 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling meaning from language in LLM-based machine translation
Feb 04, 2026Mechanistic Interpretability (MI) seeks to explain how neural networks implement their capabilities, but the scale of Large Language Models (LLMs) has limited prior MI work in Machine Translation (MT) to word-level analyses. We study sentence-level MT from a mechanistic perspective by analyzing attention heads to understand how LLMs internally encode and distribute translation functions. We decompose MT into two subtasks: producing text in the target language (i.e. target language identification) and preserving the input sentence's meaning (i.e. sentence equivalence). Across three families of open-source models and 20 translation directions, we find that distinct, sparse sets of attention heads specialize in each subtask. Based on this insight, we construct subtask-specific steering vectors and show that modifying just 1% of the relevant heads enables instruction-free MT performance comparable to instruction-based prompting, while ablating these heads selectively disrupts their corresponding translation functions.
CommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
When the Gold Standard isn't Necessarily Standard: Challenges of Evaluating the Translation of User-Generated Content
Dec 19, 2025



User-generated content (UGC) is characterised by frequent use of non-standard language, from spelling errors to expressive choices such as slang, character repetitions, and emojis. This makes evaluating UGC translation particularly challenging: what counts as a "good" translation depends on the level of standardness desired in the output. To explore this, we examine the human translation guidelines of four UGC datasets, and derive a taxonomy of twelve non-standard phenomena and five translation actions (NORMALISE, COPY, TRANSFER, OMIT, CENSOR). Our analysis reveals notable differences in how UGC is treated, resulting in a spectrum of standardness in reference translations. Through a case study on large language models (LLMs), we show that translation scores are highly sensitive to prompts with explicit translation instructions for UGC, and that they improve when these align with the dataset's guidelines. We argue that when preserving UGC style is important, fair evaluation requires both models and metrics to be aware of translation guidelines. Finally, we call for clear guidelines during dataset creation and for the development of controllable, guideline-aware evaluation frameworks for UGC translation.
Gaperon: A Peppered English-French Generative Language Model Suite
Oct 29, 2025We release Gaperon, a fully open suite of French-English-coding language models designed to advance transparency and reproducibility in large-scale model training. The Gaperon family includes 1.5B, 8B, and 24B parameter models trained on 2-4 trillion tokens, released with all elements of the training pipeline: French and English datasets filtered with a neural quality classifier, an efficient data curation and training framework, and hundreds of intermediate checkpoints. Through this work, we study how data filtering and contamination interact to shape both benchmark and generative performance. We find that filtering for linguistic quality enhances text fluency and coherence but yields subpar benchmark results, and that late deliberate contamination -- continuing training on data mixes that include test sets -- recovers competitive scores while only reasonably harming generation quality. We discuss how usual neural filtering can unintentionally amplify benchmark leakage. To support further research, we also introduce harmless data poisoning during pretraining, providing a realistic testbed for safety studies. By openly releasing all models, datasets, code, and checkpoints, Gaperon establishes a reproducible foundation for exploring the trade-offs between data curation, evaluation, safety, and openness in multilingual language model development.
TopXGen: Topic-Diverse Parallel Data Generation for Low-Resource Machine Translation
Aug 12, 2025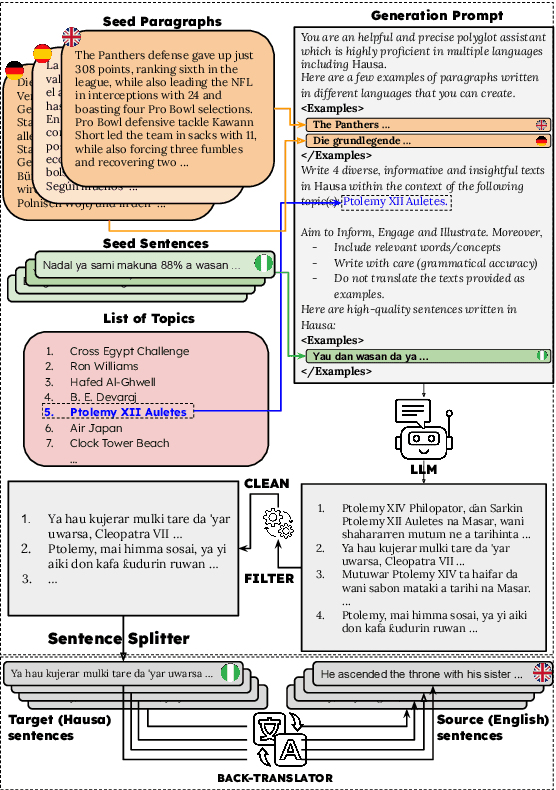

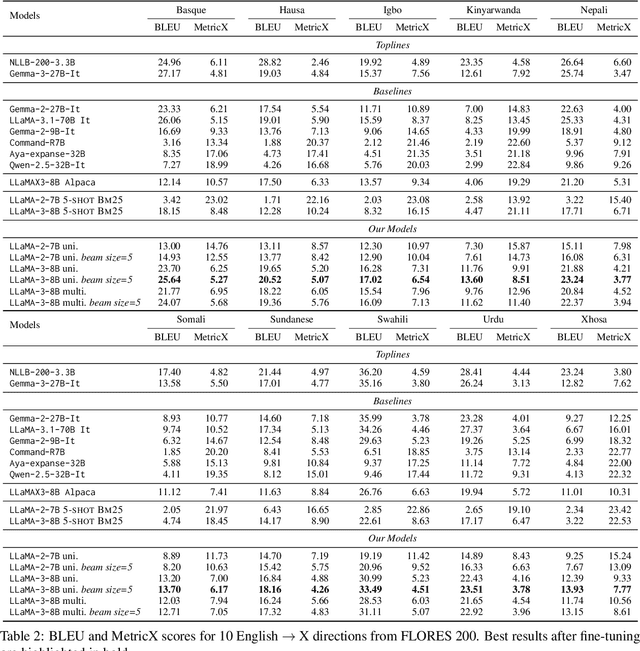
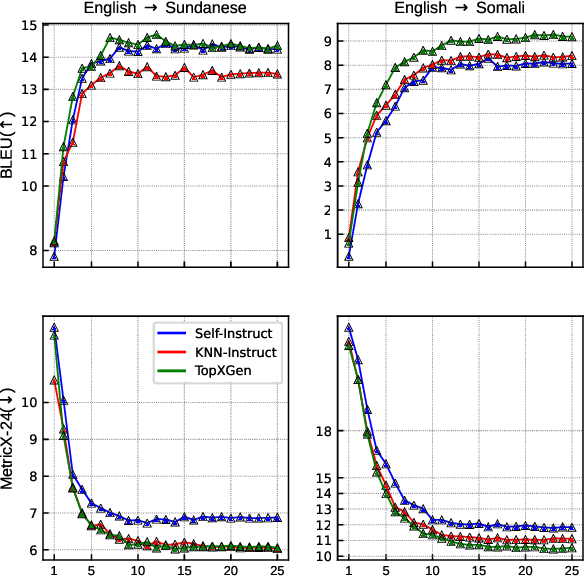
LLMs have been shown to perform well in machine translation (MT) with the use of in-context learning (ICL), rivaling supervised models when translating into high-resource languages (HRLs). However, they lag behind when translating into low-resource language (LRLs). Example selection via similarity search and supervised fine-tuning help. However the improvements they give are limited by the size, quality and diversity of existing parallel datasets. A common technique in low-resource MT is synthetic parallel data creation, the most frequent of which is backtranslation, whereby existing target-side texts are automatically translated into the source language. However, this assumes the existence of good quality and relevant target-side texts, which are not readily available for many LRLs. In this paper, we present \textsc{TopXGen}, an LLM-based approach for the generation of high quality and topic-diverse data in multiple LRLs, which can then be backtranslated to produce useful and diverse parallel texts for ICL and fine-tuning. Our intuition is that while LLMs struggle to translate into LRLs, their ability to translate well into HRLs and their multilinguality enable them to generate good quality, natural-sounding target-side texts, which can be translated well into a high-resource source language. We show that \textsc{TopXGen} boosts LLM translation performance during fine-tuning and in-context learning. Code and outputs are available at https://github.com/ArmelRandy/topxgen.
ModernBERT or DeBERTaV3? Examining Architecture and Data Influence on Transformer Encoder Models Performance
Apr 11, 2025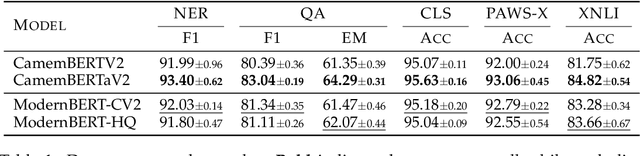
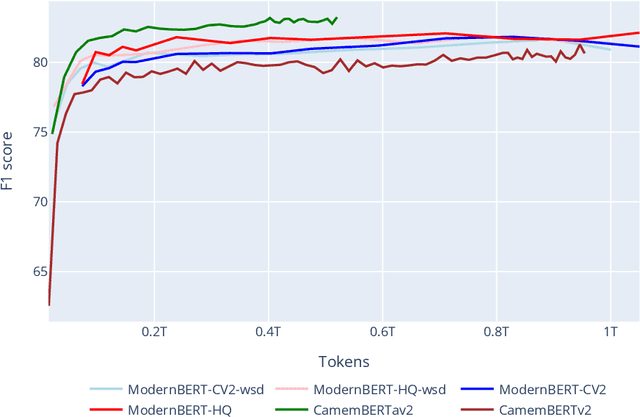
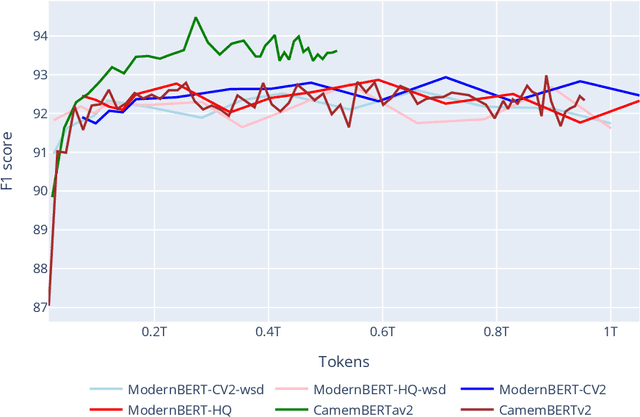
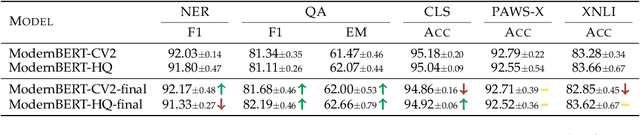
Pretrained transformer-encoder models like DeBERTaV3 and ModernBERT introduce architectural advancements aimed at improving efficiency and performance. Although the authors of ModernBERT report improved performance over DeBERTaV3 on several benchmarks, the lack of disclosed training data and the absence of comparisons using a shared dataset make it difficult to determine whether these gains are due to architectural improvements or differences in training data. In this work, we conduct a controlled study by pretraining ModernBERT on the same dataset as CamemBERTaV2, a DeBERTaV3 French model, isolating the effect of model design. Our results show that the previous model generation remains superior in sample efficiency and overall benchmark performance, with ModernBERT's primary advantage being faster training and inference speed. However, the new proposed model still provides meaningful architectural improvements compared to earlier models such as BERT and RoBERTa. Additionally, we observe that high-quality pre-training data accelerates convergence but does not significantly improve final performance, suggesting potential benchmark saturation. These findings show the importance of disentangling pretraining data from architectural innovations when evaluating transformer models.
Explicit Learning and the LLM in Machine Translation
Mar 12, 2025



This study explores the capacity of large language models (LLMs) for explicit learning, a process involving the assimilation of metalinguistic explanations to carry out language tasks. Using constructed languages generated by cryptographic means as controlled test environments, we designed experiments to assess an LLM's ability to explicitly learn and apply grammar rules. Our results demonstrate that while LLMs possess a measurable capacity for explicit learning, this ability diminishes as the complexity of the linguistic phenomena at hand increases. Supervised fine-tuning on chains of thought significantly enhances LLM performance but struggles to generalize to typologically novel or more complex linguistic features. These findings point to the need for more diverse training sets and alternative fine-tuning strategies to further improve explicit learning by LLMs.
KréyoLID From Language Identification Towards Language Mining
Mar 09, 2025
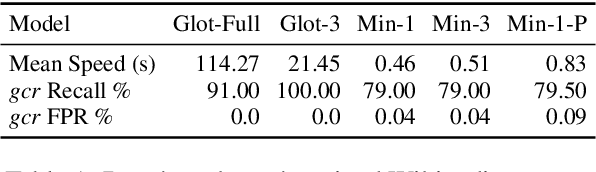
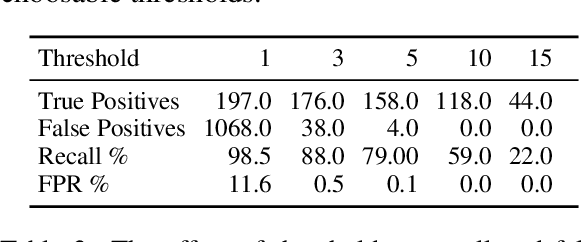

Automatic language identification is frequently framed as a multi-class classification problem. However, when creating digital corpora for less commonly written languages, it may be more appropriate to consider it a data mining problem. For these varieties, one knows ahead of time that the vast majority of documents are of little interest. By minimizing resources spent on classifying such documents, we can create corpora much faster and with better coverage than using established pipelines. To demonstrate the effectiveness of the language mining perspective, we introduce a new pipeline and corpora for several French-based Creoles.
Compositional Translation: A Novel LLM-based Approach for Low-resource Machine Translation
Mar 06, 2025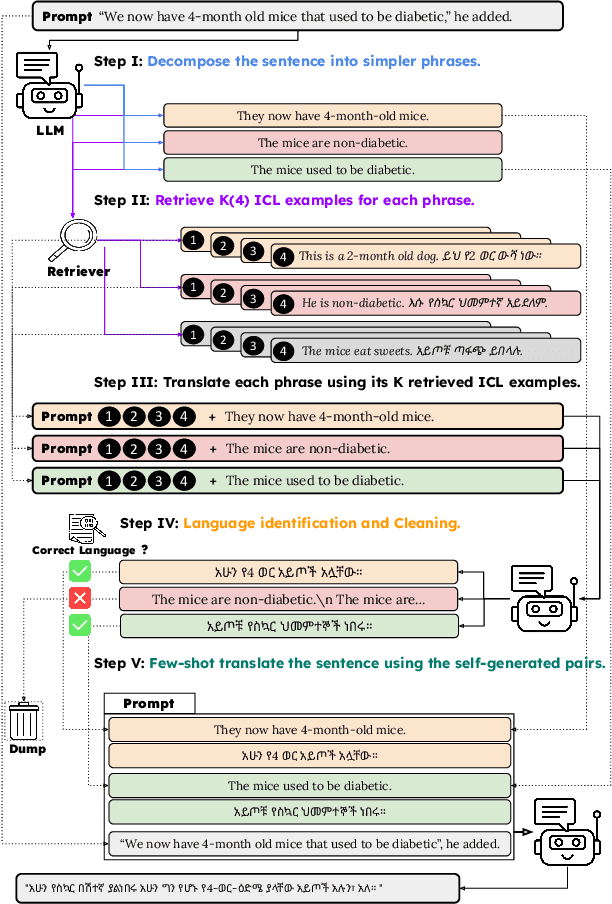
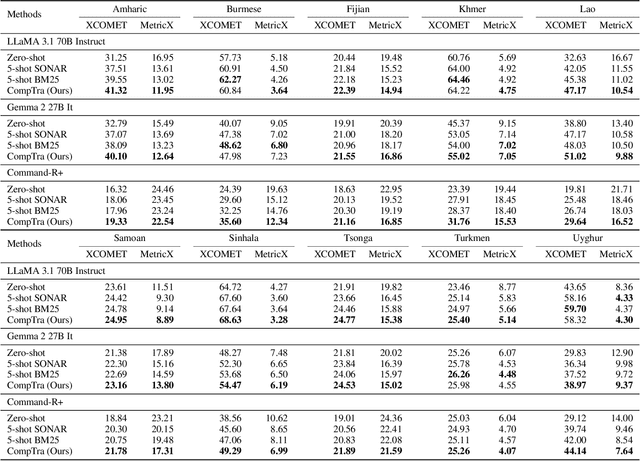
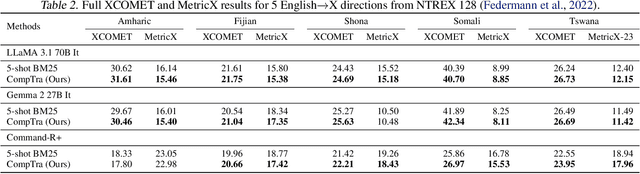
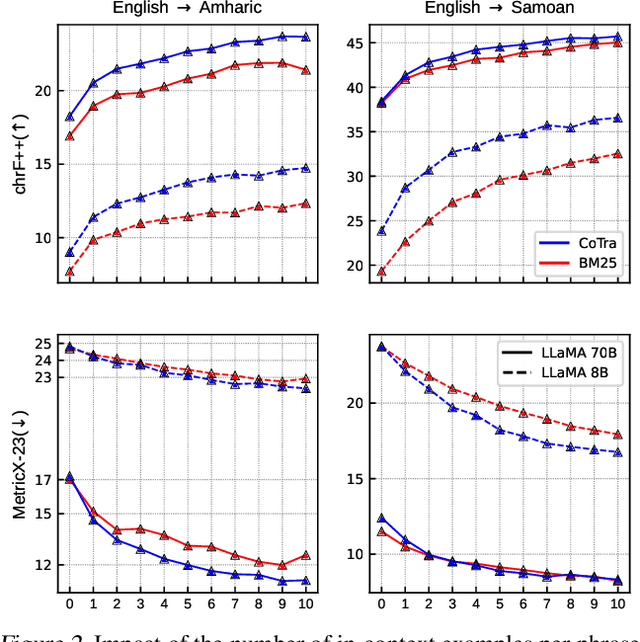
The ability of generative large language models (LLMs) to perform in-context learning has given rise to a large body of research into how best to prompt models for various natural language processing tasks. Machine Translation (MT) has been shown to benefit from in-context examples, in particular when they are semantically similar to the sentence to translate. In this paper, we propose a new LLM-based translation paradigm, compositional translation, to replace naive few-shot MT with similarity-based demonstrations. An LLM is used to decompose a sentence into simpler phrases, and then to translate each phrase with the help of retrieved demonstrations. Finally, the LLM is prompted to translate the initial sentence with the help of the self-generated phrase-translation pairs. Our intuition is that this approach should improve translation because these shorter phrases should be intrinsically easier to translate and easier to match with relevant examples. This is especially beneficial in low-resource scenarios, and more generally whenever the selection pool is small or out of domain. We show that compositional translation boosts LLM translation performance on a wide range of popular MT benchmarks, including FLORES 200, NTREX 128 and TICO-19. Code and outputs are available at https://github.com/ArmelRandy/compositional-translation
Q-Filters: Leveraging QK Geometry for Efficient KV Cache Compression
Mar 04, 2025Autoregressive language models rely on a Key-Value (KV) Cache, which avoids re-computing past hidden states during generation, making it faster. As model sizes and context lengths grow, the KV Cache becomes a significant memory bottleneck, which calls for compression methods that limit its size during generation. In this paper, we discover surprising properties of Query (Q) and Key (K) vectors that allow us to efficiently approximate attention scores without computing the attention maps. We propose Q-Filters, a training-free KV Cache compression method that filters out less crucial Key-Value pairs based on a single context-agnostic projection. Contrarily to many alternatives, Q-Filters is compatible with FlashAttention, as it does not require direct access to attention weights. Experimental results in long-context settings demonstrate that Q-Filters is competitive with attention-based compression methods such as SnapKV in retrieval tasks while consistently outperforming efficient compression schemes such as Streaming-LLM in generation setups. Notably, Q-Filters achieves a 99% accuracy in the needle-in-a-haystack task with a x32 compression level while reducing the generation perplexity drop by up to 65% in text generation compared to Streaming-LLM.