 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Common XML-based Framework for Syntactic Annotations
Sep 15, 2009

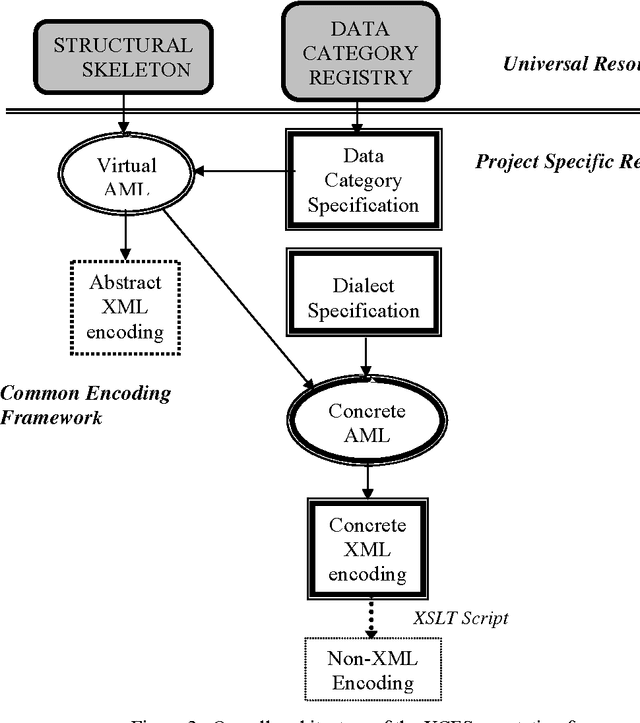
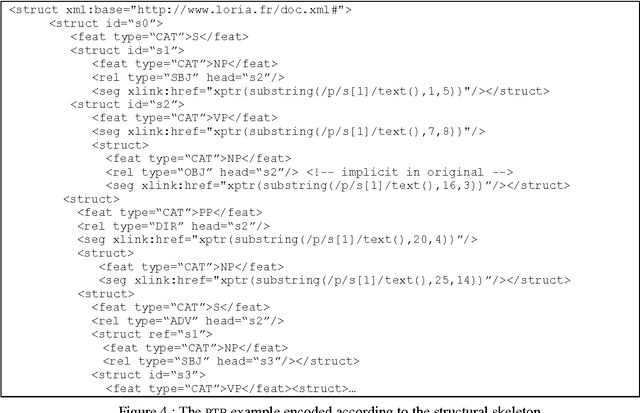
It is widely recognized that the proliferation of annotation schemes runs counter to the need to re-use language resources, and that standards for linguistic annotation are becoming increasingly mandatory. To answer this need, we have developed a framework comprised of an abstract model for a variety of different annotation types (e.g., morpho-syntactic tagging, syntactic annotation, co-reference annotation, etc.), which can be instantiated in different ways depending on the annotator's approach and goals. In this paper we provide an overview of the framework, demonstrate its applicability to syntactic annotation, and show how it can contribute to comparative evaluation of parser output and diverse syntactic annotation schemes.
* Colloque avec actes et comit\'e de lecture. internationale
A tool set for the quick and efficient exploration of large document collections
Sep 12, 2006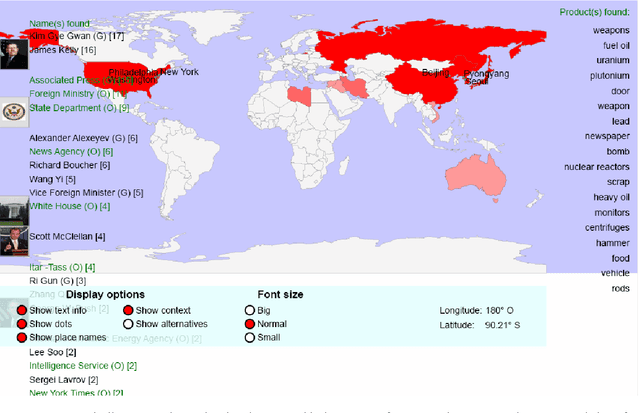



We are presenting a set of multilingual text analysis tools that can help analysts in any field to explore large document collections quickly in order to determine whether the documents contain information of interest, and to find the relevant text passages. The automatic tool, which currently exists as a fully functional prototype, is expected to be particularly useful when users repeatedly have to sieve through large collections of documents such as those downloaded automatically from the internet. The proposed system takes a whole document collection as input. It first carries out some automatic analysis tasks (named entity recognition, geo-coding, clustering, term extraction), annotates the texts with the generated meta-information and stores the meta-information in a database. The system then generates a zoomable and hyperlinked geographic map enhanced with information on entities and terms found. When the system is used on a regular basis, it builds up a historical database that contains information on which names have been mentioned together with which other names or places, and users can query this database to retrieve information extracted in the past.
* 10 pages
The JRC-Acquis: A multilingual aligned parallel corpus with 20+ languages
Sep 12, 2006

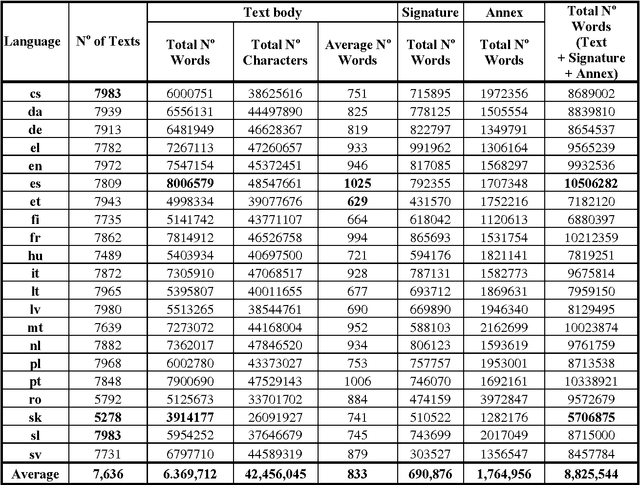

We present a new, unique and freely available parallel corpus containing European Union (EU) documents of mostly legal nature. It is available in all 20 official EUanguages, with additional documents being available in the languages of the EU candidate countries. The corpus consists of almost 8,000 documents per language, with an average size of nearly 9 million words per language. Pair-wise paragraph alignment information produced by two different aligners (Vanilla and HunAlign) is available for all 190+ language pair combinations. Most texts have been manually classified according to the EUROVOC subject domains so that the collection can also be used to train and test multi-label classification algorithms and keyword-assignment software. The corpus is encoded in XML, according to the Text Encoding Initiative Guidelines. Due to the large number of parallel texts in many languages, the JRC-Acquis is particularly suitable to carry out all types of cross-language research, as well as to test and benchmark text analysis software across different languages (for instance for alignment, sentence splitting and term extraction).
* A multilingual textual resource with meta-data freely available for download at http://langtech.jrc.it/JRC-Acquis.html