 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Large Language Models for Complex Word Identification in Multilingual and Multidomain Setups
Nov 03, 2024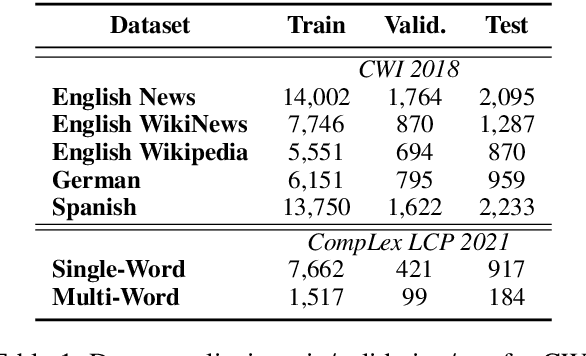
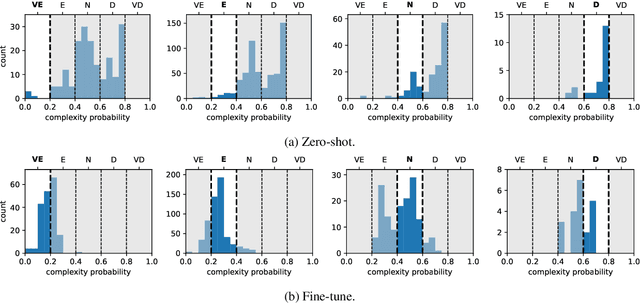
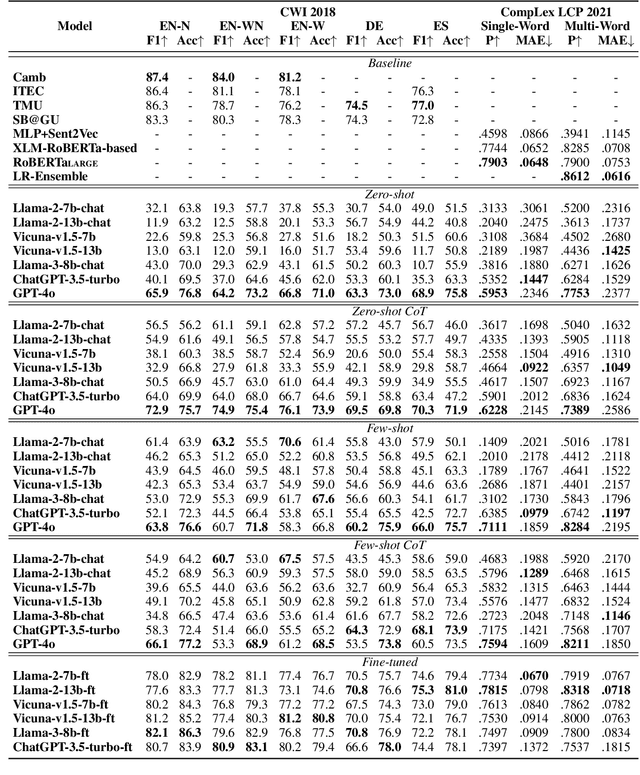
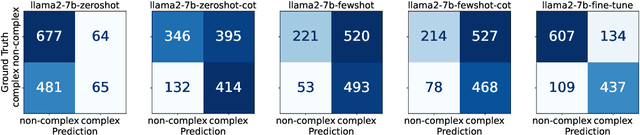
Complex Word Identification (CWI) is an essential step in the lexical simplification task and has recently become a task on its own. Some variations of this binary classification task have emerged, such as lexical complexity prediction (LCP) and complexity evaluation of multi-word expressions (MWE). Large language models (LLMs) recently became popular in the Natural Language Processing community because of their versatility and capability to solve unseen tasks in zero/few-shot settings. Our work investigates LLM usage, specifically open-source models such as Llama 2, Llama 3, and Vicuna v1.5, and closed-source, such as ChatGPT-3.5-turbo and GPT-4o, in the CWI, LCP, and MWE settings. We evaluate zero-shot, few-shot, and fine-tuning settings and show that LLMs struggle in certain conditions or achieve comparable results against existing methods. In addition, we provide some views on meta-learning combined with prompt learning. In the end, we conclude that the current state of LLMs cannot or barely outperform existing methods, which are usually much smaller.
A Cross-Lingual Meta-Learning Method Based on Domain Adaptation for Speech Emotion Recognition
Oct 06, 2024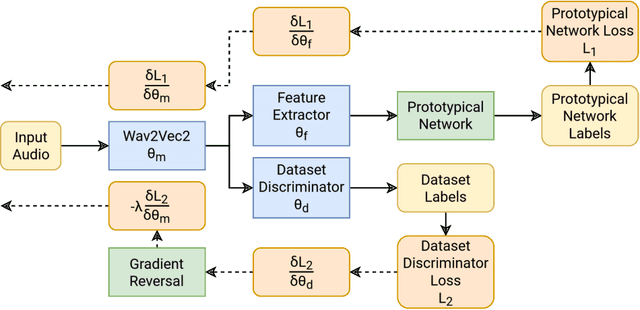
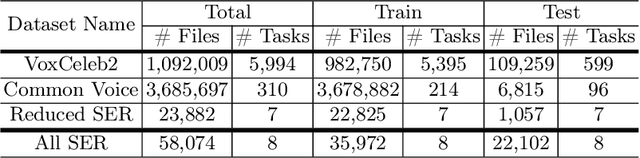
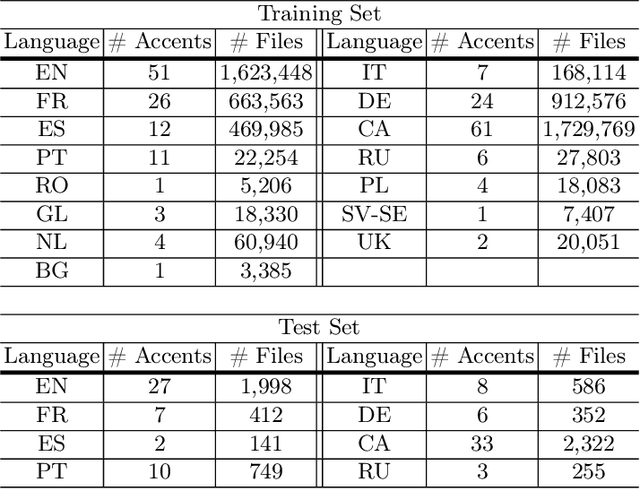
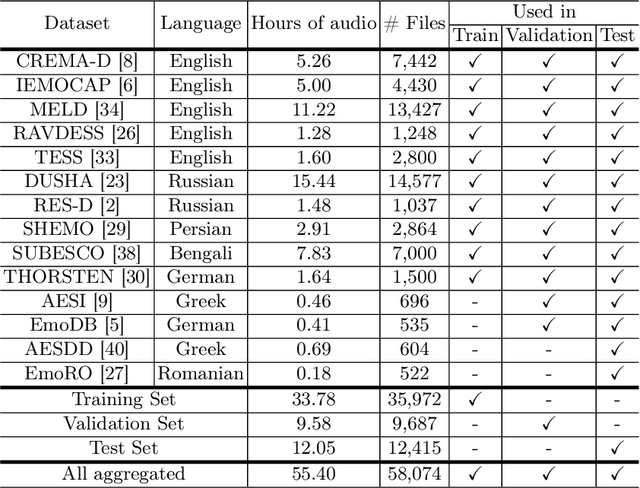
Best-performing speech models are trained on large amounts of data in the language they are meant to work for. However, most languages have sparse data, making training models challenging. This shortage of data is even more prevalent in speech emotion recognition. Our work explores the model's performance in limited data, specifically for speech emotion recognition. Meta-learning specializes in improving the few-shot learning. As a result, we employ meta-learning techniques on speech emotion recognition tasks, accent recognition, and person identification. To this end, we propose a series of improvements over the multistage meta-learning method. Unlike other works focusing on smaller models due to the high computational cost of meta-learning algorithms, we take a more practical approach. We incorporate a large pre-trained backbone and a prototypical network, making our methods more feasible and applicable. Our most notable contribution is an improved fine-tuning technique during meta-testing that significantly boosts the performance on out-of-distribution datasets. This result, together with incremental improvements from several other works, helped us achieve accuracy scores of 83.78% and 56.30% for Greek and Romanian speech emotion recognition datasets not included in the training or validation splits in the context of 4-way 5-shot learning.