 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoLargeSum: A Large Dialect-Aware Romanian News Dataset for Summary, Headline, and Keyword Generation
Dec 15, 2024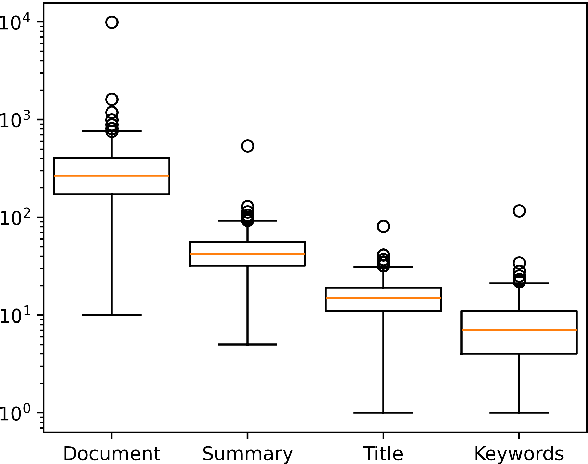
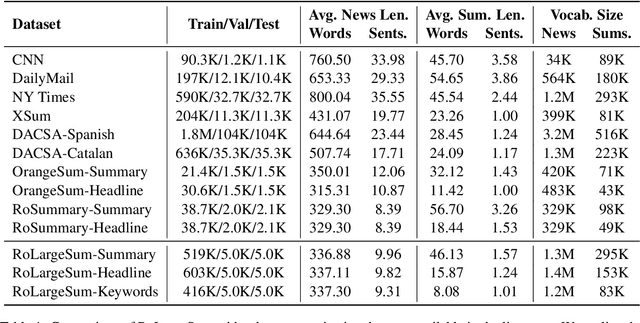
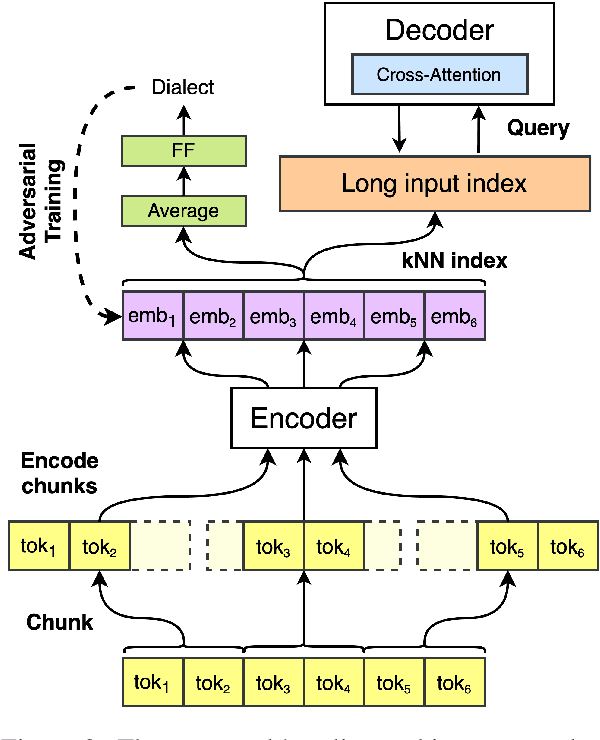
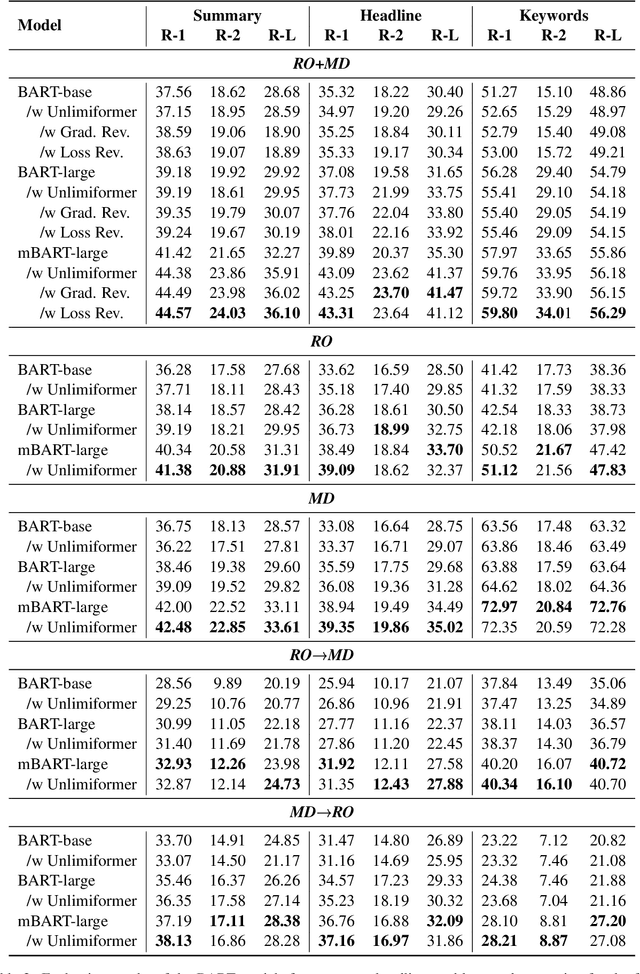
Using supervised automatic summarisation methods requires sufficient corpora that include pairs of documents and their summaries. Similarly to many tasks in natural language processing, most of the datasets available for summarization are in English, posing challenges for developing summarization models in other languages. Thus, in this work, we introduce RoLargeSum, a novel large-scale summarization dataset for the Romanian language crawled from various publicly available news websites from Romania and the Republic of Moldova that were thoroughly cleaned to ensure a high-quality standard. RoLargeSum contains more than 615K news articles, together with their summaries, as well as their headlines, keywords, dialect, and other metadata that we found on the targeted websites. We further evaluated the performance of several BART variants and open-source large language models on RoLargeSum for benchmarking purposes. We manually evaluated the results of the best-performing system to gain insight into the potential pitfalls of this data set and future development.
Enhancing Romanian Offensive Language Detection through Knowledge Distillation, Multi-Task Learning, and Data Augmentation
Sep 30, 2024This paper highlights the significance of natural language processing (NLP) within artificial intelligence, underscoring its pivotal role in comprehending and modeling human language. Recent advancements in NLP, particularly in conversational bots, have garnered substantial attention and adoption among developers. This paper explores advanced methodologies for attaining smaller and more efficient NLP models. Specifically, we employ three key approaches: (1) training a Transformer-based neural network to detect offensive language, (2) employing data augmentation and knowledge distillation techniques to increase performance, and (3) incorporating multi-task learning with knowledge distillation and teacher annealing using diverse datasets to enhance efficiency. The culmination of these methods has yielded demonstrably improved outcomes.
HistNERo: Historical Named Entity Recognition for the Romanian Language
Apr 30, 2024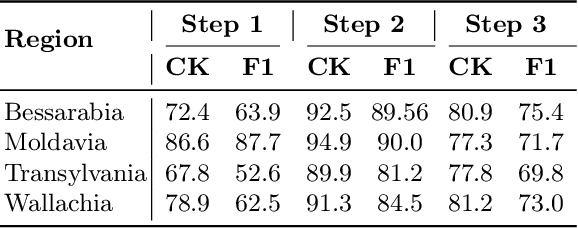
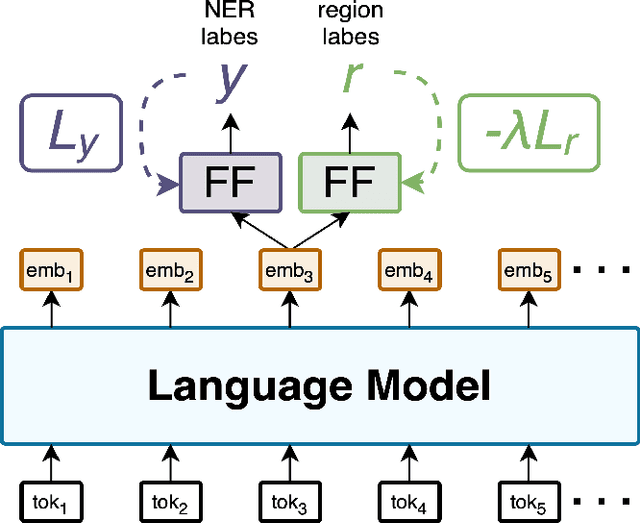
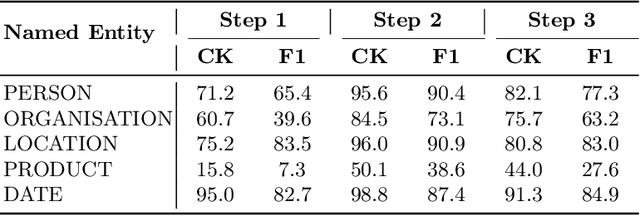
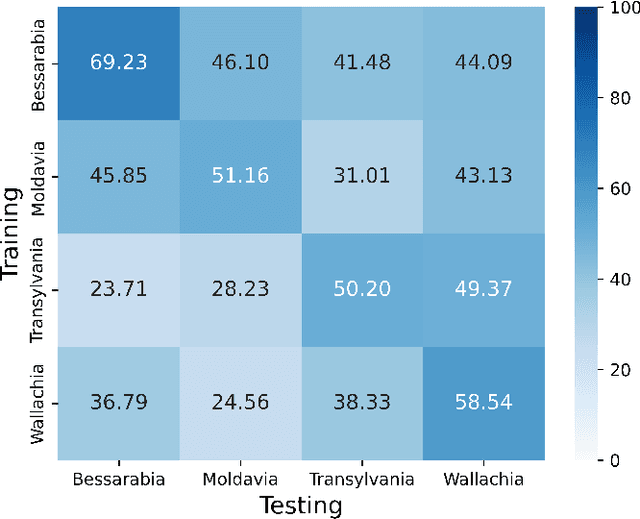
This work introduces HistNERo, the first Romanian corpus for Named Entity Recognition (NER) in historical newspapers. The dataset contains 323k tokens of text, covering more than half of the 19th century (i.e., 1817) until the late part of the 20th century (i.e., 1990). Eight native Romanian speakers annotated the dataset with five named entities. The samples belong to one of the following four historical regions of Romania, namely Bessarabia, Moldavia, Transylvania, and Wallachia. We employed this proposed dataset to perform several experiments for NER using Romanian pre-trained language models. Our results show that the best model achieved a strict F1-score of 55.69%. Also, by reducing the discrepancies between regions through a novel domain adaption technique, we improved the performance on this corpus to a strict F1-score of 66.80%, representing an absolute gain of more than 10%.