 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREAR: Test-time Preference Realignment through Reward Decomposition
Jun 29, 2026Aligning large language models (LLMs) with diverse user preferences is a critical yet challenging task. While post-training methods can adapt models to specific needs, they often require costly data curation and additional training. Test-time scaling (TTS) presents an efficient, training-free alternative, but its application has been largely limited to verifiable domains like mathematics and coding, where response correctness is easily judged. To extend TTS to preference alignment, we introduce a novel framework that models the task as a realignment problem, since the base model often fails to sufficiently align with the stated preference. Our key insight is to decompose the underlying reward function into two components: one related to the question and the other to preference information. This allows us to derive a REAlignment Reward (REAR) that selectively rescales the proportions of these two reward terms. We then show that REAR can be formulated as a linear combination of token-level policy log-probabilities, making it computationally efficient and easy to integrate with various TTS algorithms such as best-of-$N$ sampling and tree search. Experiments show that compared to other test-time baselines, REAR not only enables scalable test-time realignment for preference alignment tasks under diverse user requirements, but also generalizes to mathematical and visual tasks under appropriate preference settings.
TEXEDO : Test Time Scaling for Controller-aware Language-conditioned Humanoid Motion Generation
Jun 23, 2026Text-conditioned motion generation is a promising interface for programming humanoid robots, yet current generators are often trained on human motion datasets retargeted to robot morphologies. Although such data provides rich semantic and kinematic priors, it fails to capture the nuances of whole-body tracking controllers, including balance, contact dynamics, actuation limits, and controller-specific failure modes. As a result, generated motions can be semantically plausible but difficult or impossible for the robot to execute. We introduce TEXEDO, a test-time scaling framework for humanoid motion generation that improves motion quality without requiring a stronger underlying generator. Given a text prompt, TEXEDO samples multiple candidate motions from a pretrained text-conditioned generator and selects the best motion that is both executable and task-aligned. The reward model combines a dynamic feasibility verifier, distilled from whole-body tracking rollouts to predict physical executability, with a semantic alignment verifier that measures text-motion alignment in a learned co-embedding space. Our pipeline treats dynamic feasibility as a hard constraint and semantic alignment as the selection objective within the feasible set. Through large-scale simulation studies and real-world deployment on a Unitree G1 humanoid robot, we show that TEXEDO consistently improves both tracking fidelity and text alignment. These results demonstrate that grounded verification is an effective path toward deployable language-guided humanoid motion generation. Project website: https://jianuocao.github.io/TEXEDO/
CoorDex: Coordinating Body and Hand Priors for Continuous Dexterous Humanoid Loco-Manipulation
Jun 22, 2026Humanoid loco-manipulation is often simplified into a stop-and-go process: walking to an object, stopping to manipulate it, and then resuming locomotion. It also commonly relies on low degree-of-freedom (DoF) end effectors that behave like an open-close grasp primitive. We introduce CoorDex, a learning pipeline that converts high-dimensional body and dexterous hand control into coordinated latent residual control, enabling high-DoF dexterous loco-manipulation on the move. Starting from simulated whole-body and hand demonstrations, CoorDex trains privileged motion tracking teachers for the humanoid body and dexterous hand, distills them into proprioception-conditioned latent priors, and uses the frozen priors as the action space for downstream residual reinforcement learning. A coordinated latent residual policy composes these priors through shared task context and separate body-hand residual heads, preserving natural whole-body motion while improving finger-level contact reliability. CoorDex enables a Unitree G1 humanoid with a 20-DoF WUJI hand to execute dexterous manipulation while in motion, including non-stop bottle grasping and carrying, fridge door opening on the move, and cube pick-and-turn. Ablations on the walk-grasp-carry task show that joint-space PPO, joint-space hand control, and monolithic latent prediction all fail under the same reward budget, while the latent-prior interface and coordinated residual structure make high-dimensional contact-rich loco-manipulation trainable. Project Page: https://skevinci.github.io/coordex/
Learning Dexterous Manipulation Using Contact Wrench Guidance From Human Demonstration
Jun 22, 2026Dexterous robot manipulation can benefit from the abundance of human demonstrations, but transferring such demonstrations to robot policies remains challenging. We present Contact Wrench Guidance from Human Demonstration in Robotic Dexterous Manipulation (CHORD), a framework for long-horizon manipulation of rigid and articulated objects with reinforcement learning. The key idea is object-centric contact wrench space guidance: we represent human and robot motions by the forces and torques they can induce on the object, enabling similarity to be measured by the induced instantaneous motions. This guidance makes reinforcement learning more scalable for contact-rich dexterous manipulation. We further introduce a large-scale simulation benchmark with 4,739 bimanual dexterous manipulation tasks, constructed from motion-capture datasets and reconstructed in-house videos. Evaluated on 1,831 benchmark tasks, CHORD achieves an average success rate of 82.12%, demonstrating strong scalability. CHORD also generalizes to whole-body manipulation from hand-only and third-person demonstrations, achieving a 90.77% success rate, and the learned policies transfer to the real world in both open-loop and closed-loop settings.
MotionBricks: Scalable Real-Time Motions with Modular Latent Generative Model and Smart Primitives
Apr 27, 2026Despite transformative advances in generative motion synthesis, real-time interactive motion control remains dominated by traditional techniques. In this work, we identify two key challenges in bridging research and production: 1) Real-time scalability: Industry applications demand real-time generation of a vast repertoire of motion skills, while generative methods exhibit significant degradation in quality and scalability under real-time computation constraints, and 2) Integration: Industry applications demand fine-grained multi-modal control involving velocity commands, style selection, and precise keyframes, a need largely unmet by existing text- or tag-driven models. To overcome these limitations, we introduce MotionBricks: a large-scale, real-time generative framework with a two-fold solution. First, we propose a large-scale modular latent generative backbone tailored for robust real-time motion generation, effectively modeling a dataset of over 350,000 motion clips with a single model. Second, we introduce smart primitives that provide a unified, robust, and intuitive interface for authoring both navigation and object interaction. Applications can be designed in a plug-and-play manner like assembling bricks without expert animation knowledge. Quantitatively, we show that MotionBricks produces state-of-the-art motion quality on open-source and proprietary datasets of various scales, while also achieving a real-time throughput of 15,000 FPS with 2ms latency. We demonstrate the flexibility and robustness of MotionBricks in a complete production-level animation demo, covering navigation and object-scene interaction across various styles with a unified model. To showcase our framework's application beyond animation, we deploy MotionBricks on the Unitree G1 humanoid robot to demonstrate its flexibility and generalization for real-time robotic control.
CHIP: Adaptive Compliance for Humanoid Control through Hindsight Perturbation
Dec 16, 2025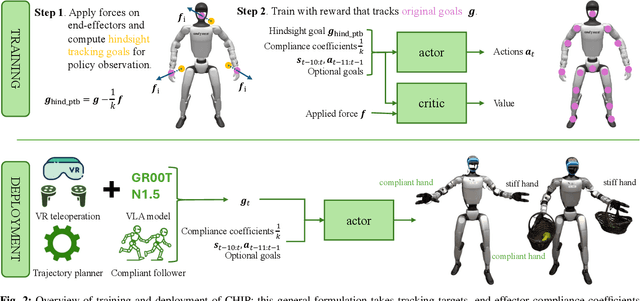
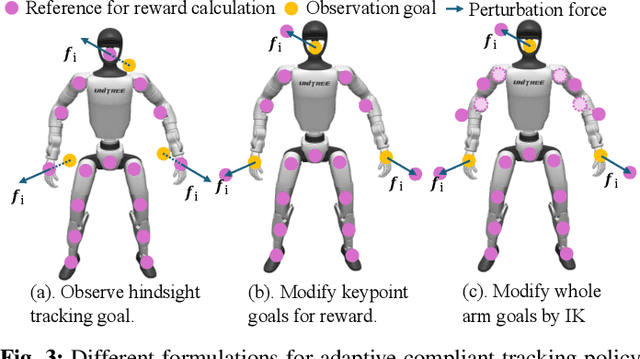
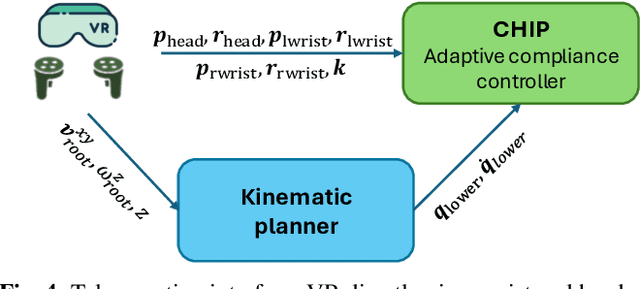

Recent progress in humanoid robots has unlocked agile locomotion skills, including backflipping, running, and crawling. Yet it remains challenging for a humanoid robot to perform forceful manipulation tasks such as moving objects, wiping, and pushing a cart. We propose adaptive Compliance Humanoid control through hIsight Perturbation (CHIP), a plug-and-play module that enables controllable end-effector stiffness while preserving agile tracking of dynamic reference motions. CHIP is easy to implement and requires neither data augmentation nor additional reward tuning. We show that a generalist motion-tracking controller trained with CHIP can perform a diverse set of forceful manipulation tasks that require different end-effector compliance, such as multi-robot collaboration, wiping, box delivery, and door opening.
SONIC: Supersizing Motion Tracking for Natural Humanoid Whole-Body Control
Nov 11, 2025Despite the rise of billion-parameter foundation models trained across thousands of GPUs, similar scaling gains have not been shown for humanoid control. Current neural controllers for humanoids remain modest in size, target a limited behavior set, and are trained on a handful of GPUs over several days. We show that scaling up model capacity, data, and compute yields a generalist humanoid controller capable of creating natural and robust whole-body movements. Specifically, we posit motion tracking as a natural and scalable task for humanoid control, leverageing dense supervision from diverse motion-capture data to acquire human motion priors without manual reward engineering. We build a foundation model for motion tracking by scaling along three axes: network size (from 1.2M to 42M parameters), dataset volume (over 100M frames, 700 hours of high-quality motion data), and compute (9k GPU hours). Beyond demonstrating the benefits of scale, we show the practical utility of our model through two mechanisms: (1) a real-time universal kinematic planner that bridges motion tracking to downstream task execution, enabling natural and interactive control, and (2) a unified token space that supports various motion input interfaces, such as VR teleoperation devices, human videos, and vision-language-action (VLA) models, all using the same policy. Scaling motion tracking exhibits favorable properties: performance improves steadily with increased compute and data diversity, and learned representations generalize to unseen motions, establishing motion tracking at scale as a practical foundation for humanoid control.
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
DexCtrl: Towards Sim-to-Real Dexterity with Adaptive Controller Learning
May 02, 2025


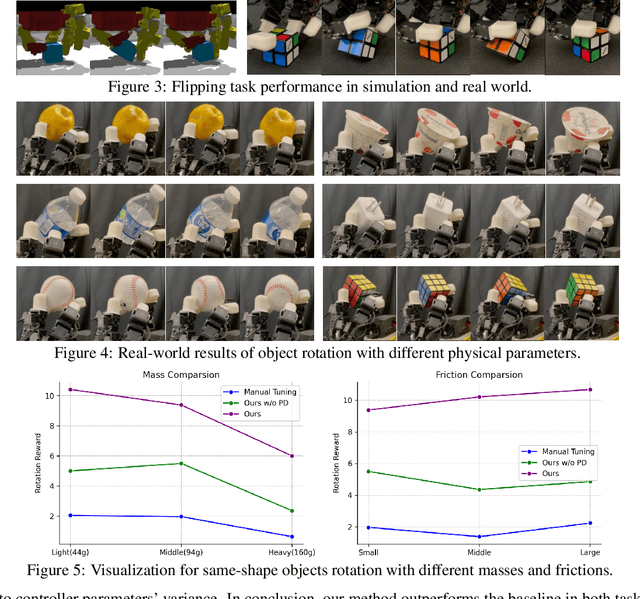
Dexterous manipulation has seen remarkable progress in recent years, with policies capable of executing many complex and contact-rich tasks in simulation. However, transferring these policies from simulation to real world remains a significant challenge. One important issue is the mismatch in low-level controller dynamics, where identical trajectories can lead to vastly different contact forces and behaviors when control parameters vary. Existing approaches often rely on manual tuning or controller randomization, which can be labor-intensive, task-specific, and introduce significant training difficulty. In this work, we propose a framework that jointly learns actions and controller parameters based on the historical information of both trajectory and controller. This adaptive controller adjustment mechanism allows the policy to automatically tune control parameters during execution, thereby mitigating the sim-to-real gap without extensive manual tuning or excessive randomization. Moreover, by explicitly providing controller parameters as part of the observation, our approach facilitates better reasoning over force interactions and improves robustness in real-world scenarios. Experimental results demonstrate that our method achieves improved transfer performance across a variety of dexterous tasks involving variable force conditions.
Residual Policy Gradient: A Reward View of KL-regularized Objective
Mar 14, 2025



Reinforcement Learning and Imitation Learning have achieved widespread success in many domains but remain constrained during real-world deployment. One of the main issues is the additional requirements that were not considered during training. To address this challenge, policy customization has been introduced, aiming to adapt a prior policy while preserving its inherent properties and meeting new task-specific requirements. A principled approach to policy customization is Residual Q-Learning (RQL), which formulates the problem as a Markov Decision Process (MDP) and derives a family of value-based learning algorithms. However, RQL has not yet been applied to policy gradient methods, which restricts its applicability, especially in tasks where policy gradient has already proven more effective. In this work, we first derive a concise form of Soft Policy Gradient as a preliminary. Building on this, we introduce Residual Policy Gradient (RPG), which extends RQL to policy gradient methods, allowing policy customization in gradient-based RL settings. With the view of RPG, we rethink the KL-regularized objective widely used in RL fine-tuning. We show that under certain assumptions, KL-regularized objective leads to a maximum-entropy policy that balances the inherent properties and task-specific requirements on a reward-level. Our experiments in MuJoCo demonstrate the effectiveness of Soft Policy Gradient and Residual Policy Gradient.