 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAF: Graph Retrieval Augmented by Facts for Legal Question Answering
Dec 05, 2024
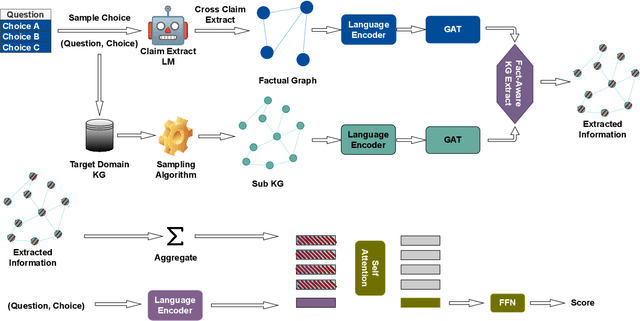

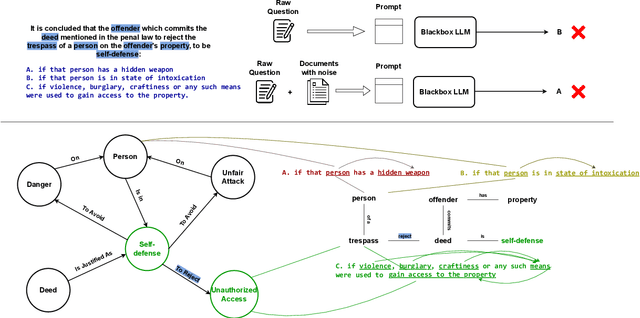
Pre-trained Language Models (PLMs) have shown remarkable performances in recent years, setting a new paradigm for NLP research and industry. The legal domain has received some attention from the NLP community partly due to its textual nature. Some tasks from this domain are represented by question-answering (QA) tasks. This work explores the legal domain Multiple-Choice QA (MCQA) for a low-resource language. The contribution of this work is multi-fold. We first introduce JuRO, the first openly available Romanian legal MCQA dataset, comprising three different examinations and a number of 10,836 total questions. Along with this dataset, we introduce CROL, an organized corpus of laws that has a total of 93 distinct documents with their modifications from 763 time spans, that we leveraged in this work for Information Retrieval (IR) techniques. Moreover, we are the first to propose Law-RoG, a Knowledge Graph (KG) for the Romanian language, and this KG is derived from the aforementioned corpus. Lastly, we propose a novel approach for MCQA, Graph Retrieval Augmented by Facts (GRAF), which achieves competitive results with generally accepted SOTA methods and even exceeds them in most settings.
RoQLlama: A Lightweight Romanian Adapted Language Model
Oct 05, 2024
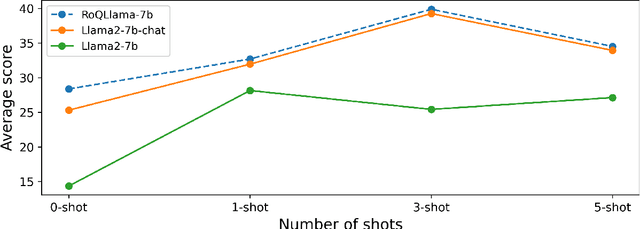

The remarkable achievements obtained by open-source large language models (LLMs) in recent years have predominantly been concentrated on tasks involving the English language. In this paper, we aim to advance the performance of Llama2 models on Romanian tasks. We tackle the problem of reduced computing resources by using QLoRA for training. We release RoQLlama-7b, a quantized LLM, which shows equal or improved results compared to its full-sized counterpart when tested on seven Romanian downstream tasks in the zero-shot setup. Also, it consistently achieves higher average scores across all few-shot prompts. Additionally, we introduce a novel Romanian dataset, namely RoMedQA, which contains single-choice medical questions in Romanian.