 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGILE: A Comprehensive Workflow for Humanoid Loco-Manipulation Learning
Mar 20, 2026Recent advances in reinforcement learning (RL) have enabled impressive humanoid behaviors in simulation, yet transferring these results to new robots remains challenging. In many real deployments, the primary bottleneck is no longer simulation throughput or algorithm design, but the absence of systematic infrastructure that links environment verification, training, evaluation, and deployment in a coherent loop. To address this gap, we present AGILE, an end-to-end workflow for humanoid RL that standardizes the policy-development lifecycle to mitigate common sim-to-real failure modes. AGILE comprises four stages: (1) interactive environment verification, (2) reproducible training, (3) unified evaluation, and (4) descriptor-driven deployment via robot/task configuration descriptors. For evaluation stage, AGILE supports both scenario-based tests and randomized rollouts under a shared suite of motion-quality diagnostics, enabling automated regression testing and principled robustness assessment. AGILE also incorporates a set of training stabilizations and algorithmic enhancements in training stage to improve optimization stability and sim-to-real transfer. With this pipeline in place, we validate AGILE across five representative humanoid skills spanning locomotion, recovery, motion imitation, and loco-manipulation on two hardware platforms (Unitree G1 and Booster T1), achieving consistent sim-to-real transfer. Overall, AGILE shows that a standardized, end-to-end workflow can substantially improve the reliability and reproducibility of humanoid RL development.
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
COMPASS: Cross-embodiment Mobility Policy via Residual RL and Skill Synthesis
Feb 22, 2025



As robots are increasingly deployed in diverse application domains, generalizable cross-embodiment mobility policies are increasingly essential. While classical mobility stacks have proven effective on specific robot platforms, they pose significant challenges when scaling to new embodiments. Learning-based methods, such as imitation learning (IL) and reinforcement learning (RL), offer alternative solutions but suffer from covariate shift, sparse sampling in large environments, and embodiment-specific constraints. This paper introduces COMPASS, a novel workflow for developing cross-embodiment mobility policies by integrating IL, residual RL, and policy distillation. We begin with IL on a mobile robot, leveraging easily accessible teacher policies to train a foundational model that combines a world model with a mobility policy. Building on this base, we employ residual RL to fine-tune embodiment-specific policies, exploiting pre-trained representations to improve sampling efficiency in handling various physical constraints and sensor modalities. Finally, policy distillation merges these embodiment-specialist policies into a single robust cross-embodiment policy. We empirically demonstrate that COMPASS scales effectively across diverse robot platforms while maintaining adaptability to various environment configurations, achieving a generalist policy with a success rate approximately 5X higher than the pre-trained IL policy. The resulting framework offers an efficient, scalable solution for cross-embodiment mobility, enabling robots with different designs to navigate safely and efficiently in complex scenarios.
X-MOBILITY: End-To-End Generalizable Navigation via World Modeling
Oct 23, 2024



General-purpose navigation in challenging environments remains a significant problem in robotics, with current state-of-the-art approaches facing myriad limitations. Classical approaches struggle with cluttered settings and require extensive tuning, while learning-based methods face difficulties generalizing to out-of-distribution environments. This paper introduces X-Mobility, an end-to-end generalizable navigation model that overcomes existing challenges by leveraging three key ideas. First, X-Mobility employs an auto-regressive world modeling architecture with a latent state space to capture world dynamics. Second, a diverse set of multi-head decoders enables the model to learn a rich state representation that correlates strongly with effective navigation skills. Third, by decoupling world modeling from action policy, our architecture can train effectively on a variety of data sources, both with and without expert policies: off-policy data allows the model to learn world dynamics, while on-policy data with supervisory control enables optimal action policy learning. Through extensive experiments, we demonstrate that X-Mobility not only generalizes effectively but also surpasses current state-of-the-art navigation approaches. Additionally, X-Mobility also achieves zero-shot Sim2Real transferability and shows strong potential for cross-embodiment generalization.
Conditional Energy-Based Models for Implicit Policies: The Gap between Theory and Practice
Jul 12, 2022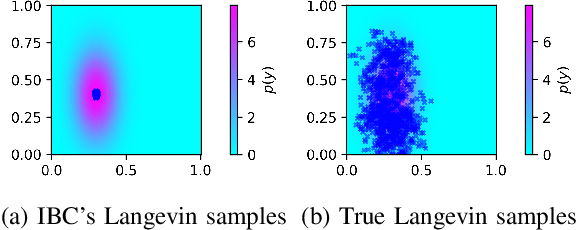
We present our findings in the gap between theory and practice of using conditional energy-based models (EBM) as an implicit representation for behavior-cloned policies. We also clarify several subtle, and potentially confusing, details in previous work in an attempt to help future research in this area. We point out key differences between unconditional and conditional EBMs, and warn that blindly applying training methods for one to the other could lead to undesirable results that do not generalize well. Finally, we emphasize the importance of the Maximum Mutual Information principle as a necessary condition to achieve good generalization in conditional EBMs as implicit models for regression tasks.