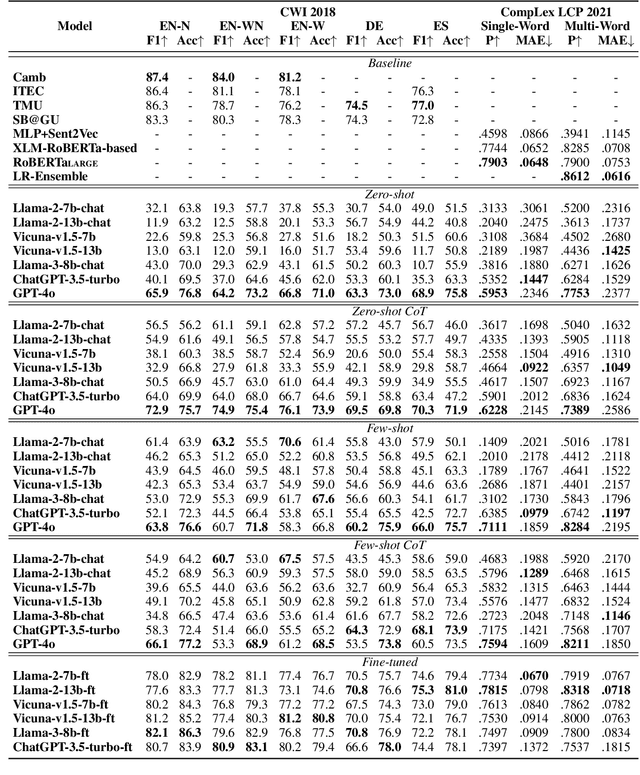
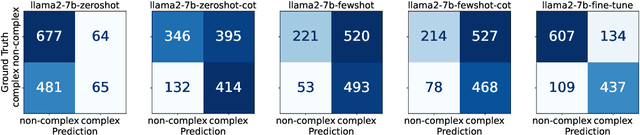
Complex Word Identification (CWI) is an essential step in the lexical simplification task and has recently become a task on its own. Some variations of this binary classification task have emerged, such as lexical complexity prediction (LCP) and complexity evaluation of multi-word expressions (MWE). Large language models (LLMs) recently became popular in the Natural Language Processing community because of their versatility and capability to solve unseen tasks in zero/few-shot settings. Our work investigates LLM usage, specifically open-source models such as Llama 2, Llama 3, and Vicuna v1.5, and closed-source, such as ChatGPT-3.5-turbo and GPT-4o, in the CWI, LCP, and MWE settings. We evaluate zero-shot, few-shot, and fine-tuning settings and show that LLMs struggle in certain conditions or achieve comparable results against existing methods. In addition, we provide some views on meta-learning combined with prompt learning. In the end, we conclude that the current state of LLMs cannot or barely outperform existing methods, which are usually much smaller.
A Cross-Lingual Meta-Learning Method Based on Domain Adaptation for Speech Emotion Recognition
Oct 06, 2024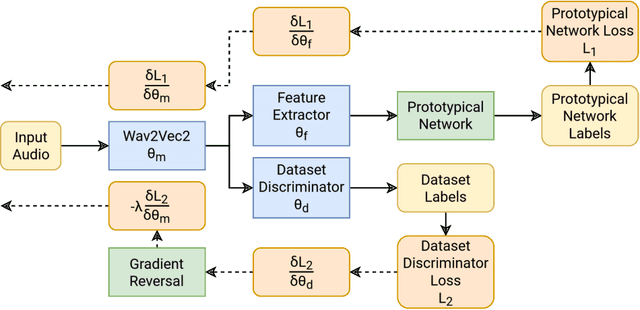
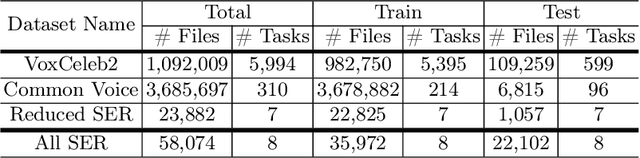
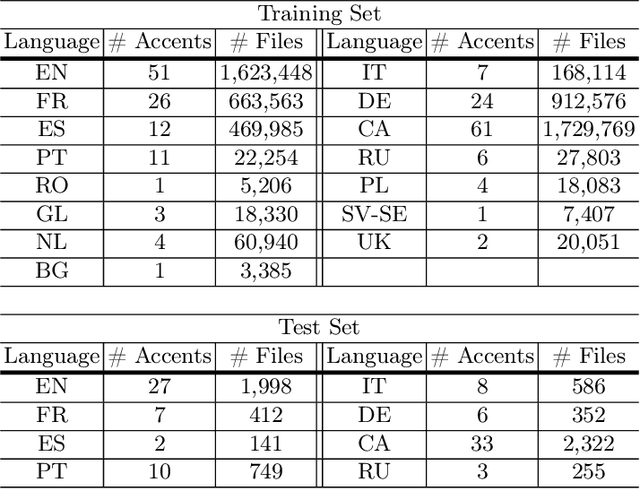
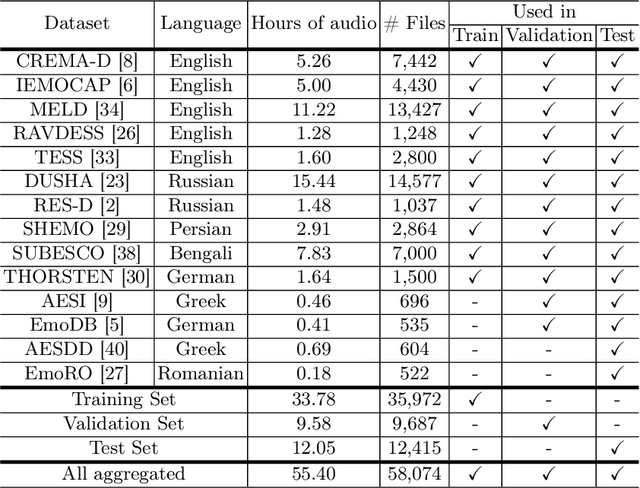
Best-performing speech models are trained on large amounts of data in the language they are meant to work for. However, most languages have sparse data, making training models challenging. This shortage of data is even more prevalent in speech emotion recognition. Our work explores the model's performance in limited data, specifically for speech emotion recognition. Meta-learning specializes in improving the few-shot learning. As a result, we employ meta-learning techniques on speech emotion recognition tasks, accent recognition, and person identification. To this end, we propose a series of improvements over the multistage meta-learning method. Unlike other works focusing on smaller models due to the high computational cost of meta-learning algorithms, we take a more practical approach. We incorporate a large pre-trained backbone and a prototypical network, making our methods more feasible and applicable. Our most notable contribution is an improved fine-tuning technique during meta-testing that significantly boosts the performance on out-of-distribution datasets. This result, together with incremental improvements from several other works, helped us achieve accuracy scores of 83.78% and 56.30% for Greek and Romanian speech emotion recognition datasets not included in the training or validation splits in the context of 4-way 5-shot learning.
Investigating the Impact of Semi-Supervised Methods with Data Augmentation on Offensive Language Detection in Romanian Language
Jul 29, 2024



Offensive language detection is a crucial task in today's digital landscape, where online platforms grapple with maintaining a respectful and inclusive environment. However, building robust offensive language detection models requires large amounts of labeled data, which can be expensive and time-consuming to obtain. Semi-supervised learning offers a feasible solution by utilizing labeled and unlabeled data to create more accurate and robust models. In this paper, we explore a few different semi-supervised methods, as well as data augmentation techniques. Concretely, we implemented eight semi-supervised methods and ran experiments for them using only the available data in the RO-Offense dataset and applying five augmentation techniques before feeding the data to the models. Experimental results demonstrate that some of them benefit more from augmentations than others.
Unexpected Benefits of Self-Modeling in Neural Systems
Jul 14, 2024



Self-models have been a topic of great interest for decades in studies of human cognition and more recently in machine learning. Yet what benefits do self-models confer? Here we show that when artificial networks learn to predict their internal states as an auxiliary task, they change in a fundamental way. To better perform the self-model task, the network learns to make itself simpler, more regularized, more parameter-efficient, and therefore more amenable to being predictively modeled. To test the hypothesis of self-regularizing through self-modeling, we used a range of network architectures performing three classification tasks across two modalities. In all cases, adding self-modeling caused a significant reduction in network complexity. The reduction was observed in two ways. First, the distribution of weights was narrower when self-modeling was present. Second, a measure of network complexity, the real log canonical threshold (RLCT), was smaller when self-modeling was present. Not only were measures of complexity reduced, but the reduction became more pronounced as greater training weight was placed on the auxiliary task of self-modeling. These results strongly support the hypothesis that self-modeling is more than simply a network learning to predict itself. The learning has a restructuring effect, reducing complexity and increasing parameter efficiency. This self-regularization may help explain some of the benefits of self-models reported in recent machine learning literature, as well as the adaptive value of self-models to biological systems. In particular, these findings may shed light on the possible interaction between the ability to model oneself and the ability to be more easily modeled by others in a social or cooperative context.
Rethinking harmless refusals when fine-tuning foundation models
Jun 27, 2024



In this paper, we investigate the degree to which fine-tuning in Large Language Models (LLMs) effectively mitigates versus merely conceals undesirable behavior. Through the lens of semi-realistic role-playing exercises designed to elicit such behaviors, we explore the response dynamics of LLMs post fine-tuning interventions. Our methodology involves prompting models for Chain-of-Thought (CoT) reasoning and analyzing the coherence between the reasoning traces and the resultant outputs. Notably, we identify a pervasive phenomenon we term \emph{reason-based deception}, where models either stop producing reasoning traces or produce seemingly ethical reasoning traces that belie the unethical nature of their final outputs. We further examine the efficacy of response strategies (polite refusal versus explicit rebuttal) in curbing the occurrence of undesired behavior in subsequent outputs of multi-turn interactions. Our findings reveal that explicit rebuttals significantly outperform polite refusals in preventing the continuation of undesired outputs and nearly eliminate reason-based deception, challenging current practices in model fine-tuning. Accordingly, the two key contributions of this paper are (1) defining and studying reason-based deception, a new type of hidden behavior, and (2) demonstrating that rebuttals provide a more robust response model to harmful requests than refusals, thereby highlighting the need to reconsider the response strategies in fine-tuning approaches.
Evaluating Data Augmentation Techniques for Coffee Leaf Disease Classification
Jan 11, 2024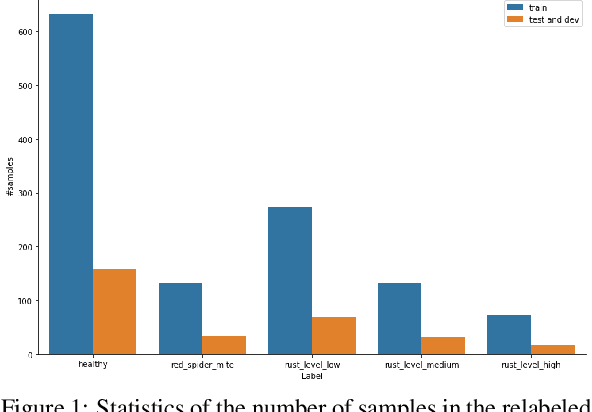
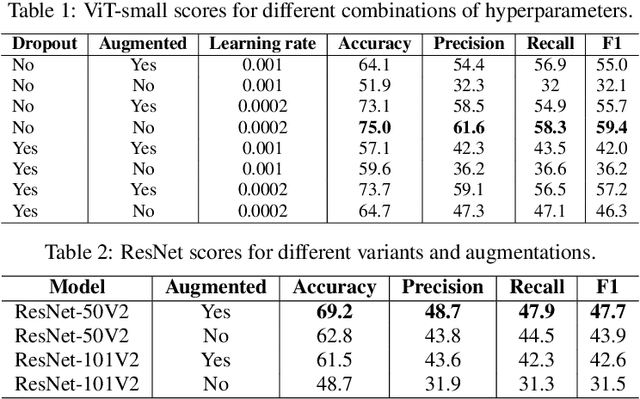


The detection and classification of diseases in Robusta coffee leaves are essential to ensure that plants are healthy and the crop yield is kept high. However, this job requires extensive botanical knowledge and much wasted time. Therefore, this task and others similar to it have been extensively researched subjects in image classification. Regarding leaf disease classification, most approaches have used the more popular PlantVillage dataset while completely disregarding other datasets, like the Robusta Coffee Leaf (RoCoLe) dataset. As the RoCoLe dataset is imbalanced and does not have many samples, fine-tuning of pre-trained models and multiple augmentation techniques need to be used. The current paper uses the RoCoLe dataset and approaches based on deep learning for classifying coffee leaf diseases from images, incorporating the pix2pix model for segmentation and cycle-generative adversarial network (CycleGAN) for augmentation. Our study demonstrates the effectiveness of Transformer-based models, online augmentations, and CycleGAN augmentation in improving leaf disease classification. While synthetic data has limitations, it complements real data, enhancing model performance. These findings contribute to developing robust techniques for plant disease detection and classification.
Explainability-Driven Leaf Disease Classification using Adversarial Training and Knowledge Distillation
Dec 30, 2023



This work focuses on plant leaf disease classification and explores three crucial aspects: adversarial training, model explainability, and model compression. The models' robustness against adversarial attacks is enhanced through adversarial training, ensuring accurate classification even in the presence of threats. Leveraging explainability techniques, we gain insights into the model's decision-making process, improving trust and transparency. Additionally, we explore model compression techniques to optimize computational efficiency while maintaining classification performance. Through our experiments, we determine that on a benchmark dataset, the robustness can be the price of the classification accuracy with performance reductions of 3%-20% for regular tests and gains of 50%-70% for adversarial attack tests. We also demonstrate that a student model can be 15-25 times more computationally efficient for a slight performance reduction, distilling the knowledge of more complex models.
End-to-End Lip Reading in Romanian with Cross-Lingual Domain Adaptation and Lateral Inhibition
Oct 07, 2023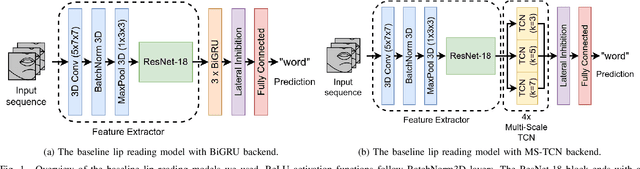
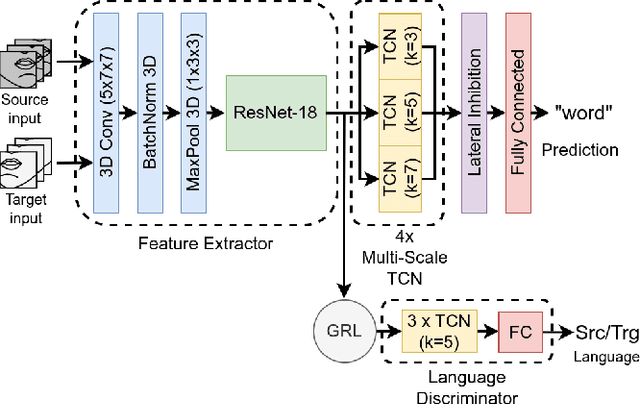
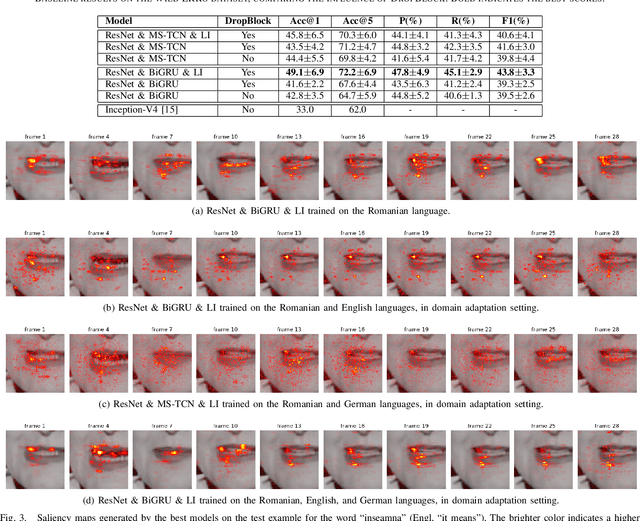
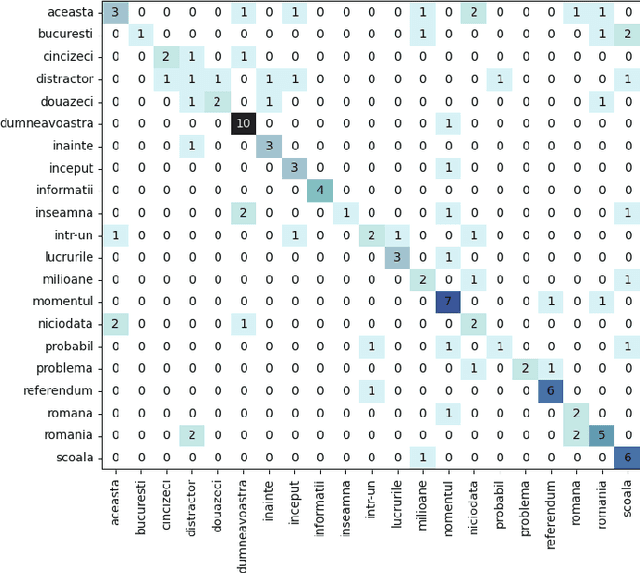
Lip reading or visual speech recognition has gained significant attention in recent years, particularly because of hardware development and innovations in computer vision. While considerable progress has been obtained, most models have only been tested on a few large-scale datasets. This work addresses this shortcoming by analyzing several architectures and optimizations on the underrepresented, short-scale Romanian language dataset called Wild LRRo. Most notably, we compare different backend modules, demonstrating the effectiveness of adding ample regularization methods. We obtain state-of-the-art results using our proposed method, namely cross-lingual domain adaptation and unlabeled videos from English and German datasets to help the model learn language-invariant features. Lastly, we assess the performance of adding a layer inspired by the neural inhibition mechanism.