 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgnostics: Learning to Code in Any Programming Language via Reinforcement with a Universal Learning Environment
Aug 06, 2025Large language models (LLMs) already excel at writing code in high-resource languages such as Python and JavaScript, yet stumble on low-resource languages that remain essential to science and engineering. Besides the obvious shortage of pre-training data, post-training itself is a bottleneck: every new language seems to require new datasets, test harnesses, and reinforcement-learning (RL) infrastructure. We introduce Agnostics, a language-agnostic post-training pipeline that eliminates this per-language engineering. The key idea is to judge code solely by its externally observable behavior, so a single verifier can test solutions written in any language. Concretely, we (i) use an LLM to rewrite existing unit-test datasets into an I/O format, (ii) supply a short configuration that tells the verifier how to compile and run a target language, and (iii) apply reinforcement learning with verifiable rewards (RLVR) in a robust code execution environment. Applied to five low-resource languages--Lua, Julia, R, OCaml, and Fortran--Agnostics (1) improves Qwen-3 4B to performance that rivals other 16B-70B open-weight models; (2) scales cleanly to larger and diverse model families (Qwen-3 8B, DeepSeek Coder 6.7B Instruct, Phi 4 Mini); and (3) for ${\le} 16$B parameter models, sets new state-of-the-art pass@1 results on MultiPL-E and a new multi-language version LiveCodeBench that we introduce. We will release the language-agnostic training datasets (Ag-MBPP-X, Ag-Codeforces-X, Ag-LiveCodeBench-X), training code, and ready-to-use configurations, making RL post-training in any programming language as simple as editing a short YAML file.
StudentEval: A Benchmark of Student-Written Prompts for Large Language Models of Code
Jun 07, 2023



Code LLMs are being rapidly deployed and there is evidence that they can make professional programmers more productive. Current benchmarks for code generation measure whether models generate correct programs given an expert prompt. In this paper, we present a new benchmark containing multiple prompts per problem, written by a specific population of non-expert prompters: beginning programmers. StudentEval contains 1,749 prompts for 48 problems, written by 80 students who have only completed one semester of Python programming. Our students wrote these prompts while working interactively with a Code LLM, and we observed very mixed success rates. We use StudentEval to evaluate 5 Code LLMs and find that StudentEval is a better discriminator of model performance than existing benchmarks. We analyze the prompts and find significant variation in students' prompting techniques. We also find that nondeterministic LLM sampling could mislead students into thinking that their prompts are more (or less) effective than they actually are, which has implications for how to teach with Code LLMs.
StarCoder: may the source be with you!
May 09, 2023



The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
SantaCoder: don't reach for the stars!
Jan 09, 2023



The BigCode project is an open-scientific collaboration working on the responsible development of large language models for code. This tech report describes the progress of the collaboration until December 2022, outlining the current state of the Personally Identifiable Information (PII) redaction pipeline, the experiments conducted to de-risk the model architecture, and the experiments investigating better preprocessing methods for the training data. We train 1.1B parameter models on the Java, JavaScript, and Python subsets of The Stack and evaluate them on the MultiPL-E text-to-code benchmark. We find that more aggressive filtering of near-duplicates can further boost performance and, surprisingly, that selecting files from repositories with 5+ GitHub stars deteriorates performance significantly. Our best model outperforms previous open-source multilingual code generation models (InCoder-6.7B and CodeGen-Multi-2.7B) in both left-to-right generation and infilling on the Java, JavaScript, and Python portions of MultiPL-E, despite being a substantially smaller model. All models are released under an OpenRAIL license at https://hf.co/bigcode.
A Scalable and Extensible Approach to Benchmarking NL2Code for 18 Programming Languages
Aug 19, 2022
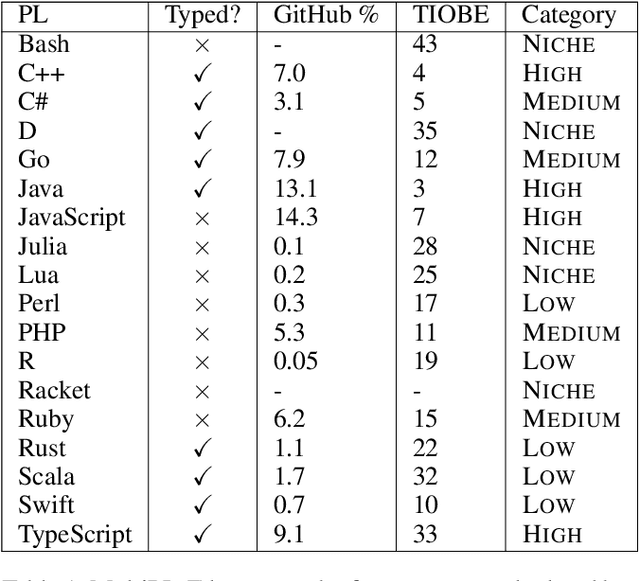

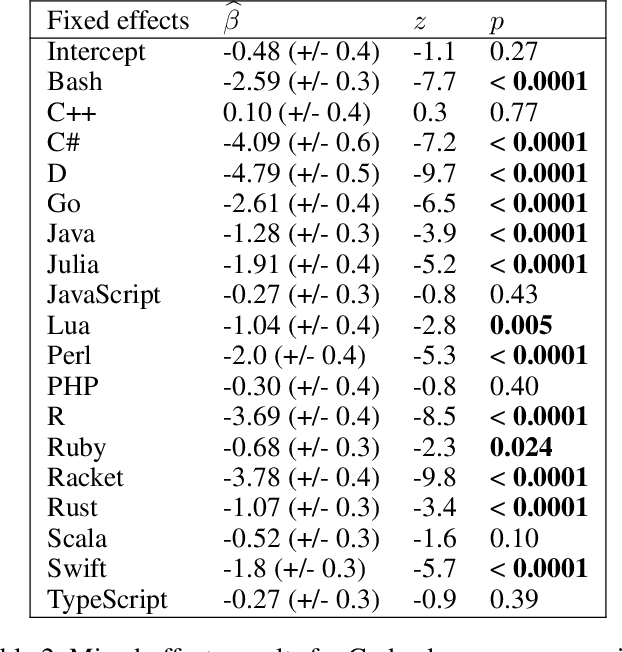
Large language models have demonstrated the ability to condition on and generate both natural language and programming language text. Such models open up the possibility of multi-language code generation: could code generation models generalize knowledge from one language to another? Although contemporary code generation models can generate semantically correct Python code, little is known about their abilities with other languages. We facilitate the exploration of this topic by proposing MultiPL-E, the first multi-language parallel benchmark for natural-language-to-code-generation. MultiPL-E extends the HumanEval benchmark (Chen et al, 2021) to support 18 more programming languages, encompassing a range of programming paradigms and popularity. We evaluate two state-of-the-art code generation models on MultiPL-E: Codex and InCoder. We find that on several languages, Codex matches and even exceeds its performance on Python. The range of programming languages represented in MultiPL-E allow us to explore the impact of language frequency and language features on model performance. Finally, the MultiPL-E approach of compiling code generation benchmarks to new programming languages is both scalable and extensible. We describe a general approach for easily adding support for new benchmarks and languages to MultiPL-E.