 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyEuroVoc: A Tool for Multilingual Legal Document Classification with EuroVoc Descriptors
Aug 10, 2021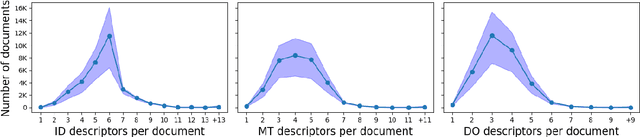
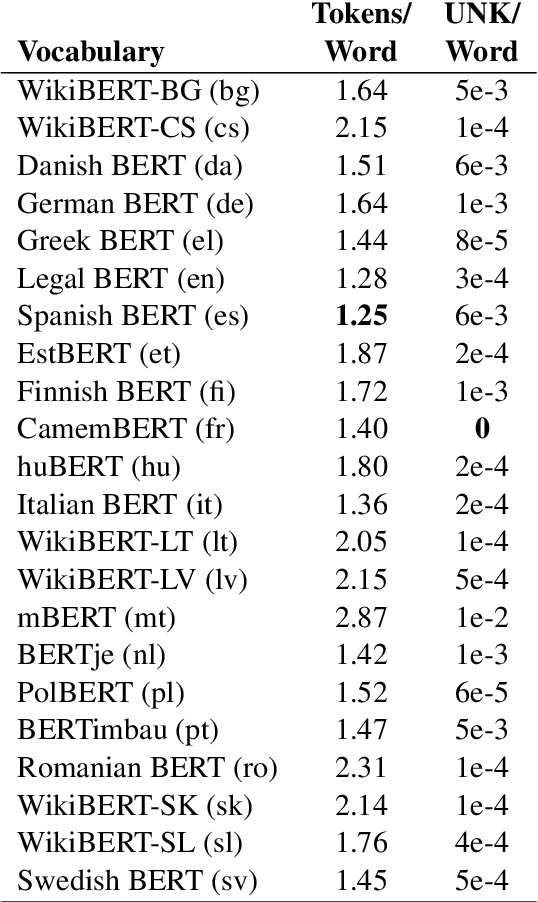
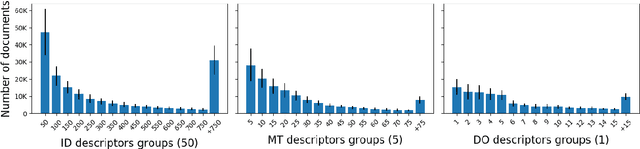
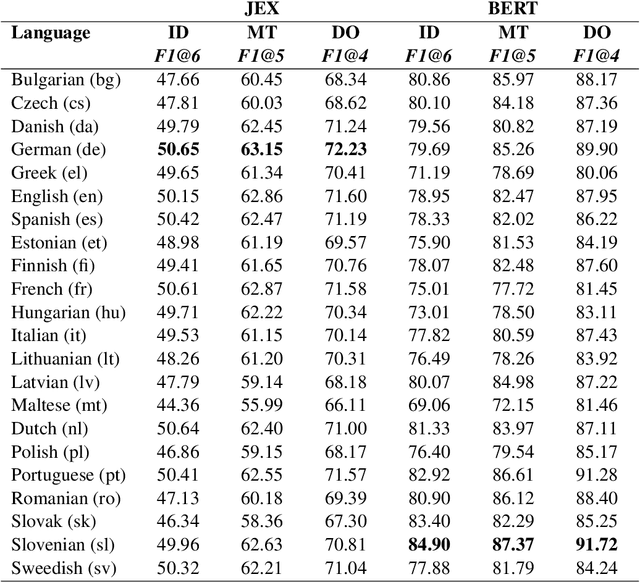
EuroVoc is a multilingual thesaurus that was built for organizing the legislative documentary of the European Union institutions. It contains thousands of categories at different levels of specificity and its descriptors are targeted by legal texts in almost thirty languages. In this work we propose a unified framework for EuroVoc classification on 22 languages by fine-tuning modern Transformer-based pretrained language models. We study extensively the performance of our trained models and show that they significantly improve the results obtained by a similar tool - JEX - on the same dataset. The code and the fine-tuned models were open sourced, together with a programmatic interface that eases the process of loading the weights of a trained model and of classifying a new document.
The JRC-Acquis: A multilingual aligned parallel corpus with 20+ languages
Sep 12, 2006

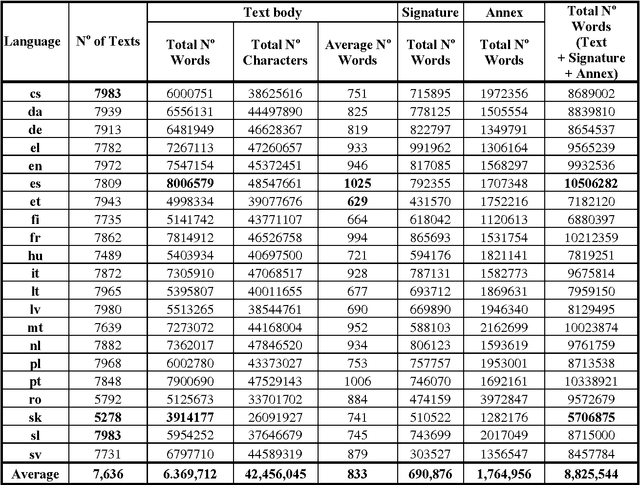

We present a new, unique and freely available parallel corpus containing European Union (EU) documents of mostly legal nature. It is available in all 20 official EUanguages, with additional documents being available in the languages of the EU candidate countries. The corpus consists of almost 8,000 documents per language, with an average size of nearly 9 million words per language. Pair-wise paragraph alignment information produced by two different aligners (Vanilla and HunAlign) is available for all 190+ language pair combinations. Most texts have been manually classified according to the EUROVOC subject domains so that the collection can also be used to train and test multi-label classification algorithms and keyword-assignment software. The corpus is encoded in XML, according to the Text Encoding Initiative Guidelines. Due to the large number of parallel texts in many languages, the JRC-Acquis is particularly suitable to carry out all types of cross-language research, as well as to test and benchmark text analysis software across different languages (for instance for alignment, sentence splitting and term extraction).
* A multilingual textual resource with meta-data freely available for download at http://langtech.jrc.it/JRC-Acquis.html
Fine-Grained Word Sense Disambiguation Based on Parallel Corpora, Word Alignment, Word Clustering and Aligned Wordnets
Mar 10, 2005

The paper presents a method for word sense disambiguation based on parallel corpora. The method exploits recent advances in word alignment and word clustering based on automatic extraction of translation equivalents and being supported by available aligned wordnets for the languages in the corpus. The wordnets are aligned to the Princeton Wordnet, according to the principles established by EuroWordNet. The evaluation of the WSD system, implementing the method described herein showed very encouraging results. The same system used in a validation mode, can be used to check and spot alignment errors in multilingually aligned wordnets as BalkaNet and EuroWordNet.
* 7 pages in Proc. of COLING2005