 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling meaning from language in LLM-based machine translation
Feb 04, 2026Mechanistic Interpretability (MI) seeks to explain how neural networks implement their capabilities, but the scale of Large Language Models (LLMs) has limited prior MI work in Machine Translation (MT) to word-level analyses. We study sentence-level MT from a mechanistic perspective by analyzing attention heads to understand how LLMs internally encode and distribute translation functions. We decompose MT into two subtasks: producing text in the target language (i.e. target language identification) and preserving the input sentence's meaning (i.e. sentence equivalence). Across three families of open-source models and 20 translation directions, we find that distinct, sparse sets of attention heads specialize in each subtask. Based on this insight, we construct subtask-specific steering vectors and show that modifying just 1% of the relevant heads enables instruction-free MT performance comparable to instruction-based prompting, while ablating these heads selectively disrupts their corresponding translation functions.
TopXGen: Topic-Diverse Parallel Data Generation for Low-Resource Machine Translation
Aug 12, 2025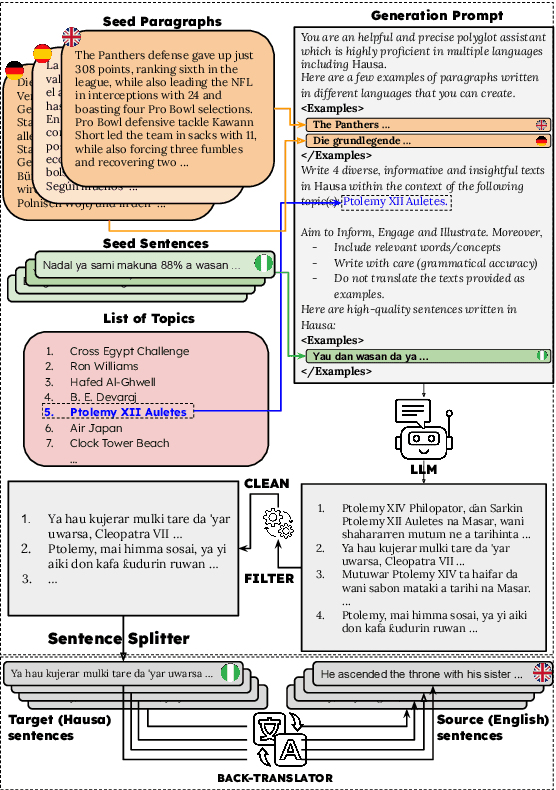

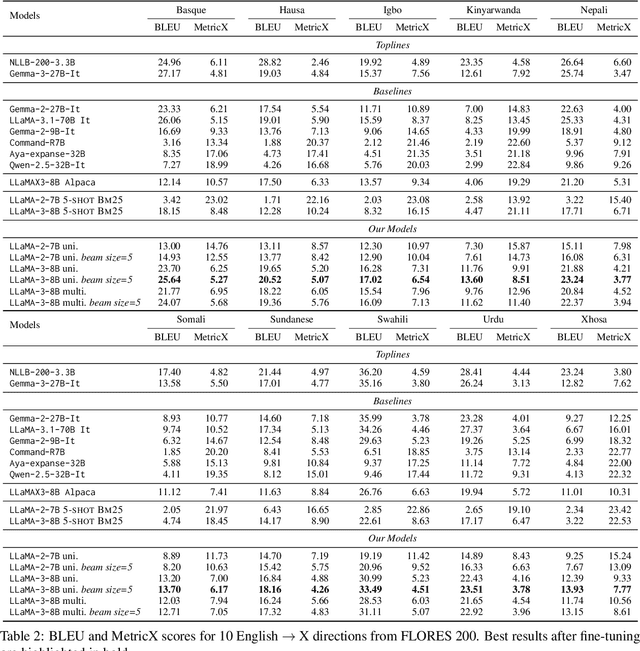
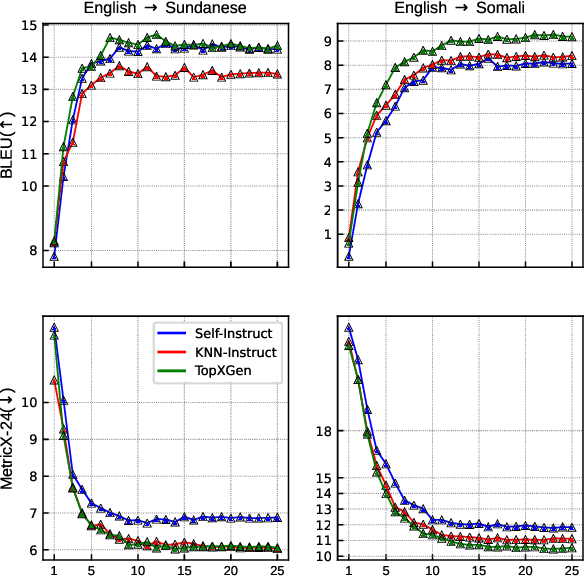
LLMs have been shown to perform well in machine translation (MT) with the use of in-context learning (ICL), rivaling supervised models when translating into high-resource languages (HRLs). However, they lag behind when translating into low-resource language (LRLs). Example selection via similarity search and supervised fine-tuning help. However the improvements they give are limited by the size, quality and diversity of existing parallel datasets. A common technique in low-resource MT is synthetic parallel data creation, the most frequent of which is backtranslation, whereby existing target-side texts are automatically translated into the source language. However, this assumes the existence of good quality and relevant target-side texts, which are not readily available for many LRLs. In this paper, we present \textsc{TopXGen}, an LLM-based approach for the generation of high quality and topic-diverse data in multiple LRLs, which can then be backtranslated to produce useful and diverse parallel texts for ICL and fine-tuning. Our intuition is that while LLMs struggle to translate into LRLs, their ability to translate well into HRLs and their multilinguality enable them to generate good quality, natural-sounding target-side texts, which can be translated well into a high-resource source language. We show that \textsc{TopXGen} boosts LLM translation performance during fine-tuning and in-context learning. Code and outputs are available at https://github.com/ArmelRandy/topxgen.
Compositional Translation: A Novel LLM-based Approach for Low-resource Machine Translation
Mar 06, 2025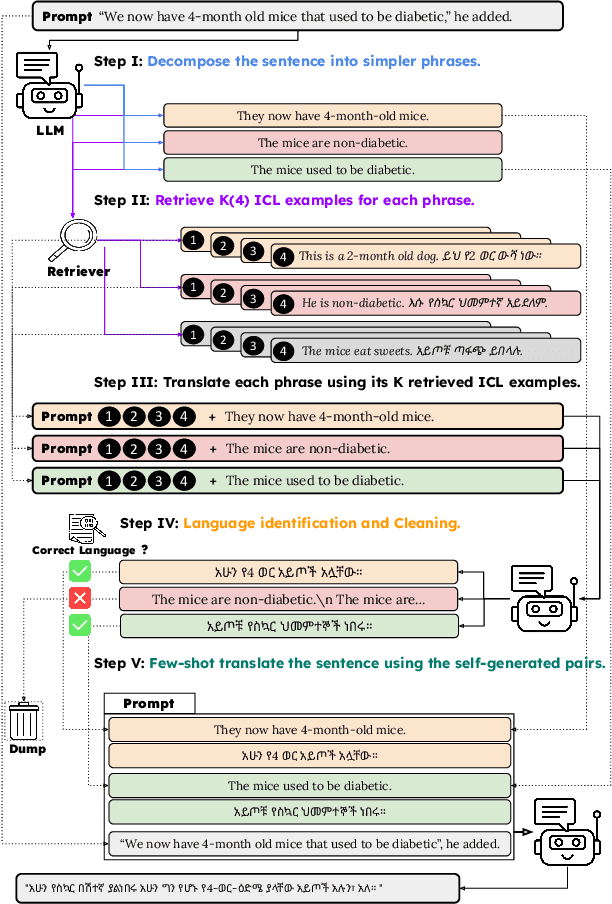
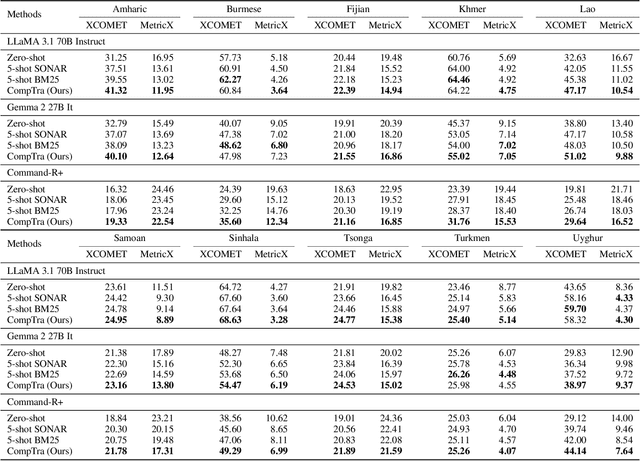
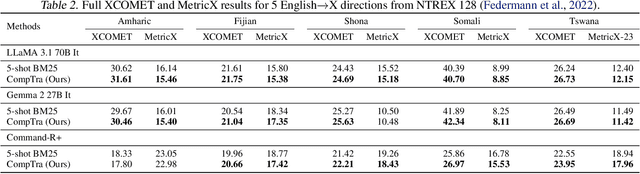
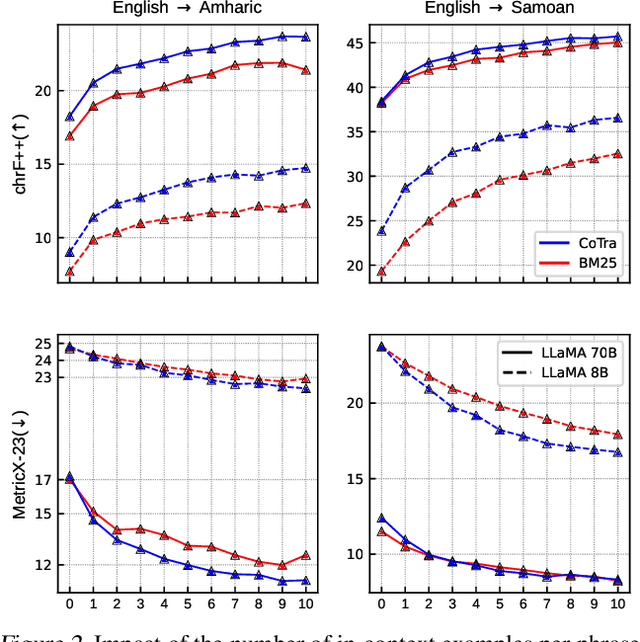
The ability of generative large language models (LLMs) to perform in-context learning has given rise to a large body of research into how best to prompt models for various natural language processing tasks. Machine Translation (MT) has been shown to benefit from in-context examples, in particular when they are semantically similar to the sentence to translate. In this paper, we propose a new LLM-based translation paradigm, compositional translation, to replace naive few-shot MT with similarity-based demonstrations. An LLM is used to decompose a sentence into simpler phrases, and then to translate each phrase with the help of retrieved demonstrations. Finally, the LLM is prompted to translate the initial sentence with the help of the self-generated phrase-translation pairs. Our intuition is that this approach should improve translation because these shorter phrases should be intrinsically easier to translate and easier to match with relevant examples. This is especially beneficial in low-resource scenarios, and more generally whenever the selection pool is small or out of domain. We show that compositional translation boosts LLM translation performance on a wide range of popular MT benchmarks, including FLORES 200, NTREX 128 and TICO-19. Code and outputs are available at https://github.com/ArmelRandy/compositional-translation
Tree of Problems: Improving structured problem solving with compositionality
Oct 09, 2024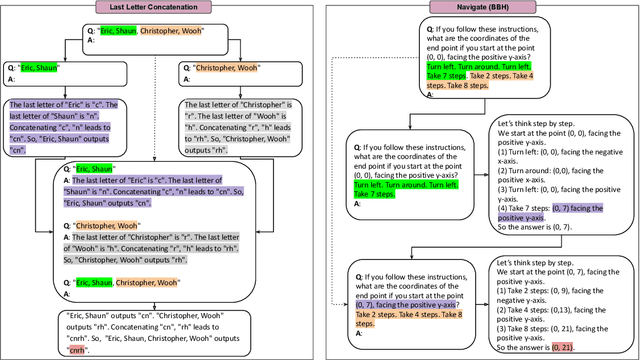
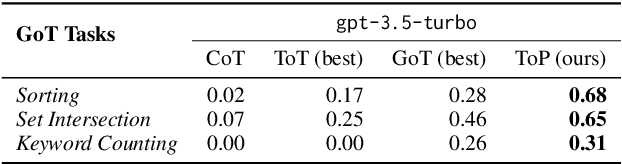

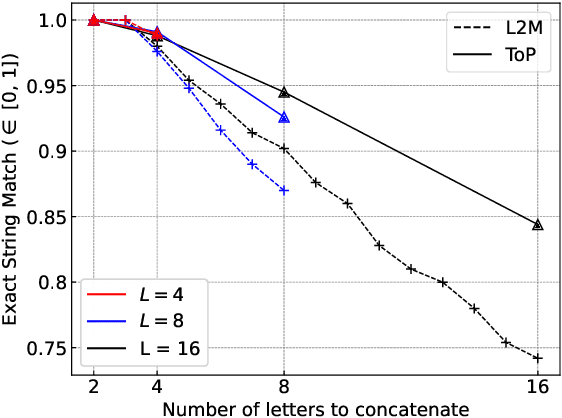
Large Language Models (LLMs) have demonstrated remarkable performance across multiple tasks through in-context learning. For complex reasoning tasks that require step-by-step thinking, Chain-of-Thought (CoT) prompting has given impressive results, especially when combined with self-consistency. Nonetheless, some tasks remain particularly difficult for LLMs to solve. Tree of Thoughts (ToT) and Graph of Thoughts (GoT) emerged as alternatives, dividing the complex problem into paths of subproblems. In this paper, we propose Tree of Problems (ToP), a simpler version of ToT, which we hypothesise can work better for complex tasks that can be divided into identical subtasks. Our empirical results show that our approach outperforms ToT and GoT, and in addition performs better than CoT on complex reasoning tasks. All code for this paper is publicly available here: https://github.com/ArmelRandy/tree-of-problems.
In-Context Example Selection via Similarity Search Improves Low-Resource Machine Translation
Aug 01, 2024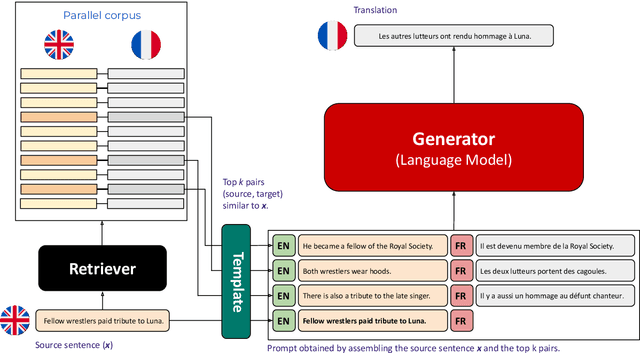

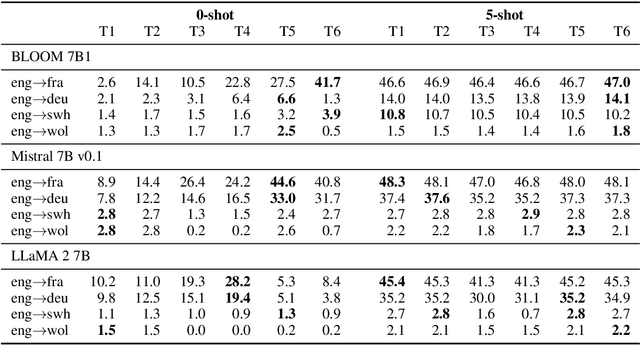
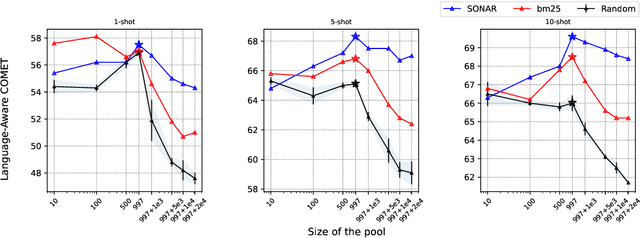
The ability of generative large language models (LLMs) to perform in-context learning has given rise to a large body of research into how best to prompt models for various natural language processing tasks. In this paper, we focus on machine translation (MT), a task that has been shown to benefit from in-context translation examples. However no systematic studies have been published on how best to select examples, and mixed results have been reported on the usefulness of similarity-based selection over random selection. We provide a study covering multiple LLMs and multiple in-context example retrieval strategies, comparing multilingual sentence embeddings. We cover several language directions, representing different levels of language resourcedness (English into French, German, Swahili and Wolof). Contrarily to previously published results, we find that sentence embedding similarity can improve MT, especially for low-resource language directions, and discuss the balance between selection pool diversity and quality. We also highlight potential problems with the evaluation of LLM-based MT and suggest a more appropriate evaluation protocol, adapting the COMET metric to the evaluation of LLMs. Code and outputs are freely available at https://github.com/ArmelRandy/ICL-MT.
mOSCAR: A Large-scale Multilingual and Multimodal Document-level Corpus
Jun 13, 2024



Multimodal Large Language Models (mLLMs) are trained on a large amount of text-image data. While most mLLMs are trained on caption-like data only, Alayrac et al. [2022] showed that additionally training them on interleaved sequences of text and images can lead to the emergence of in-context learning capabilities. However, the dataset they used, M3W, is not public and is only in English. There have been attempts to reproduce their results but the released datasets are English-only. In contrast, current multilingual and multimodal datasets are either composed of caption-like only or medium-scale or fully private data. This limits mLLM research for the 7,000 other languages spoken in the world. We therefore introduce mOSCAR, to the best of our knowledge the first large-scale multilingual and multimodal document corpus crawled from the web. It covers 163 languages, 315M documents, 214B tokens and 1.2B images. We carefully conduct a set of filtering and evaluation steps to make sure mOSCAR is sufficiently safe, diverse and of good quality. We additionally train two types of multilingual model to prove the benefits of mOSCAR: (1) a model trained on a subset of mOSCAR and captioning data and (2) a model train on captioning data only. The model additionally trained on mOSCAR shows a strong boost in few-shot learning performance across various multilingual image-text tasks and benchmarks, confirming previous findings for English-only mLLMs.
StarCoder 2 and The Stack v2: The Next Generation
Feb 29, 2024



The BigCode project, an open-scientific collaboration focused on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder2. In partnership with Software Heritage (SWH), we build The Stack v2 on top of the digital commons of their source code archive. Alongside the SWH repositories spanning 619 programming languages, we carefully select other high-quality data sources, such as GitHub pull requests, Kaggle notebooks, and code documentation. This results in a training set that is 4x larger than the first StarCoder dataset. We train StarCoder2 models with 3B, 7B, and 15B parameters on 3.3 to 4.3 trillion tokens and thoroughly evaluate them on a comprehensive set of Code LLM benchmarks. We find that our small model, StarCoder2-3B, outperforms other Code LLMs of similar size on most benchmarks, and also outperforms StarCoderBase-15B. Our large model, StarCoder2- 15B, significantly outperforms other models of comparable size. In addition, it matches or outperforms CodeLlama-34B, a model more than twice its size. Although DeepSeekCoder- 33B is the best-performing model at code completion for high-resource languages, we find that StarCoder2-15B outperforms it on math and code reasoning benchmarks, as well as several low-resource languages. We make the model weights available under an OpenRAIL license and ensure full transparency regarding the training data by releasing the SoftWare Heritage persistent IDentifiers (SWHIDs) of the source code data.
Astraios: Parameter-Efficient Instruction Tuning Code Large Language Models
Jan 01, 2024The high cost of full-parameter fine-tuning (FFT) of Large Language Models (LLMs) has led to a series of parameter-efficient fine-tuning (PEFT) methods. However, it remains unclear which methods provide the best cost-performance trade-off at different model scales. We introduce Astraios, a suite of 28 instruction-tuned OctoCoder models using 7 tuning methods and 4 model sizes up to 16 billion parameters. Through investigations across 5 tasks and 8 different datasets encompassing both code comprehension and code generation tasks, we find that FFT generally leads to the best downstream performance across all scales, and PEFT methods differ significantly in their efficacy based on the model scale. LoRA usually offers the most favorable trade-off between cost and performance. Further investigation into the effects of these methods on both model robustness and code security reveals that larger models tend to demonstrate reduced robustness and less security. At last, we explore the relationships among updated parameters, cross-entropy loss, and task performance. We find that the tuning effectiveness observed in small models generalizes well to larger models, and the validation loss in instruction tuning can be a reliable indicator of overall downstream performance.
OctoPack: Instruction Tuning Code Large Language Models
Aug 14, 2023Finetuning large language models (LLMs) on instructions leads to vast performance improvements on natural language tasks. We apply instruction tuning using code, leveraging the natural structure of Git commits, which pair code changes with human instructions. We compile CommitPack: 4 terabytes of Git commits across 350 programming languages. We benchmark CommitPack against other natural and synthetic code instructions (xP3x, Self-Instruct, OASST) on the 16B parameter StarCoder model, and achieve state-of-the-art performance among models not trained on OpenAI outputs, on the HumanEval Python benchmark (46.2% pass@1). We further introduce HumanEvalPack, expanding the HumanEval benchmark to a total of 3 coding tasks (Code Repair, Code Explanation, Code Synthesis) across 6 languages (Python, JavaScript, Java, Go, C++, Rust). Our models, OctoCoder and OctoGeeX, achieve the best performance across HumanEvalPack among all permissive models, demonstrating CommitPack's benefits in generalizing to a wider set of languages and natural coding tasks. Code, models and data are freely available at https://github.com/bigcode-project/octopack.
StarCoder: may the source be with you!
May 09, 2023



The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.