 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Informed AV Decision-Making: Computational Model of Well-being and Trust in Mobility
May 21, 2025For future human-autonomous vehicle (AV) interactions to be effective and smooth, human-aware systems that analyze and align human needs with automation decisions are essential. Achieving this requires systems that account for human cognitive states. We present a novel computational model in the form of a Dynamic Bayesian Network (DBN) that infers the cognitive states of both AV users and other road users, integrating this information into the AV's decision-making process. Specifically, our model captures the well-being of both an AV user and an interacting road user as cognitive states alongside trust. Our DBN models infer beliefs over the AV user's evolving well-being, trust, and intention states, as well as the possible well-being of other road users, based on observed interaction experiences. Using data collected from an interaction study, we refine the model parameters and empirically assess its performance. Finally, we extend our model into a causal inference model (CIM) framework for AV decision-making, enabling the AV to enhance user well-being and trust while balancing these factors with its own operational costs and the well-being of interacting road users. Our evaluation demonstrates the model's effectiveness in accurately predicting user's states and guiding informed, human-centered AV decisions.
Optimal Driver Warning Generation in Dynamic Driving Environment
Nov 09, 2024
The driver warning system that alerts the human driver about potential risks during driving is a key feature of an advanced driver assistance system. Existing driver warning technologies, mainly the forward collision warning and unsafe lane change warning, can reduce the risk of collision caused by human errors. However, the current design methods have several major limitations. Firstly, the warnings are mainly generated in a one-shot manner without modeling the ego driver's reactions and surrounding objects, which reduces the flexibility and generality of the system over different scenarios. Additionally, the triggering conditions of warning are mostly rule-based threshold-checking given the current state, which lacks the prediction of the potential risk in a sufficiently long future horizon. In this work, we study the problem of optimally generating driver warnings by considering the interactions among the generated warning, the driver behavior, and the states of ego and surrounding vehicles on a long horizon. The warning generation problem is formulated as a partially observed Markov decision process (POMDP). An optimal warning generation framework is proposed as a solution to the proposed POMDP. The simulation experiments demonstrate the superiority of the proposed solution to the existing warning generation methods.
Can we enhance prosocial behavior? Using post-ride feedback to improve micromobility interactions
Sep 05, 2024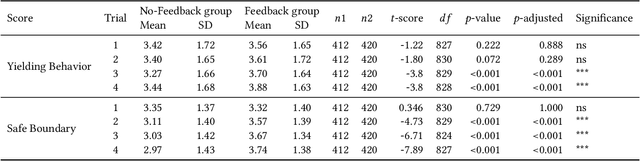


Micromobility devices, such as e-scooters and delivery robots, hold promise for eco-friendly and cost-effective alternatives for future urban transportation. However, their lack of societal acceptance remains a challenge. Therefore, we must consider ways to promote prosocial behavior in micromobility interactions. We investigate how post-ride feedback can encourage the prosocial behavior of e-scooter riders while interacting with sidewalk users, including pedestrians and delivery robots. Using a web-based platform, we measure the prosocial behavior of e-scooter riders. Results found that post-ride feedback can successfully promote prosocial behavior, and objective measures indicated better gap behavior, lower speeds at interaction, and longer stopping time around other sidewalk actors. The findings of this study demonstrate the efficacy of post-ride feedback and provide a step toward designing methodologies to improve the prosocial behavior of mobility users.
Should I Help a Delivery Robot? Cultivating Prosocial Norms through Observations
Mar 27, 2024
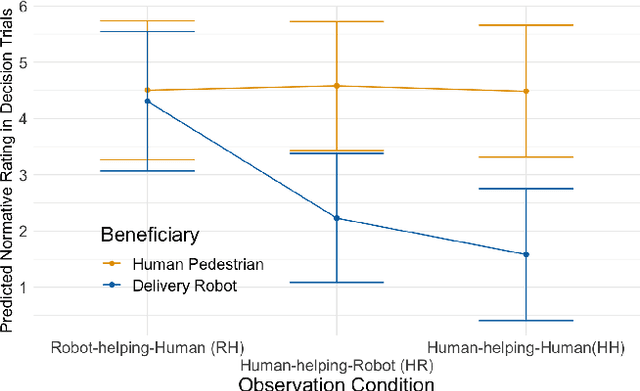
We propose leveraging prosocial observations to cultivate new social norms to encourage prosocial behaviors toward delivery robots. With an online experiment, we quantitatively assess updates in norm beliefs regarding human-robot prosocial behaviors through observational learning. Results demonstrate the initially perceived normativity of helping robots is influenced by familiarity with delivery robots and perceptions of robots' social intelligence. Observing human-robot prosocial interactions notably shifts peoples' normative beliefs about prosocial actions; thereby changing their perceived obligations to offer help to delivery robots. Additionally, we found that observing robots offering help to humans, rather than receiving help, more significantly increased participants' feelings of obligation to help robots. Our findings provide insights into prosocial design for future mobility systems. Improved familiarity with robot capabilities and portraying them as desirable social partners can help foster wider acceptance. Furthermore, robots need to be designed to exhibit higher levels of interactivity and reciprocal capabilities for prosocial behavior.
Beyond Empirical Windowing: An Attention-Based Approach for Trust Prediction in Autonomous Vehicles
Dec 15, 2023Humans' internal states play a key role in human-machine interaction, leading to the rise of human state estimation as a prominent field. Compared to swift state changes such as surprise and irritation, modeling gradual states like trust and satisfaction are further challenged by label sparsity: long time-series signals are usually associated with a single label, making it difficult to identify the critical span of state shifts. Windowing has been one widely-used technique to enable localized analysis of long time-series data. However, the performance of downstream models can be sensitive to the window size, and determining the optimal window size demands domain expertise and extensive search. To address this challenge, we propose a Selective Windowing Attention Network (SWAN), which employs window prompts and masked attention transformation to enable the selection of attended intervals with flexible lengths. We evaluate SWAN on the task of trust prediction on a new multimodal driving simulation dataset. Experiments show that SWAN significantly outperforms an existing empirical window selection baseline and neural network baselines including CNN-LSTM and Transformer. Furthermore, it shows robustness across a wide span of windowing ranges, compared to the traditional windowing approach.
ViCor: Bridging Visual Understanding and Commonsense Reasoning with Large Language Models
Oct 09, 2023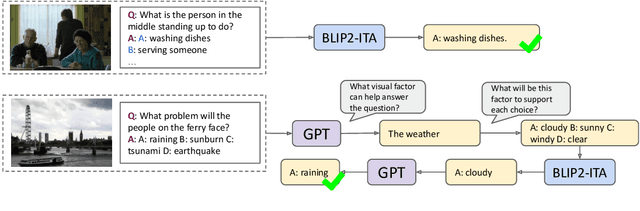


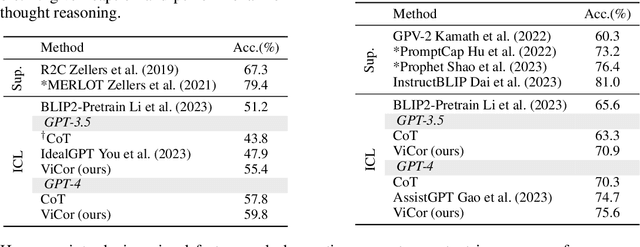
In our work, we explore the synergistic capabilities of pre-trained vision-and-language models (VLMs) and large language models (LLMs) for visual commonsense reasoning (VCR). We categorize the problem of VCR into visual commonsense understanding (VCU) and visual commonsense inference (VCI). For VCU, which involves perceiving the literal visual content, pre-trained VLMs exhibit strong cross-dataset generalization. On the other hand, in VCI, where the goal is to infer conclusions beyond image content, VLMs face difficulties. We find that a baseline where VLMs provide perception results (image captions) to LLMs leads to improved performance on VCI. However, we identify a challenge with VLMs' passive perception, which often misses crucial context information, leading to incorrect or uncertain reasoning by LLMs. To mitigate this issue, we suggest a collaborative approach where LLMs, when uncertain about their reasoning, actively direct VLMs to concentrate on and gather relevant visual elements to support potential commonsense inferences. In our method, named ViCor, pre-trained LLMs serve as problem classifiers to analyze the problem category, VLM commanders to leverage VLMs differently based on the problem classification, and visual commonsense reasoners to answer the question. VLMs will perform visual recognition and understanding. We evaluate our framework on two VCR benchmark datasets and outperform all other methods that do not require in-domain supervised fine-tuning.
Wellbeing in Future Mobility: Toward AV Policy Design to Increase Wellbeing through Interactions
Oct 02, 2023


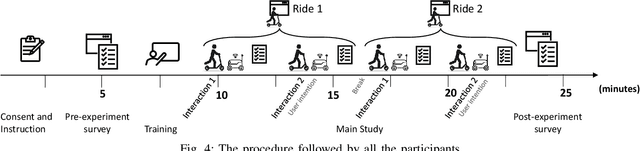
Recent advances in Automated vehicle (AV) technology and micromobility devices promise a transformational change in the future of mobility usage. These advances also pose challenges concerning human-AV interactions. To ensure the smooth adoption of these new mobilities, it is essential to assess how past experiences and perceptions of social interactions by people may impact the interactions with AV mobility. This research identifies and estimates an individual's wellbeing based on their actions, prior experiences, social interaction perceptions, and dyadic interactions with other road users. An online video-based user study was designed, and responses from 300 participants were collected and analyzed to investigate the impact on individual wellbeing. A machine learning model was designed to predict the change in wellbeing. An optimal policy based on the model allows informed AV actions toward its yielding behavior with other road users to enhance users' wellbeing. The findings from this study have broader implications for creating human-aware systems by creating policies that align with the individual state and contribute toward designing systems that align with an individual's state of wellbeing.
Trust in Shared Automated Vehicles: Study on Two Mobility Platforms
Mar 17, 2023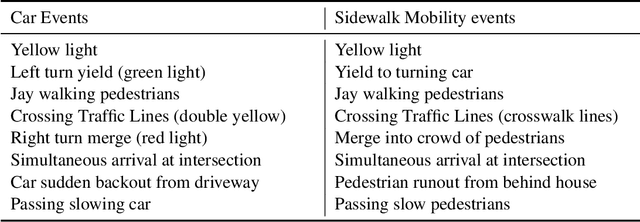

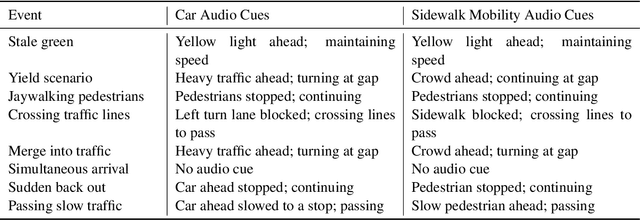

The ever-increasing adoption of shared transportation modalities across the United States has the potential to fundamentally change the preferences and usage of different mobilities. It also raises several challenges with respect to the design and development of automated mobilities that can enable a large population to take advantage of this emergent technology. One such challenge is the lack of understanding of how trust in one automated mobility may impact trust in another. Without this understanding, it is difficult for researchers to determine whether future mobility solutions will have acceptance within different population groups. This study focuses on identifying the differences in trust across different mobility and how trust evolves across their use for participants who preferred an aggressive driving style. A dual mobility simulator study was designed in which 48 participants experienced two different automated mobilities (car and sidewalk). The results found that participants showed increasing levels of trust when they transitioned from the car to the sidewalk mobility. In comparison, participants showed decreasing levels of trust when they transitioned from the sidewalk to the car mobility. The findings from the study help inform and identify how people can develop trust in future mobility platforms and could inform the design of interventions that may help improve the trust and acceptance of future mobility.
* https://trid.trb.org/view/2117834
Identification of Adaptive Driving Style Preference through Implicit Inputs in SAE L2 Vehicles
Sep 21, 2022
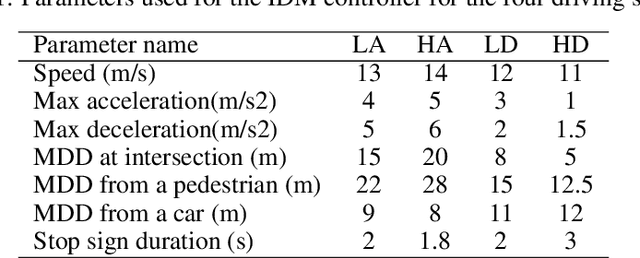
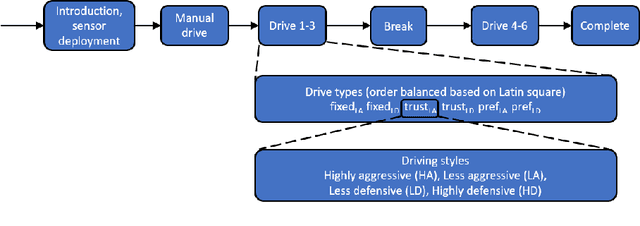

A key factor to optimal acceptance and comfort of automated vehicle features is the driving style. Mismatches between the automated and the driver preferred driving styles can make users take over more frequently or even disable the automation features. This work proposes identification of user driving style preference with multimodal signals, so the vehicle could match user preference in a continuous and automatic way. We conducted a driving simulator study with 36 participants and collected extensive multimodal data including behavioral, physiological, and situational data. This includes eye gaze, steering grip force, driving maneuvers, brake and throttle pedal inputs as well as foot distance from pedals, pupil diameter, galvanic skin response, heart rate, and situational drive context. Then, we built machine learning models to identify preferred driving styles, and confirmed that all modalities are important for the identification of user preference. This work paves the road for implicit adaptive driving styles on automated vehicles.
Effects of Augmented-Reality-Based Assisting Interfaces on Drivers' Object-wise Situational Awareness in Highly Autonomous Vehicles
Jun 06, 2022


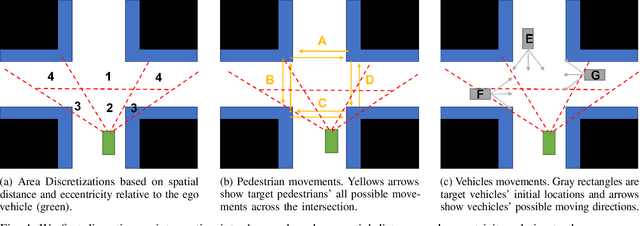
Although partially autonomous driving (AD) systems are already available in production vehicles, drivers are still required to maintain a sufficient level of situational awareness (SA) during driving. Previous studies have shown that providing information about the AD's capability using user interfaces can improve the driver's SA. However, displaying too much information increases the driver's workload and can distract or overwhelm the driver. Therefore, to design an efficient user interface (UI), it is necessary to understand its effect under different circumstances. In this paper, we focus on a UI based on augmented reality (AR), which can highlight potential hazards on the road. To understand the effect of highlighting on drivers' SA for objects with different types and locations under various traffic densities, we conducted an in-person experiment with 20 participants on a driving simulator. Our study results show that the effects of highlighting on drivers' SA varied by traffic densities, object locations and object types. We believe our study can provide guidance in selecting which object to highlight for the AR-based driver-assistance interface to optimize SA for drivers driving and monitoring partially autonomous vehicles.