 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRELATE: A Modern Processing Platform for Romanian Language
Oct 29, 2024This paper presents the design and evolution of the RELATE platform. It provides a high-performance environment for natural language processing activities, specially constructed for Romanian language. Initially developed for text processing, it has been recently updated to integrate audio processing tools. Technical details are provided with regard to core components. We further present different usage scenarios, derived from actual use in national and international research projects, thus demonstrating that RELATE is a mature, modern, state-of-the-art platform for processing Romanian language corpora. Finally, we present very recent developments including bimodal (text and audio) features available within the platform.
Towards Improving the Performance of Pre-Trained Speech Models for Low-Resource Languages Through Lateral Inhibition
Jun 30, 2023


With the rise of bidirectional encoder representations from Transformer models in natural language processing, the speech community has adopted some of their development methodologies. Therefore, the Wav2Vec models were introduced to reduce the data required to obtain state-of-the-art results. This work leverages this knowledge and improves the performance of the pre-trained speech models by simply replacing the fine-tuning dense layer with a lateral inhibition layer inspired by the biological process. Our experiments on Romanian, a low-resource language, show an average improvement of 12.5% word error rate (WER) using the lateral inhibition layer. In addition, we obtain state-of-the-art results on both the Romanian Speech Corpus and the Robin Technical Acquisition Corpus with 1.78% WER and 29.64% WER, respectively.
An Open-Domain QA System for e-Governance
Jun 16, 2022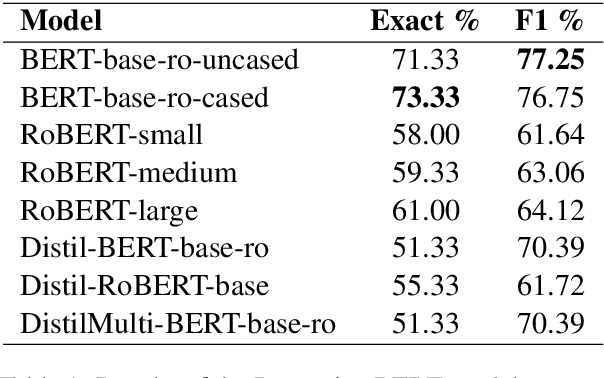
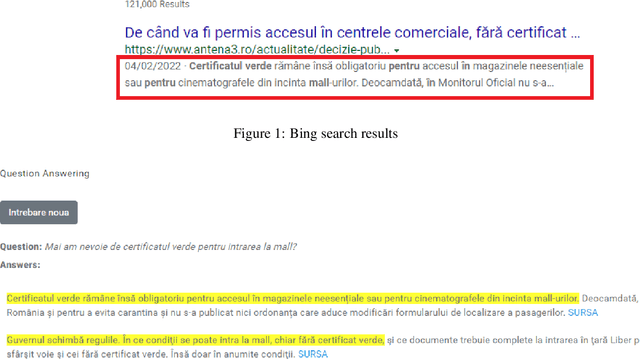
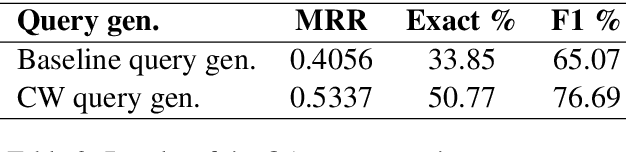
The paper presents an open-domain Question Answering system for Romanian, answering COVID-19 related questions. The QA system pipeline involves automatic question processing, automatic query generation, web searching for the top 10 most relevant documents and answer extraction using a fine-tuned BERT model for Extractive QA, trained on a COVID-19 data set that we have manually created. The paper will present the QA system and its integration with the Romanian language technologies portal RELATE, the COVID-19 data set and different evaluations of the QA performance.
Human-Machine Interaction Speech Corpus from the ROBIN project
Nov 22, 2021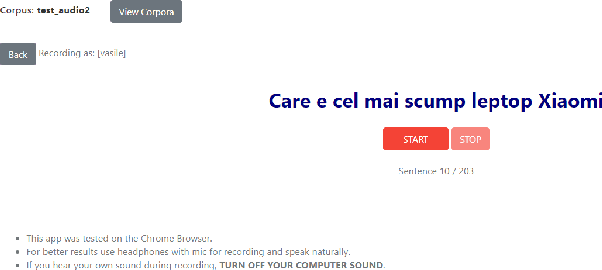
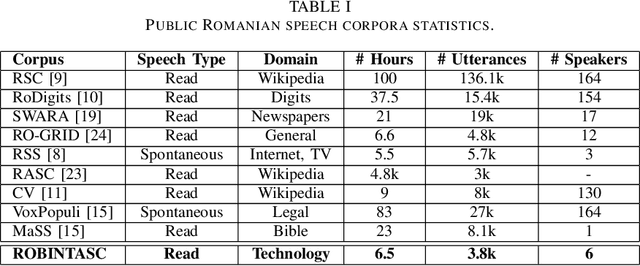
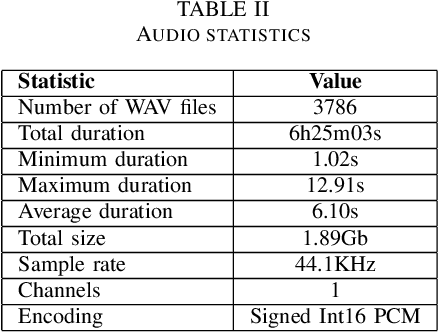
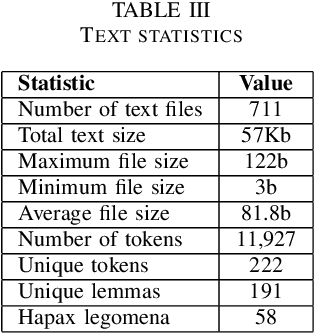
This paper introduces a new Romanian speech corpus from the ROBIN project, called ROBIN Technical Acquisition Speech Corpus (ROBINTASC). Its main purpose was to improve the behaviour of a conversational agent, allowing human-machine interaction in the context of purchasing technical equipment. The paper contains a detailed description of the acquisition process, corpus statistics as well as an evaluation of the corpus influence on a low-latency ASR system as well as a dialogue component.
* V. P\u{a}i\c{s}, R. Ion, A. -M. Avram, E. Irimia, V. B. Mititelu and M. Mitrofan, "Human-Machine Interaction Speech Corpus from the ROBIN project", Proceedings of the 2021 International Conference on Speech Technology and Human-Computer Dialogue (SpeD), 2021, pp. 91-96
Fine-Grained Word Sense Disambiguation Based on Parallel Corpora, Word Alignment, Word Clustering and Aligned Wordnets
Mar 10, 2005

The paper presents a method for word sense disambiguation based on parallel corpora. The method exploits recent advances in word alignment and word clustering based on automatic extraction of translation equivalents and being supported by available aligned wordnets for the languages in the corpus. The wordnets are aligned to the Princeton Wordnet, according to the principles established by EuroWordNet. The evaluation of the WSD system, implementing the method described herein showed very encouraging results. The same system used in a validation mode, can be used to check and spot alignment errors in multilingually aligned wordnets as BalkaNet and EuroWordNet.
* 7 pages in Proc. of COLING2005