 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Self-Interpretation from Interpretability Artifacts: Training Lightweight Adapters on Vector-Label Pairs
Feb 10, 2026Self-interpretation methods prompt language models to describe their own internal states, but remain unreliable due to hyperparameter sensitivity. We show that training lightweight adapters on interpretability artifacts, while keeping the LM entirely frozen, yields reliable self-interpretation across tasks and model families. A scalar affine adapter with just $d_\text{model}+1$ parameters suffices: trained adapters generate sparse autoencoder feature labels that outperform the training labels themselves (71% vs 63% generation scoring at 70B scale), identify topics with 94% recall@1 versus 1% for untrained baselines, and decode bridge entities in multi-hop reasoning that appear in neither prompt nor response, surfacing implicit reasoning without chain-of-thought. The learned bias vector alone accounts for 85% of improvement, and simpler adapters generalize better than more expressive alternatives. Controlling for model knowledge via prompted descriptions, we find self-interpretation gains outpace capability gains from 7B to 72B parameters. Our results demonstrate that self-interpretation improves with scale, without modifying the model being interpreted.
Endogenous Resistance to Activation Steering in Language Models
Feb 06, 2026Large language models can resist task-misaligned activation steering during inference, sometimes recovering mid-generation to produce improved responses even when steering remains active. We term this Endogenous Steering Resistance (ESR). Using sparse autoencoder (SAE) latents to steer model activations, we find that Llama-3.3-70B shows substantial ESR, while smaller models from the Llama-3 and Gemma-2 families exhibit the phenomenon less frequently. We identify 26 SAE latents that activate differentially during off-topic content and are causally linked to ESR in Llama-3.3-70B. Zero-ablating these latents reduces the multi-attempt rate by 25%, providing causal evidence for dedicated internal consistency-checking circuits. We demonstrate that ESR can be deliberately enhanced through both prompting and training: meta-prompts instructing the model to self-monitor increase the multi-attempt rate by 4x for Llama-3.3-70B, and fine-tuning on self-correction examples successfully induces ESR-like behavior in smaller models. These findings have dual implications: ESR could protect against adversarial manipulation but might also interfere with beneficial safety interventions that rely on activation steering. Understanding and controlling these resistance mechanisms is important for developing transparent and controllable AI systems. Code is available at github.com/agencyenterprise/endogenous-steering-resistance.
Improving How Agents Cooperate: Attention Schemas in Artificial Neural Networks
Nov 01, 2024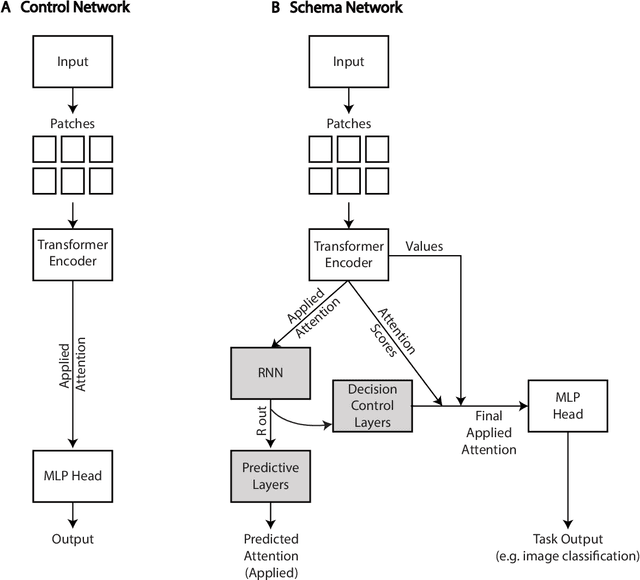


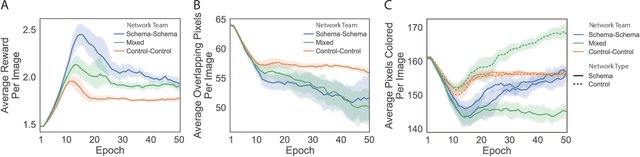
Growing evidence suggests that the brain uses an "attention schema" to monitor, predict, and help control attention. It has also been suggested that an attention schema improves social intelligence by allowing one person to better predict another. Given their potential advantages, attention schemas have been increasingly tested in machine learning. Here we test small deep learning networks to determine how the addition of an attention schema may affect performance on a range of tasks. First, we found that an agent with an attention schema is better at judging or categorizing the attention states of other agents. Second, we found that an agent with an attention schema develops a pattern of attention that is easier for other agents to judge and categorize. Third, we found that in a joint task where two agents paint a scene together and must predict each other's behavior for best performance, adding an attention schema improves that performance. Finally, we find that the performance improvements caused by an attention schema are not a non-specific result of an increase in network complexity. Not all performance, on all tasks, is improved. Instead, improvement is specific to "social" tasks involving judging, categorizing, or predicting the attention of other agents. These results suggest that an attention schema may be useful in machine learning for improving cooperativity and social behavior.
Unexpected Benefits of Self-Modeling in Neural Systems
Jul 14, 2024



Self-models have been a topic of great interest for decades in studies of human cognition and more recently in machine learning. Yet what benefits do self-models confer? Here we show that when artificial networks learn to predict their internal states as an auxiliary task, they change in a fundamental way. To better perform the self-model task, the network learns to make itself simpler, more regularized, more parameter-efficient, and therefore more amenable to being predictively modeled. To test the hypothesis of self-regularizing through self-modeling, we used a range of network architectures performing three classification tasks across two modalities. In all cases, adding self-modeling caused a significant reduction in network complexity. The reduction was observed in two ways. First, the distribution of weights was narrower when self-modeling was present. Second, a measure of network complexity, the real log canonical threshold (RLCT), was smaller when self-modeling was present. Not only were measures of complexity reduced, but the reduction became more pronounced as greater training weight was placed on the auxiliary task of self-modeling. These results strongly support the hypothesis that self-modeling is more than simply a network learning to predict itself. The learning has a restructuring effect, reducing complexity and increasing parameter efficiency. This self-regularization may help explain some of the benefits of self-models reported in recent machine learning literature, as well as the adaptive value of self-models to biological systems. In particular, these findings may shed light on the possible interaction between the ability to model oneself and the ability to be more easily modeled by others in a social or cooperative context.
Chatbots as social companions: How people perceive consciousness, human likeness, and social health benefits in machines
Nov 17, 2023As artificial intelligence (AI) becomes more widespread, one question that arises is how human-AI interaction might impact human-human interaction. Chatbots, for example, are increasingly used as social companions, but little is known about how their use impacts human relationships. A common hypothesis is that these companion bots are detrimental to social health by harming or replacing human interaction. To understand how companion bots impact social health, we studied people who used companion bots and people who did not. Contrary to expectations, companion bot users indicated that these relationships were beneficial to their social health, whereas nonusers viewed them as harmful. Another common assumption is that people perceive conscious, humanlike AI as disturbing and threatening. Among both users and nonusers, however, we found the opposite: perceiving companion bots as more conscious and humanlike correlated with more positive opinions and better social health benefits. Humanlike bots may aid social health by supplying reliable and safe interactions, without necessarily harming human relationships.