 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Assisted Peer Review at Scale: The AAAI-26 AI Review Pilot
Apr 15, 2026Scientific peer review faces mounting strain as submission volumes surge, making it increasingly difficult to sustain review quality, consistency, and timeliness. Recent advances in AI have led the community to consider its use in peer review, yet a key unresolved question is whether AI can generate technically sound reviews at real-world conference scale. Here we report the first large-scale field deployment of AI-assisted peer review: every main-track submission at AAAI-26 received one clearly identified AI review from a state-of-the-art system. The system combined frontier models, tool use, and safeguards in a multi-stage process to generate reviews for all 22,977 full-review papers in less than a day. A large-scale survey of AAAI-26 authors and program committee members showed that participants not only found AI reviews useful, but actually preferred them to human reviews on key dimensions such as technical accuracy and research suggestions. We also introduce a novel benchmark and find that our system substantially outperforms a simple LLM-generated review baseline at detecting a variety of scientific weaknesses. Together, these results show that state-of-the-art AI methods can already make meaningful contributions to scientific peer review at conference scale, opening a path toward the next generation of synergistic human-AI teaming for evaluating research.
BEV-Patch-PF: Particle Filtering with BEV-Aerial Feature Matching for Off-Road Geo-Localization
Dec 17, 2025We propose BEV-Patch-PF, a GPS-free sequential geo-localization system that integrates a particle filter with learned bird's-eye-view (BEV) and aerial feature maps. From onboard RGB and depth images, we construct a BEV feature map. For each 3-DoF particle pose hypothesis, we crop the corresponding patch from an aerial feature map computed from a local aerial image queried around the approximate location. BEV-Patch-PF computes a per-particle log-likelihood by matching the BEV feature to the aerial patch feature. On two real-world off-road datasets, our method achieves 7.5x lower absolute trajectory error (ATE) on seen routes and 7.0x lower ATE on unseen routes than a retrieval-based baseline, while maintaining accuracy under dense canopy and shadow. The system runs in real time at 10 Hz on an NVIDIA Tesla T4, enabling practical robot deployment.
Terrain Costmap Generation via Scaled Preference Conditioning
Nov 14, 2025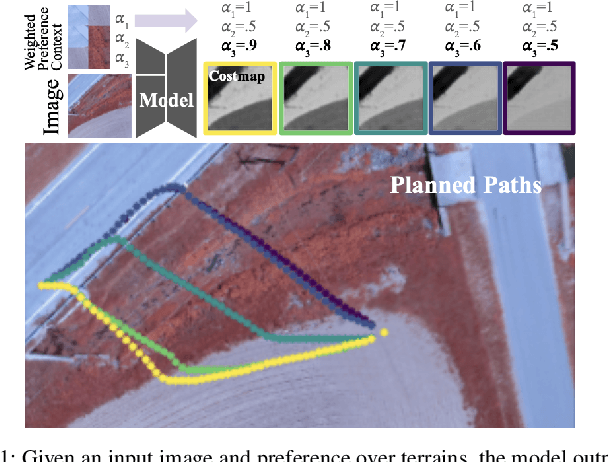
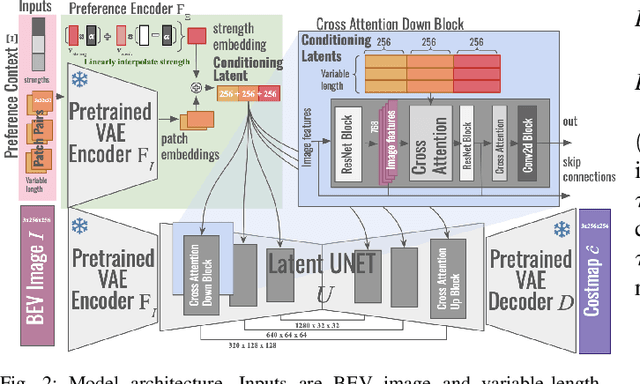
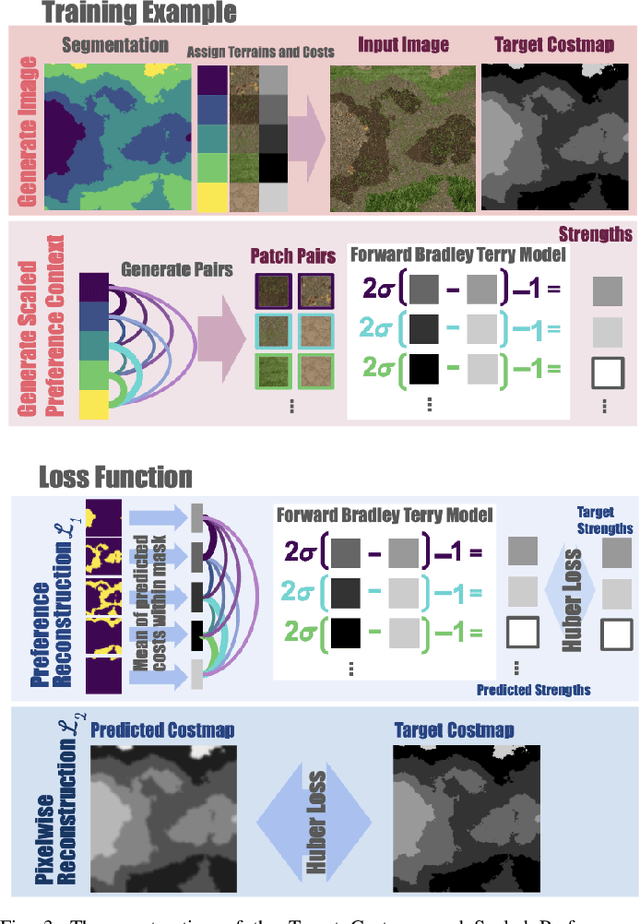

Successful autonomous robot navigation in off-road domains requires the ability to generate high-quality terrain costmaps that are able to both generalize well over a wide variety of terrains and rapidly adapt relative costs at test time to meet mission-specific needs. Existing approaches for costmap generation allow for either rapid test-time adaptation of relative costs (e.g., semantic segmentation methods) or generalization to new terrain types (e.g., representation learning methods), but not both. In this work, we present scaled preference conditioned all-terrain costmap generation (SPACER), a novel approach for generating terrain costmaps that leverages synthetic data during training in order to generalize well to new terrains, and allows for rapid test-time adaptation of relative costs by conditioning on a user-specified scaled preference context. Using large-scale aerial maps, we provide empirical evidence that SPACER outperforms other approaches at generating costmaps for terrain navigation, with the lowest measured regret across varied preferences in five of seven environments for global path planning.
VENTURA: Adapting Image Diffusion Models for Unified Task Conditioned Navigation
Oct 01, 2025Robots must adapt to diverse human instructions and operate safely in unstructured, open-world environments. Recent Vision-Language models (VLMs) offer strong priors for grounding language and perception, but remain difficult to steer for navigation due to differences in action spaces and pretraining objectives that hamper transferability to robotics tasks. Towards addressing this, we introduce VENTURA, a vision-language navigation system that finetunes internet-pretrained image diffusion models for path planning. Instead of directly predicting low-level actions, VENTURA generates a path mask (i.e. a visual plan) in image space that captures fine-grained, context-aware navigation behaviors. A lightweight behavior-cloning policy grounds these visual plans into executable trajectories, yielding an interface that follows natural language instructions to generate diverse robot behaviors. To scale training, we supervise on path masks derived from self-supervised tracking models paired with VLM-augmented captions, avoiding manual pixel-level annotation or highly engineered data collection setups. In extensive real-world evaluations, VENTURA outperforms state-of-the-art foundation model baselines on object reaching, obstacle avoidance, and terrain preference tasks, improving success rates by 33% and reducing collisions by 54% across both seen and unseen scenarios. Notably, we find that VENTURA generalizes to unseen combinations of distinct tasks, revealing emergent compositional capabilities. Videos, code, and additional materials: https://venturapath.github.io
SocialNav-SUB: Benchmarking VLMs for Scene Understanding in Social Robot Navigation
Sep 10, 2025Robot navigation in dynamic, human-centered environments requires socially-compliant decisions grounded in robust scene understanding. Recent Vision-Language Models (VLMs) exhibit promising capabilities such as object recognition, common-sense reasoning, and contextual understanding-capabilities that align with the nuanced requirements of social robot navigation. However, it remains unclear whether VLMs can accurately understand complex social navigation scenes (e.g., inferring the spatial-temporal relations among agents and human intentions), which is essential for safe and socially compliant robot navigation. While some recent works have explored the use of VLMs in social robot navigation, no existing work systematically evaluates their ability to meet these necessary conditions. In this paper, we introduce the Social Navigation Scene Understanding Benchmark (SocialNav-SUB), a Visual Question Answering (VQA) dataset and benchmark designed to evaluate VLMs for scene understanding in real-world social robot navigation scenarios. SocialNav-SUB provides a unified framework for evaluating VLMs against human and rule-based baselines across VQA tasks requiring spatial, spatiotemporal, and social reasoning in social robot navigation. Through experiments with state-of-the-art VLMs, we find that while the best-performing VLM achieves an encouraging probability of agreeing with human answers, it still underperforms simpler rule-based approach and human consensus baselines, indicating critical gaps in social scene understanding of current VLMs. Our benchmark sets the stage for further research on foundation models for social robot navigation, offering a framework to explore how VLMs can be tailored to meet real-world social robot navigation needs. An overview of this paper along with the code and data can be found at https://larg.github.io/socialnav-sub .
Agnostics: Learning to Code in Any Programming Language via Reinforcement with a Universal Learning Environment
Aug 06, 2025Large language models (LLMs) already excel at writing code in high-resource languages such as Python and JavaScript, yet stumble on low-resource languages that remain essential to science and engineering. Besides the obvious shortage of pre-training data, post-training itself is a bottleneck: every new language seems to require new datasets, test harnesses, and reinforcement-learning (RL) infrastructure. We introduce Agnostics, a language-agnostic post-training pipeline that eliminates this per-language engineering. The key idea is to judge code solely by its externally observable behavior, so a single verifier can test solutions written in any language. Concretely, we (i) use an LLM to rewrite existing unit-test datasets into an I/O format, (ii) supply a short configuration that tells the verifier how to compile and run a target language, and (iii) apply reinforcement learning with verifiable rewards (RLVR) in a robust code execution environment. Applied to five low-resource languages--Lua, Julia, R, OCaml, and Fortran--Agnostics (1) improves Qwen-3 4B to performance that rivals other 16B-70B open-weight models; (2) scales cleanly to larger and diverse model families (Qwen-3 8B, DeepSeek Coder 6.7B Instruct, Phi 4 Mini); and (3) for ${\le} 16$B parameter models, sets new state-of-the-art pass@1 results on MultiPL-E and a new multi-language version LiveCodeBench that we introduce. We will release the language-agnostic training datasets (Ag-MBPP-X, Ag-Codeforces-X, Ag-LiveCodeBench-X), training code, and ready-to-use configurations, making RL post-training in any programming language as simple as editing a short YAML file.
Spatiotemporal Contrastive Learning for Cross-View Video Localization in Unstructured Off-road Terrains
Jun 05, 2025Robust cross-view 3-DoF localization in GPS-denied, off-road environments remains challenging due to (1) perceptual ambiguities from repetitive vegetation and unstructured terrain, and (2) seasonal shifts that significantly alter scene appearance, hindering alignment with outdated satellite imagery. To address this, we introduce MoViX, a self-supervised cross-view video localization framework that learns viewpoint- and season-invariant representations while preserving directional awareness essential for accurate localization. MoViX employs a pose-dependent positive sampling strategy to enhance directional discrimination and temporally aligned hard negative mining to discourage shortcut learning from seasonal cues. A motion-informed frame sampler selects spatially diverse frames, and a lightweight temporal aggregator emphasizes geometrically aligned observations while downweighting ambiguous ones. At inference, MoViX runs within a Monte Carlo Localization framework, using a learned cross-view matching module in place of handcrafted models. Entropy-guided temperature scaling enables robust multi-hypothesis tracking and confident convergence under visual ambiguity. We evaluate MoViX on the TartanDrive 2.0 dataset, training on under 30 minutes of data and testing over 12.29 km. Despite outdated satellite imagery, MoViX localizes within 25 meters of ground truth 93% of the time, and within 50 meters 100% of the time in unseen regions, outperforming state-of-the-art baselines without environment-specific tuning. We further demonstrate generalization on a real-world off-road dataset from a geographically distinct site with a different robot platform.
cuVSLAM: CUDA accelerated visual odometry
Jun 04, 2025Accurate and robust pose estimation is a key requirement for any autonomous robot. We present cuVSLAM, a state-of-the-art solution for visual simultaneous localization and mapping, which can operate with a variety of visual-inertial sensor suites, including multiple RGB and depth cameras, and inertial measurement units. cuVSLAM supports operation with as few as one RGB camera to as many as 32 cameras, in arbitrary geometric configurations, thus supporting a wide range of robotic setups. cuVSLAM is specifically optimized using CUDA to deploy in real-time applications with minimal computational overhead on edge-computing devices such as the NVIDIA Jetson. We present the design and implementation of cuVSLAM, example use cases, and empirical results on several state-of-the-art benchmarks demonstrating the best-in-class performance of cuVSLAM.
Guiding Diffusion with Deep Geometric Moments: Balancing Fidelity and Variation
May 18, 2025Text-to-image generation models have achieved remarkable capabilities in synthesizing images, but often struggle to provide fine-grained control over the output. Existing guidance approaches, such as segmentation maps and depth maps, introduce spatial rigidity that restricts the inherent diversity of diffusion models. In this work, we introduce Deep Geometric Moments (DGM) as a novel form of guidance that encapsulates the subject's visual features and nuances through a learned geometric prior. DGMs focus specifically on the subject itself compared to DINO or CLIP features, which suffer from overemphasis on global image features or semantics. Unlike ResNets, which are sensitive to pixel-wise perturbations, DGMs rely on robust geometric moments. Our experiments demonstrate that DGM effectively balance control and diversity in diffusion-based image generation, allowing a flexible control mechanism for steering the diffusion process.
Human-Centered Development of Guide Dog Robots: Quiet and Stable Locomotion Control
May 17, 2025
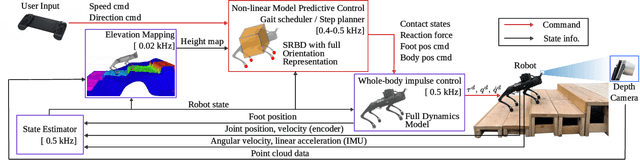
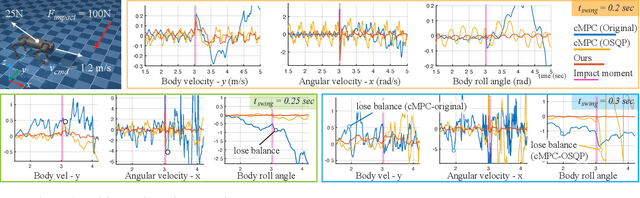
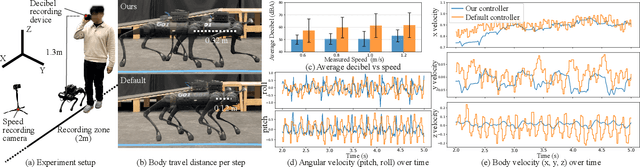
A quadruped robot is a promising system that can offer assistance comparable to that of dog guides due to its similar form factor. However, various challenges remain in making these robots a reliable option for blind and low-vision (BLV) individuals. Among these challenges, noise and jerky motion during walking are critical drawbacks of existing quadruped robots. While these issues have largely been overlooked in guide dog robot research, our interviews with guide dog handlers and trainers revealed that acoustic and physical disturbances can be particularly disruptive for BLV individuals, who rely heavily on environmental sounds for navigation. To address these issues, we developed a novel walking controller for slow stepping and smooth foot swing/contact while maintaining human walking speed, as well as robust and stable balance control. The controller integrates with a perception system to facilitate locomotion over non-flat terrains, such as stairs. Our controller was extensively tested on the Unitree Go1 robot and, when compared with other control methods, demonstrated significant noise reduction -- half of the default locomotion controller. In this study, we adopt a mixed-methods approach to evaluate its usability with BLV individuals. In our indoor walking experiments, participants compared our controller to the robot's default controller. Results demonstrated superior acceptance of our controller, highlighting its potential to improve the user experience of guide dog robots. Video demonstration (best viewed with audio) available at: https://youtu.be/8-pz_8Hqe6s.