 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniBERTs: Adversarial Training for Language-Universal Representations
Mar 16, 2025This paper presents UniBERT, a compact multilingual language model that leverages an innovative training framework integrating three components: masked language modeling, adversarial training, and knowledge distillation. Pre-trained on a meticulously curated Wikipedia corpus spanning 107 languages, UniBERT is designed to reduce the computational demands of large-scale models while maintaining competitive performance across various natural language processing tasks. Comprehensive evaluations on four tasks -- named entity recognition, natural language inference, question answering, and semantic textual similarity -- demonstrate that our multilingual training strategy enhanced by an adversarial objective significantly improves cross-lingual generalization. Specifically, UniBERT models show an average relative improvement of 7.72% over traditional baselines, which achieved an average relative improvement of only 1.17%, with statistical analysis confirming the significance of these gains (p-value = 0.0181). This work highlights the benefits of combining adversarial training and knowledge distillation to build scalable and robust language models, thereby advancing the field of multilingual and cross-lingual natural language processing.
RoLargeSum: A Large Dialect-Aware Romanian News Dataset for Summary, Headline, and Keyword Generation
Dec 15, 2024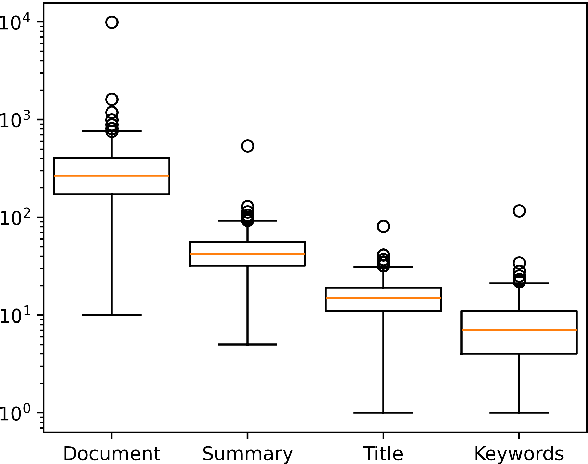
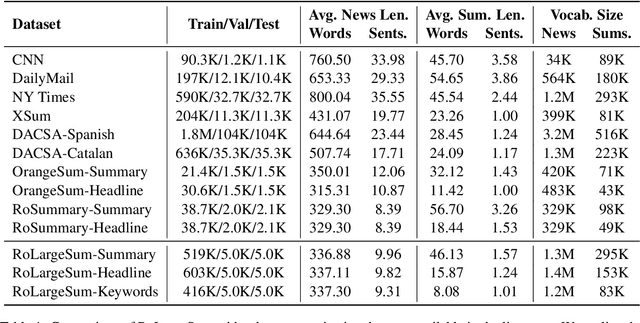
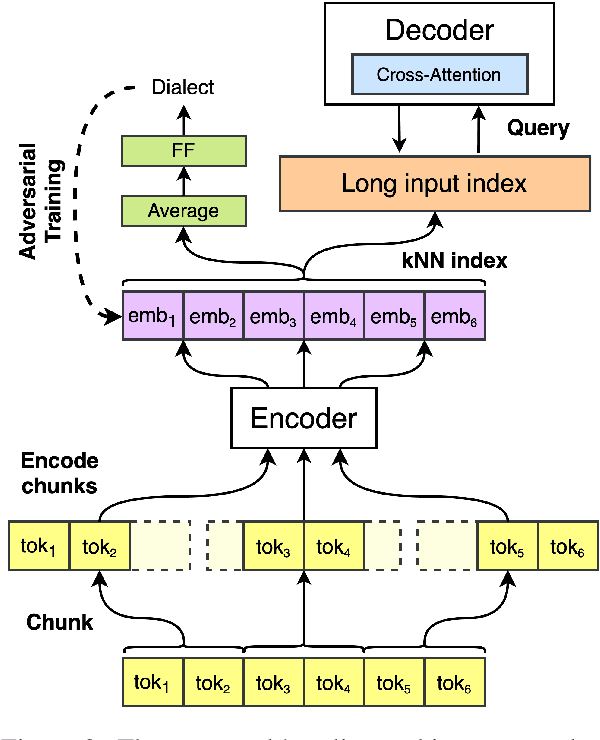
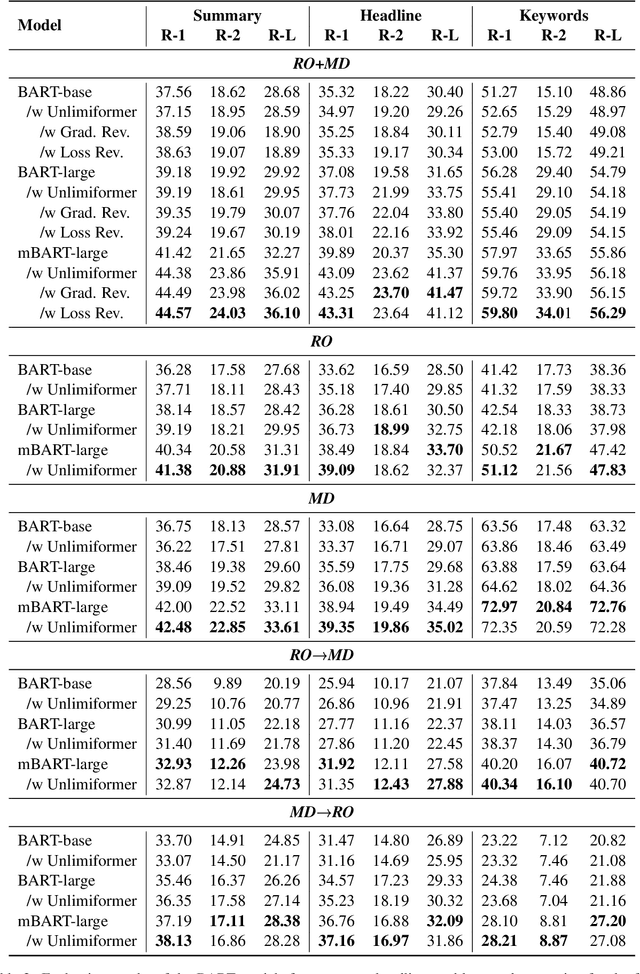
Using supervised automatic summarisation methods requires sufficient corpora that include pairs of documents and their summaries. Similarly to many tasks in natural language processing, most of the datasets available for summarization are in English, posing challenges for developing summarization models in other languages. Thus, in this work, we introduce RoLargeSum, a novel large-scale summarization dataset for the Romanian language crawled from various publicly available news websites from Romania and the Republic of Moldova that were thoroughly cleaned to ensure a high-quality standard. RoLargeSum contains more than 615K news articles, together with their summaries, as well as their headlines, keywords, dialect, and other metadata that we found on the targeted websites. We further evaluated the performance of several BART variants and open-source large language models on RoLargeSum for benchmarking purposes. We manually evaluated the results of the best-performing system to gain insight into the potential pitfalls of this data set and future development.
RELATE: A Modern Processing Platform for Romanian Language
Oct 29, 2024This paper presents the design and evolution of the RELATE platform. It provides a high-performance environment for natural language processing activities, specially constructed for Romanian language. Initially developed for text processing, it has been recently updated to integrate audio processing tools. Technical details are provided with regard to core components. We further present different usage scenarios, derived from actual use in national and international research projects, thus demonstrating that RELATE is a mature, modern, state-of-the-art platform for processing Romanian language corpora. Finally, we present very recent developments including bimodal (text and audio) features available within the platform.
RoQLlama: A Lightweight Romanian Adapted Language Model
Oct 05, 2024
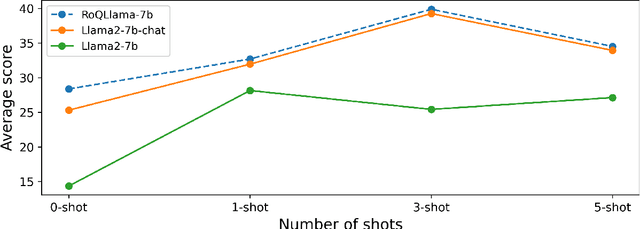

The remarkable achievements obtained by open-source large language models (LLMs) in recent years have predominantly been concentrated on tasks involving the English language. In this paper, we aim to advance the performance of Llama2 models on Romanian tasks. We tackle the problem of reduced computing resources by using QLoRA for training. We release RoQLlama-7b, a quantized LLM, which shows equal or improved results compared to its full-sized counterpart when tested on seven Romanian downstream tasks in the zero-shot setup. Also, it consistently achieves higher average scores across all few-shot prompts. Additionally, we introduce a novel Romanian dataset, namely RoMedQA, which contains single-choice medical questions in Romanian.
HistNERo: Historical Named Entity Recognition for the Romanian Language
Apr 30, 2024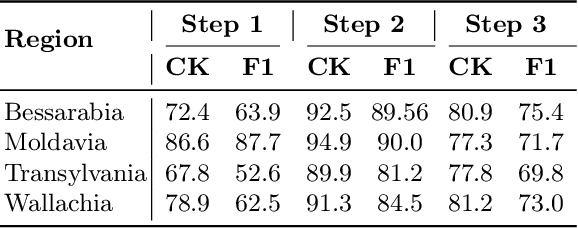
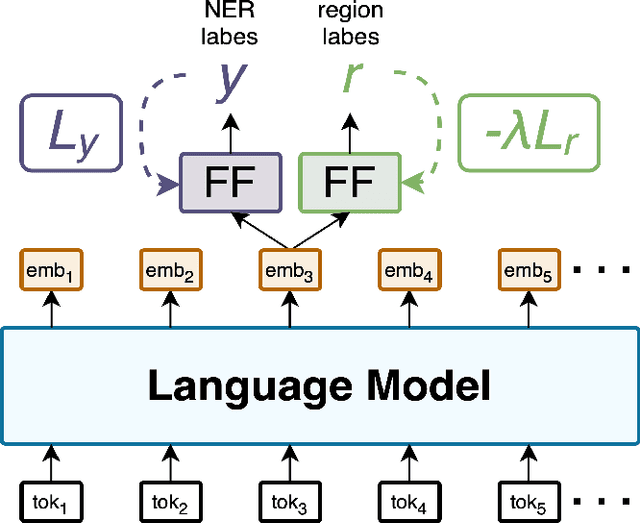
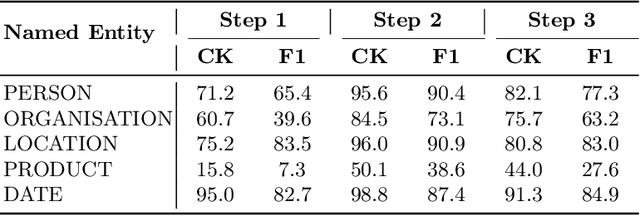
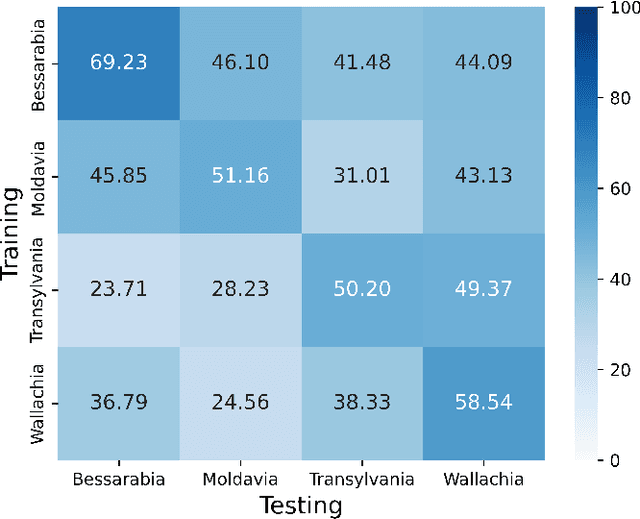
This work introduces HistNERo, the first Romanian corpus for Named Entity Recognition (NER) in historical newspapers. The dataset contains 323k tokens of text, covering more than half of the 19th century (i.e., 1817) until the late part of the 20th century (i.e., 1990). Eight native Romanian speakers annotated the dataset with five named entities. The samples belong to one of the following four historical regions of Romania, namely Bessarabia, Moldavia, Transylvania, and Wallachia. We employed this proposed dataset to perform several experiments for NER using Romanian pre-trained language models. Our results show that the best model achieved a strict F1-score of 55.69%. Also, by reducing the discrepancies between regions through a novel domain adaption technique, we improved the performance on this corpus to a strict F1-score of 66.80%, representing an absolute gain of more than 10%.
End-to-End Lip Reading in Romanian with Cross-Lingual Domain Adaptation and Lateral Inhibition
Oct 07, 2023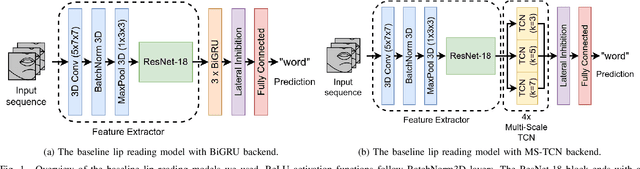
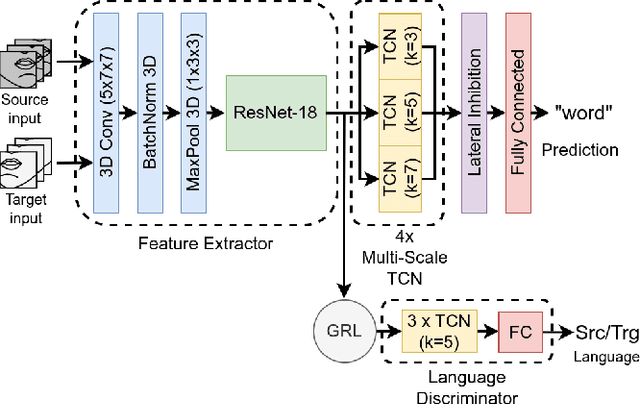
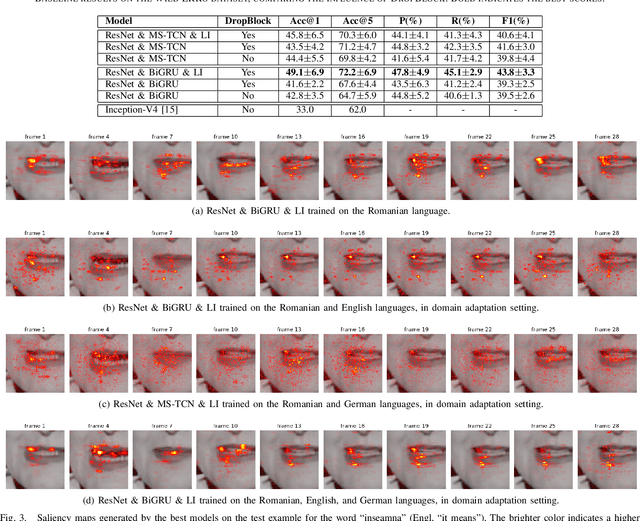
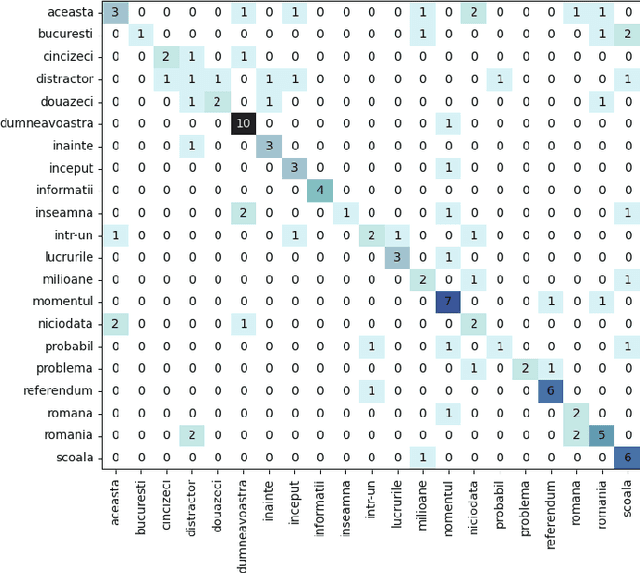
Lip reading or visual speech recognition has gained significant attention in recent years, particularly because of hardware development and innovations in computer vision. While considerable progress has been obtained, most models have only been tested on a few large-scale datasets. This work addresses this shortcoming by analyzing several architectures and optimizations on the underrepresented, short-scale Romanian language dataset called Wild LRRo. Most notably, we compare different backend modules, demonstrating the effectiveness of adding ample regularization methods. We obtain state-of-the-art results using our proposed method, namely cross-lingual domain adaptation and unlabeled videos from English and German datasets to help the model learn language-invariant features. Lastly, we assess the performance of adding a layer inspired by the neural inhibition mechanism.
Towards Improving the Performance of Pre-Trained Speech Models for Low-Resource Languages Through Lateral Inhibition
Jun 30, 2023


With the rise of bidirectional encoder representations from Transformer models in natural language processing, the speech community has adopted some of their development methodologies. Therefore, the Wav2Vec models were introduced to reduce the data required to obtain state-of-the-art results. This work leverages this knowledge and improves the performance of the pre-trained speech models by simply replacing the fine-tuning dense layer with a lateral inhibition layer inspired by the biological process. Our experiments on Romanian, a low-resource language, show an average improvement of 12.5% word error rate (WER) using the lateral inhibition layer. In addition, we obtain state-of-the-art results on both the Romanian Speech Corpus and the Robin Technical Acquisition Corpus with 1.78% WER and 29.64% WER, respectively.
Multilingual Multiword Expression Identification Using Lateral Inhibition and Domain Adaptation
Jun 17, 2023Correctly identifying multiword expressions (MWEs) is an important task for most natural language processing systems since their misidentification can result in ambiguity and misunderstanding of the underlying text. In this work, we evaluate the performance of the mBERT model for MWE identification in a multilingual context by training it on all 14 languages available in version 1.2 of the PARSEME corpus. We also incorporate lateral inhibition and language adversarial training into our methodology to create language-independent embeddings and improve its capabilities in identifying multiword expressions. The evaluation of our models shows that the approach employed in this work achieves better results compared to the best system of the PARSEME 1.2 competition, MTLB-STRUCT, on 11 out of 14 languages for global MWE identification and on 12 out of 14 languages for unseen MWE identification. Additionally, averaged across all languages, our best approach outperforms the MTLB-STRUCT system by 1.23% on global MWE identification and by 4.73% on unseen global MWE identification.
Adversarial Capsule Networks for Romanian Satire Detection and Sentiment Analysis
Jun 13, 2023Satire detection and sentiment analysis are intensively explored natural language processing (NLP) tasks that study the identification of the satirical tone from texts and extracting sentiments in relationship with their targets. In languages with fewer research resources, an alternative is to produce artificial examples based on character-level adversarial processes to overcome dataset size limitations. Such samples are proven to act as a regularization method, thus improving the robustness of models. In this work, we improve the well-known NLP models (i.e., Convolutional Neural Networks, Long Short-Term Memory (LSTM), Bidirectional LSTM, Gated Recurrent Units (GRUs), and Bidirectional GRUs) with adversarial training and capsule networks. The fine-tuned models are used for satire detection and sentiment analysis tasks in the Romanian language. The proposed framework outperforms the existing methods for the two tasks, achieving up to 99.08% accuracy, thus confirming the improvements added by the capsule layers and the adversarial training in NLP approaches.
RoBERTweet: A BERT Language Model for Romanian Tweets
Jun 11, 2023Developing natural language processing (NLP) systems for social media analysis remains an important topic in artificial intelligence research. This article introduces RoBERTweet, the first Transformer architecture trained on Romanian tweets. Our RoBERTweet comes in two versions, following the base and large architectures of BERT. The corpus used for pre-training the models represents a novelty for the Romanian NLP community and consists of all tweets collected from 2008 to 2022. Experiments show that RoBERTweet models outperform the previous general-domain Romanian and multilingual language models on three NLP tasks with tweet inputs: emotion detection, sexist language identification, and named entity recognition. We make our models and the newly created corpus of Romanian tweets freely available.