 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Multiword Expression Identification Using Lateral Inhibition and Domain Adaptation
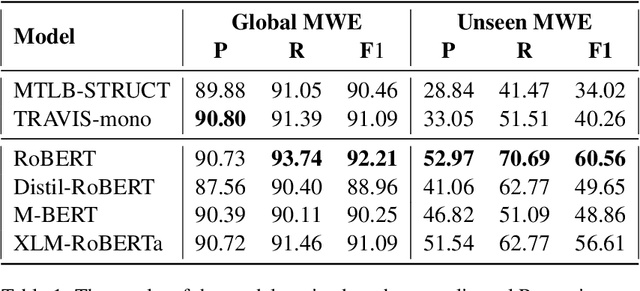
Jun 17, 2023Correctly identifying multiword expressions (MWEs) is an important task for most natural language processing systems since their misidentification can result in ambiguity and misunderstanding of the underlying text. In this work, we evaluate the performance of the mBERT model for MWE identification in a multilingual context by training it on all 14 languages available in version 1.2 of the PARSEME corpus. We also incorporate lateral inhibition and language adversarial training into our methodology to create language-independent embeddings and improve its capabilities in identifying multiword expressions. The evaluation of our models shows that the approach employed in this work achieves better results compared to the best system of the PARSEME 1.2 competition, MTLB-STRUCT, on 11 out of 14 languages for global MWE identification and on 12 out of 14 languages for unseen MWE identification. Additionally, averaged across all languages, our best approach outperforms the MTLB-STRUCT system by 1.23% on global MWE identification and by 4.73% on unseen global MWE identification.
Romanian Multiword Expression Detection Using Multilingual Adversarial Training and Lateral Inhibition
Apr 22, 2023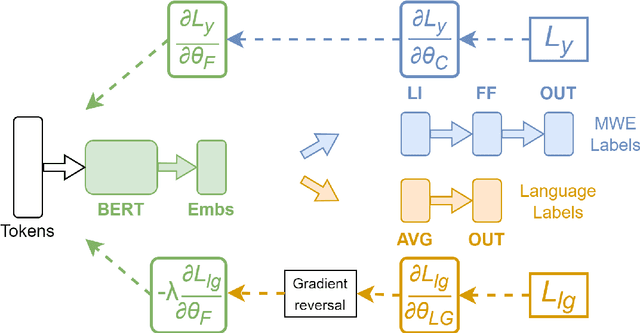
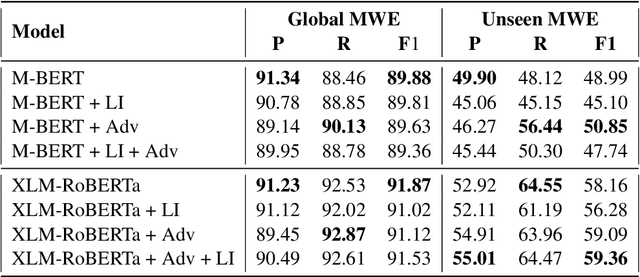
Multiword expressions are a key ingredient for developing large-scale and linguistically sound natural language processing technology. This paper describes our improvements in automatically identifying Romanian multiword expressions on the corpus released for the PARSEME v1.2 shared task. Our approach assumes a multilingual perspective based on the recently introduced lateral inhibition layer and adversarial training to boost the performance of the employed multilingual language models. With the help of these two methods, we improve the F1-score of XLM-RoBERTa by approximately 2.7% on unseen multiword expressions, the main task of the PARSEME 1.2 edition. In addition, our results can be considered SOTA performance, as they outperform the previous results on Romanian obtained by the participants in this competition.
An Open-Domain QA System for e-Governance
Jun 16, 2022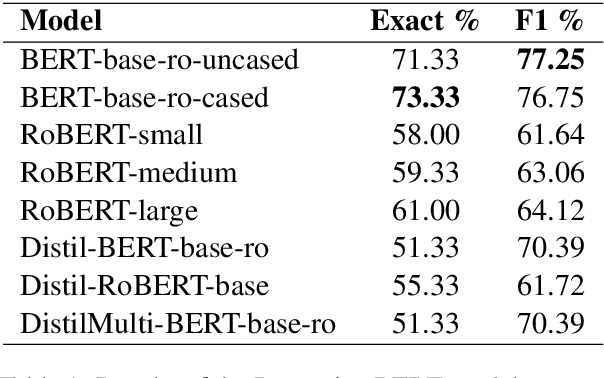
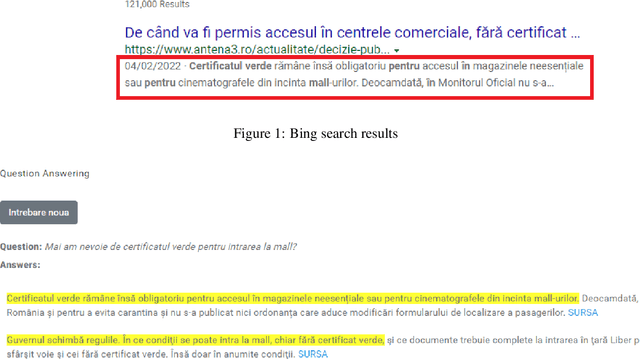
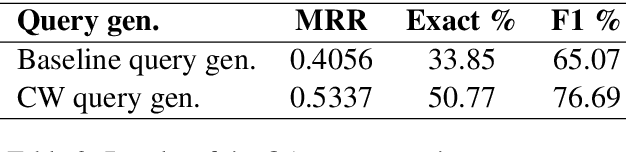
The paper presents an open-domain Question Answering system for Romanian, answering COVID-19 related questions. The QA system pipeline involves automatic question processing, automatic query generation, web searching for the top 10 most relevant documents and answer extraction using a fine-tuned BERT model for Extractive QA, trained on a COVID-19 data set that we have manually created. The paper will present the QA system and its integration with the Romanian language technologies portal RELATE, the COVID-19 data set and different evaluations of the QA performance.
Human-Machine Interaction Speech Corpus from the ROBIN project
Nov 22, 2021
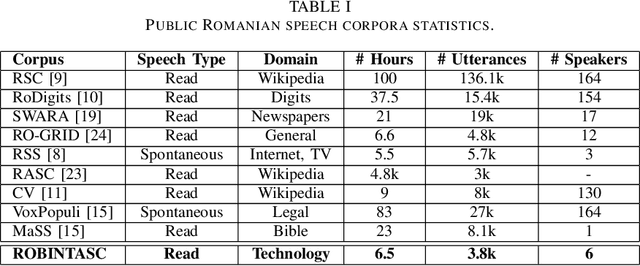
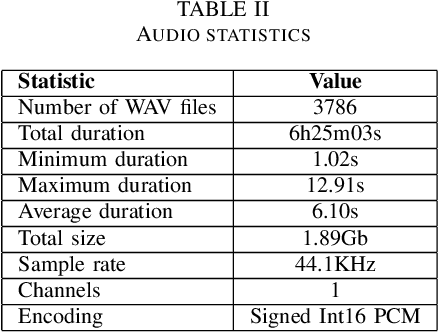
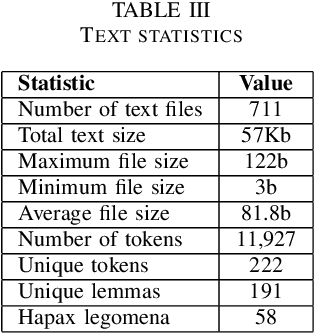
This paper introduces a new Romanian speech corpus from the ROBIN project, called ROBIN Technical Acquisition Speech Corpus (ROBINTASC). Its main purpose was to improve the behaviour of a conversational agent, allowing human-machine interaction in the context of purchasing technical equipment. The paper contains a detailed description of the acquisition process, corpus statistics as well as an evaluation of the corpus influence on a low-latency ASR system as well as a dialogue component.
* V. P\u{a}i\c{s}, R. Ion, A. -M. Avram, E. Irimia, V. B. Mititelu and M. Mitrofan, "Human-Machine Interaction Speech Corpus from the ROBIN project", Proceedings of the 2021 International Conference on Speech Technology and Human-Computer Dialogue (SpeD), 2021, pp. 91-96