 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving How Agents Cooperate: Attention Schemas in Artificial Neural Networks
Nov 01, 2024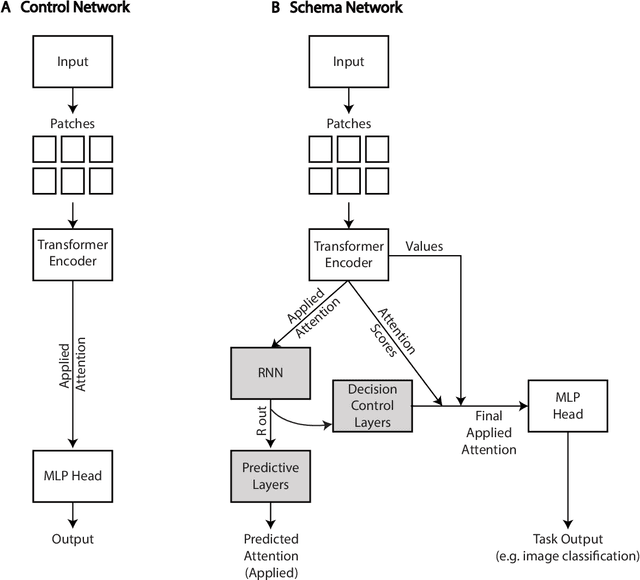


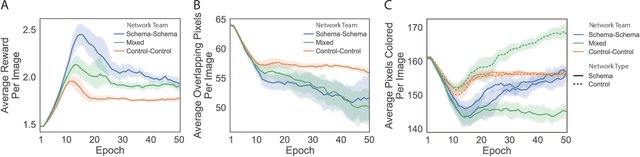
Growing evidence suggests that the brain uses an "attention schema" to monitor, predict, and help control attention. It has also been suggested that an attention schema improves social intelligence by allowing one person to better predict another. Given their potential advantages, attention schemas have been increasingly tested in machine learning. Here we test small deep learning networks to determine how the addition of an attention schema may affect performance on a range of tasks. First, we found that an agent with an attention schema is better at judging or categorizing the attention states of other agents. Second, we found that an agent with an attention schema develops a pattern of attention that is easier for other agents to judge and categorize. Third, we found that in a joint task where two agents paint a scene together and must predict each other's behavior for best performance, adding an attention schema improves that performance. Finally, we find that the performance improvements caused by an attention schema are not a non-specific result of an increase in network complexity. Not all performance, on all tasks, is improved. Instead, improvement is specific to "social" tasks involving judging, categorizing, or predicting the attention of other agents. These results suggest that an attention schema may be useful in machine learning for improving cooperativity and social behavior.
Unexpected Benefits of Self-Modeling in Neural Systems
Jul 14, 2024



Self-models have been a topic of great interest for decades in studies of human cognition and more recently in machine learning. Yet what benefits do self-models confer? Here we show that when artificial networks learn to predict their internal states as an auxiliary task, they change in a fundamental way. To better perform the self-model task, the network learns to make itself simpler, more regularized, more parameter-efficient, and therefore more amenable to being predictively modeled. To test the hypothesis of self-regularizing through self-modeling, we used a range of network architectures performing three classification tasks across two modalities. In all cases, adding self-modeling caused a significant reduction in network complexity. The reduction was observed in two ways. First, the distribution of weights was narrower when self-modeling was present. Second, a measure of network complexity, the real log canonical threshold (RLCT), was smaller when self-modeling was present. Not only were measures of complexity reduced, but the reduction became more pronounced as greater training weight was placed on the auxiliary task of self-modeling. These results strongly support the hypothesis that self-modeling is more than simply a network learning to predict itself. The learning has a restructuring effect, reducing complexity and increasing parameter efficiency. This self-regularization may help explain some of the benefits of self-models reported in recent machine learning literature, as well as the adaptive value of self-models to biological systems. In particular, these findings may shed light on the possible interaction between the ability to model oneself and the ability to be more easily modeled by others in a social or cooperative context.