 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhD Knowledge Not Required: A Reasoning Challenge for Large Language Models
Feb 03, 2025



Existing benchmarks for frontier models often test specialized, ``PhD-level'' knowledge that is difficult for non-experts to grasp. In contrast, we present a benchmark based on the NPR Sunday Puzzle Challenge that requires only general knowledge. Our benchmark is challenging for both humans and models, however correct solutions are easy to verify, and models' mistakes are easy to spot. Our work reveals capability gaps that are not evident in existing benchmarks: OpenAI o1 significantly outperforms other reasoning models that are on par on benchmarks that test specialized knowledge. Furthermore, our analysis of reasoning outputs uncovers new kinds of failures. DeepSeek R1, for instance, often concedes with ``I give up'' before providing an answer that it knows is wrong. R1 can also be remarkably ``uncertain'' in its output and in rare cases, it does not ``finish thinking,'' which suggests the need for an inference-time technique to ``wrap up'' before the context window limit is reached. We also quantify the effectiveness of reasoning longer with R1 and Gemini Thinking to identify the point beyond which more reasoning is unlikely to improve accuracy on our benchmark.
StudentEval: A Benchmark of Student-Written Prompts for Large Language Models of Code
Jun 07, 2023



Code LLMs are being rapidly deployed and there is evidence that they can make professional programmers more productive. Current benchmarks for code generation measure whether models generate correct programs given an expert prompt. In this paper, we present a new benchmark containing multiple prompts per problem, written by a specific population of non-expert prompters: beginning programmers. StudentEval contains 1,749 prompts for 48 problems, written by 80 students who have only completed one semester of Python programming. Our students wrote these prompts while working interactively with a Code LLM, and we observed very mixed success rates. We use StudentEval to evaluate 5 Code LLMs and find that StudentEval is a better discriminator of model performance than existing benchmarks. We analyze the prompts and find significant variation in students' prompting techniques. We also find that nondeterministic LLM sampling could mislead students into thinking that their prompts are more (or less) effective than they actually are, which has implications for how to teach with Code LLMs.
A Scalable and Extensible Approach to Benchmarking NL2Code for 18 Programming Languages
Aug 19, 2022
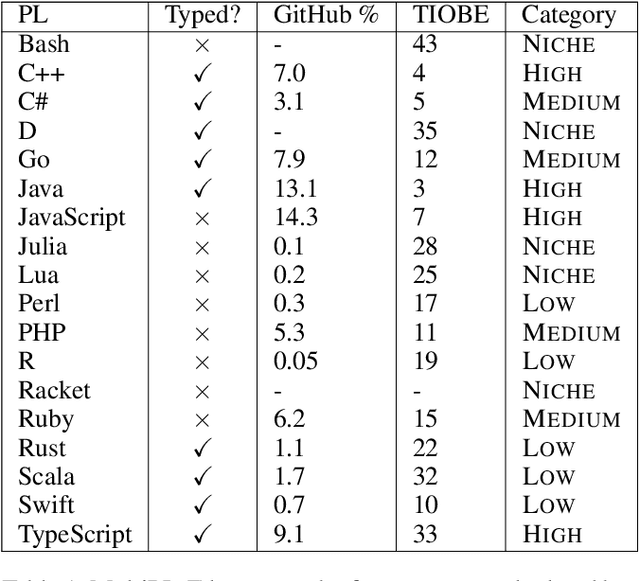

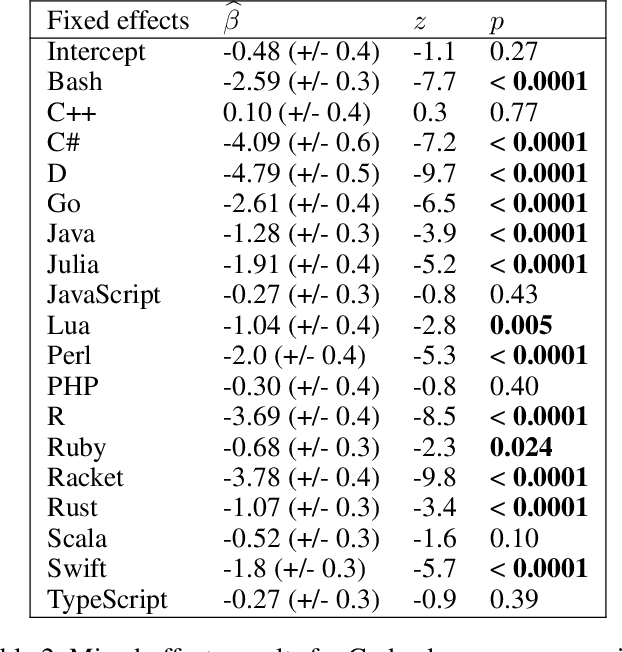
Large language models have demonstrated the ability to condition on and generate both natural language and programming language text. Such models open up the possibility of multi-language code generation: could code generation models generalize knowledge from one language to another? Although contemporary code generation models can generate semantically correct Python code, little is known about their abilities with other languages. We facilitate the exploration of this topic by proposing MultiPL-E, the first multi-language parallel benchmark for natural-language-to-code-generation. MultiPL-E extends the HumanEval benchmark (Chen et al, 2021) to support 18 more programming languages, encompassing a range of programming paradigms and popularity. We evaluate two state-of-the-art code generation models on MultiPL-E: Codex and InCoder. We find that on several languages, Codex matches and even exceeds its performance on Python. The range of programming languages represented in MultiPL-E allow us to explore the impact of language frequency and language features on model performance. Finally, the MultiPL-E approach of compiling code generation benchmarks to new programming languages is both scalable and extensible. We describe a general approach for easily adding support for new benchmarks and languages to MultiPL-E.