 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrame of Reference: Addressing the Challenges of Common Ground Representation in Situational Dialogs
Jan 14, 2026Common ground plays a critical role in situated spoken dialogues, where interlocutors must establish and maintain shared references to entities, events, and relations to sustain coherent interaction. For dialog systems, the ability to correctly ground conversational content in order to refer back to it later is particularly important. Prior studies have demonstrated that LLMs are capable of performing grounding acts such as requesting clarification or producing acknowledgments, yet relatively little work has investigated how common ground can be explicitly represented and stored for later use. Without such mechanisms, it remains unclear whether acknowledgment or clarification behaviors truly reflect a grounded understanding. In this work, we evaluate a model's ability to establish and exploit common ground through relational references to entities within the shared context in a situational dialogue. We test multiple methods for representing common ground in situated dialogues and further propose approaches to improve both the establishment of common ground and its subsequent use in the conversation.
Diachronic Document Dataset for Semantic Layout Analysis
Nov 15, 2024



We present a novel, open-access dataset designed for semantic layout analysis, built to support document recreation workflows through mapping with the Text Encoding Initiative (TEI) standard. This dataset includes 7,254 annotated pages spanning a large temporal range (1600-2024) of digitised and born-digital materials across diverse document types (magazines, papers from sciences and humanities, PhD theses, monographs, plays, administrative reports, etc.) sorted into modular subsets. By incorporating content from different periods and genres, it addresses varying layout complexities and historical changes in document structure. The modular design allows domain-specific configurations. We evaluate object detection models on this dataset, examining the impact of input size and subset-based training. Results show that a 1280-pixel input size for YOLO is optimal and that training on subsets generally benefits from incorporating them into a generic model rather than fine-tuning pre-trained weights.
Harvesting Textual and Structured Data from the HAL Publication Repository
Jul 30, 2024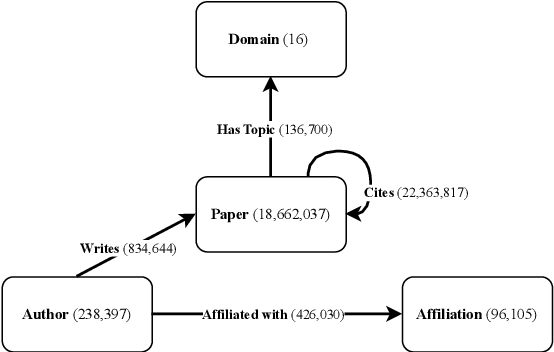



HAL (Hyper Articles en Ligne) is the French national publication repository, used by most higher education and research organizations for their open science policy. As a digital library, it is a rich repository of scholarly documents, but its potential for advanced research has been underutilized. We present HALvest, a unique dataset that bridges the gap between citation networks and the full text of papers submitted on HAL. We craft our dataset by filtering HAL for scholarly publications, resulting in approximately 700,000 documents, spanning 34 languages across 13 identified domains, suitable for language model training, and yielding approximately 16.5 billion tokens (with 8 billion in French and 7 billion in English, the most represented languages). We transform the metadata of each paper into a citation network, producing a directed heterogeneous graph. This graph includes uniquely identified authors on HAL, as well as all open submitted papers, and their citations. We provide a baseline for authorship attribution using the dataset, implement a range of state-of-the-art models in graph representation learning for link prediction, and discuss the usefulness of our generated knowledge graph structure.
Conversational Grounding: Annotation and Analysis of Grounding Acts and Grounding Units
Mar 25, 2024


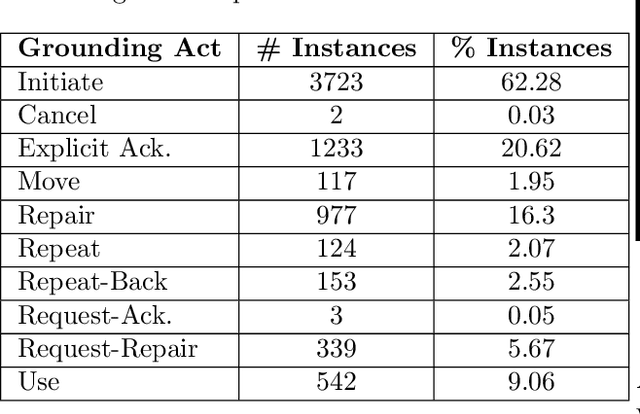
Successful conversations often rest on common understanding, where all parties are on the same page about the information being shared. This process, known as conversational grounding, is crucial for building trustworthy dialog systems that can accurately keep track of and recall the shared information. The proficiencies of an agent in grounding the conveyed information significantly contribute to building a reliable dialog system. Despite recent advancements in dialog systems, there exists a noticeable deficit in their grounding capabilities. Traum provided a framework for conversational grounding introducing Grounding Acts and Grounding Units, but substantial progress, especially in the realm of Large Language Models, remains lacking. To bridge this gap, we present the annotation of two dialog corpora employing Grounding Acts, Grounding Units, and a measure of their degree of grounding. We discuss our key findings during the annotation and also provide a baseline model to test the performance of current Language Models in categorizing the grounding acts of the dialogs. Our work aims to provide a useful resource for further research in making conversations with machines better understood and more reliable in natural day-to-day collaborative dialogs.
CamemBERT-bio: a Tasty French Language Model Better for your Health
Jun 27, 2023



Clinical data in hospitals are increasingly accessible for research through clinical data warehouses, however these documents are unstructured. It is therefore necessary to extract information from medical reports to conduct clinical studies. Transfer learning with BERT-like models such as CamemBERT has allowed major advances, especially for named entity recognition. However, these models are trained for plain language and are less efficient on biomedical data. This is why we propose a new French public biomedical dataset on which we have continued the pre-training of CamemBERT. Thus, we introduce a first version of CamemBERT-bio, a specialized public model for the French biomedical domain that shows 2.54 points of F1 score improvement on average on different biomedical named entity recognition tasks.
Towards a Cleaner Document-Oriented Multilingual Crawled Corpus
Jan 17, 2022



The need for raw large raw corpora has dramatically increased in recent years with the introduction of transfer learning and semi-supervised learning methods to Natural Language Processing. And while there have been some recent attempts to manually curate the amount of data necessary to train large language models, the main way to obtain this data is still through automatic web crawling. In this paper we take the existing multilingual web corpus OSCAR and its pipeline Ungoliant that extracts and classifies data from Common Crawl at the line level, and propose a set of improvements and automatic annotations in order to produce a new document-oriented version of OSCAR that could prove more suitable to pre-train large generative language models as well as hopefully other applications in Natural Language Processing and Digital Humanities.
A Monolingual Approach to Contextualized Word Embeddings for Mid-Resource Languages
Jun 18, 2020
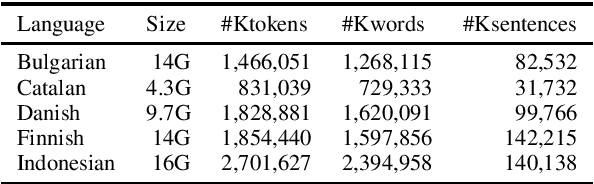

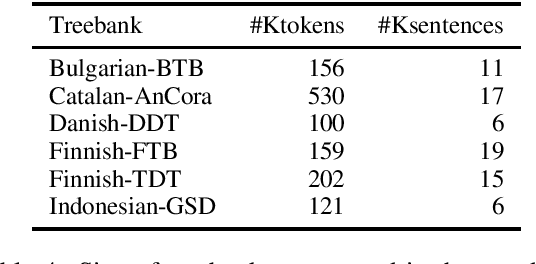
We use the multilingual OSCAR corpus, extracted from Common Crawl via language classification, filtering and cleaning, to train monolingual contextualized word embeddings (ELMo) for five mid-resource languages. We then compare the performance of OSCAR-based and Wikipedia-based ELMo embeddings for these languages on the part-of-speech tagging and parsing tasks. We show that, despite the noise in the Common-Crawl-based OSCAR data, embeddings trained on OSCAR perform much better than monolingual embeddings trained on Wikipedia. They actually equal or improve the current state of the art in tagging and parsing for all five languages. In particular, they also improve over multilingual Wikipedia-based contextual embeddings (multilingual BERT), which almost always constitutes the previous state of the art, thereby showing that the benefit of a larger, more diverse corpus surpasses the cross-lingual benefit of multilingual embedding architectures.
Establishing a New State-of-the-Art for French Named Entity Recognition
May 27, 2020
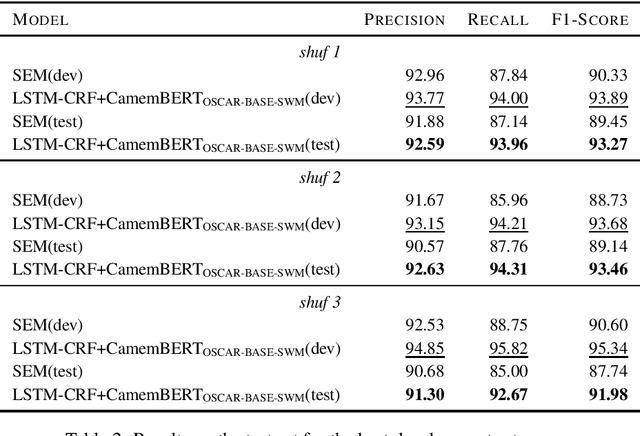
The French TreeBank developed at the University Paris 7 is the main source of morphosyntactic and syntactic annotations for French. However, it does not include explicit information related to named entities, which are among the most useful information for several natural language processing tasks and applications. Moreover, no large-scale French corpus with named entity annotations contain referential information, which complement the type and the span of each mention with an indication of the entity it refers to. We have manually annotated the French TreeBank with such information, after an automatic pre-annotation step. We sketch the underlying annotation guidelines and we provide a few figures about the resulting annotations.
CamemBERT: a Tasty French Language Model
Nov 10, 2019



Pretrained language models are now ubiquitous in Natural Language Processing. Despite their success, most available models have either been trained on English data or on the concatenation of data in multiple languages. This makes practical use of such models --in all languages except English-- very limited. Aiming to address this issue for French, we release CamemBERT, a French version of the Bi-directional Encoders for Transformers (BERT). We measure the performance of CamemBERT compared to multilingual models in multiple downstream tasks, namely part-of-speech tagging, dependency parsing, named-entity recognition, and natural language inference. CamemBERT improves the state of the art for most of the tasks considered. We release the pretrained model for CamemBERT hoping to foster research and downstream applications for French NLP.
LMF Reloaded
May 23, 2019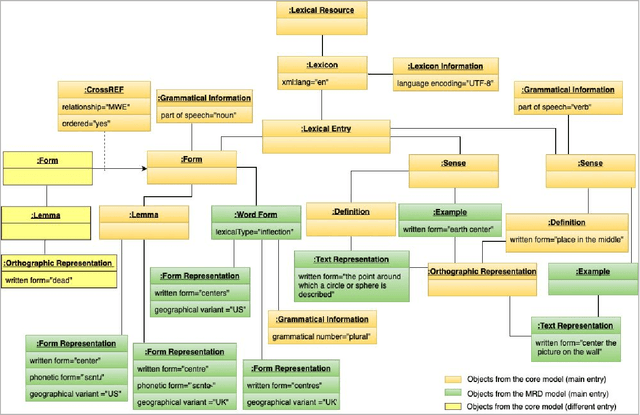
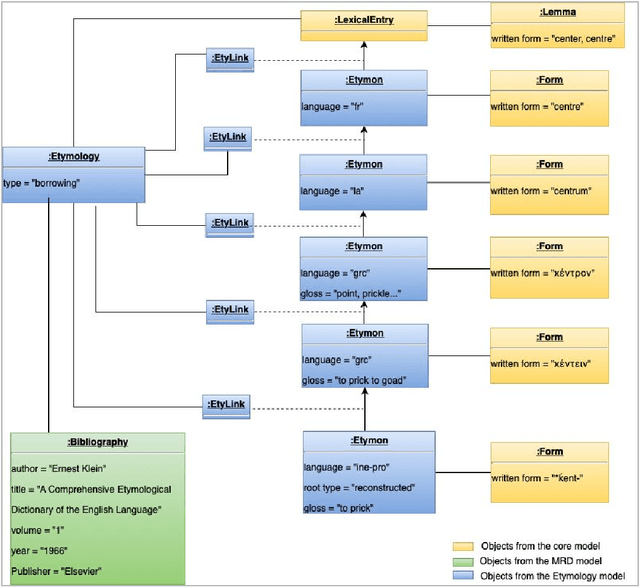

Lexical Markup Framework (LMF) or ISO 24613 [1] is a de jure standard that provides a framework for modelling and encoding lexical information in retrodigitised print dictionaries and NLP lexical databases. An in-depth review is currently underway within the standardisation subcommittee , ISO-TC37/SC4/WG4, to find a more modular, flexible and durable follow up to the original LMF standard published in 2008. In this paper we will present some of the major improvements which have so far been implemented in the new version of LMF.