 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Distillation of Emotion Knowledge from LLMs for Zero-Shot Emotion Recognition
May 23, 2025The ability to handle various emotion labels without dedicated training is crucial for building adaptable Emotion Recognition (ER) systems. Conventional ER models rely on training using fixed label sets and struggle to generalize beyond them. On the other hand, Large Language Models (LLMs) have shown strong zero-shot ER performance across diverse label spaces, but their scale limits their use on edge devices. In this work, we propose a contrastive distillation framework that transfers rich emotional knowledge from LLMs into a compact model without the use of human annotations. We use GPT-4 to generate descriptive emotion annotations, offering rich supervision beyond fixed label sets. By aligning text samples with emotion descriptors in a shared embedding space, our method enables zero-shot prediction on different emotion classes, granularity, and label schema. The distilled model is effective across multiple datasets and label spaces, outperforming strong baselines of similar size and approaching GPT-4's zero-shot performance, while being over 10,000 times smaller.
Rethinking Emotion Annotations in the Era of Large Language Models
Dec 10, 2024
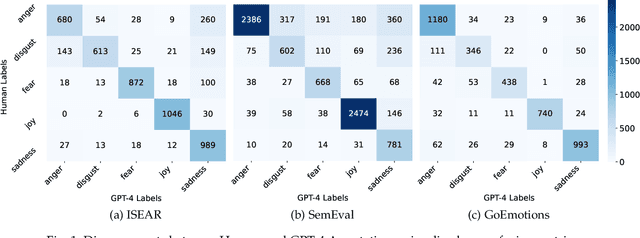
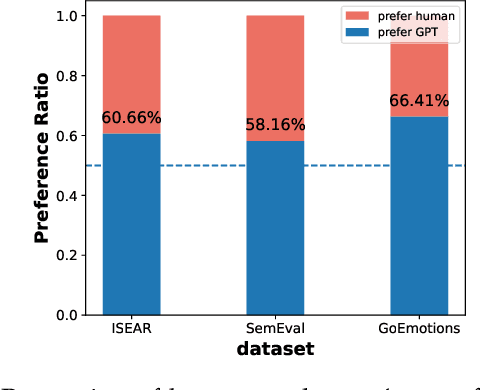
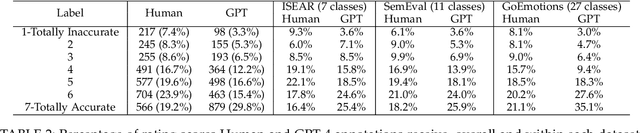
Modern affective computing systems rely heavily on datasets with human-annotated emotion labels, for training and evaluation. However, human annotations are expensive to obtain, sensitive to study design, and difficult to quality control, because of the subjective nature of emotions. Meanwhile, Large Language Models (LLMs) have shown remarkable performance on many Natural Language Understanding tasks, emerging as a promising tool for text annotation. In this work, we analyze the complexities of emotion annotation in the context of LLMs, focusing on GPT-4 as a leading model. In our experiments, GPT-4 achieves high ratings in a human evaluation study, painting a more positive picture than previous work, in which human labels served as the only ground truth. On the other hand, we observe differences between human and GPT-4 emotion perception, underscoring the importance of human input in annotation studies. To harness GPT-4's strength while preserving human perspective, we explore two ways of integrating GPT-4 into emotion annotation pipelines, showing its potential to flag low-quality labels, reduce the workload of human annotators, and improve downstream model learning performance and efficiency. Together, our findings highlight opportunities for new emotion labeling practices and suggest the use of LLMs as a promising tool to aid human annotation.
From Text to Emotion: Unveiling the Emotion Annotation Capabilities of LLMs
Aug 30, 2024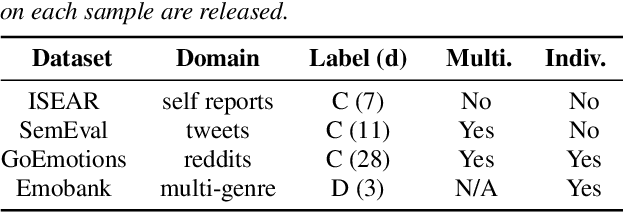
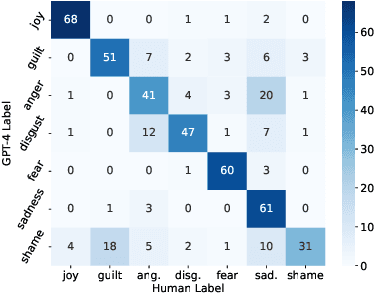
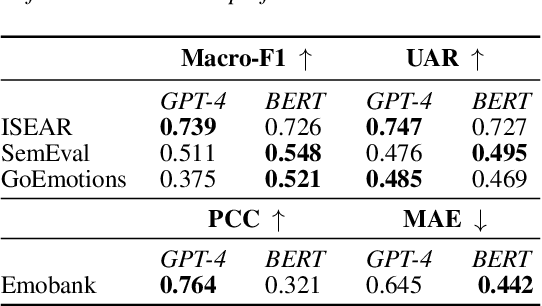
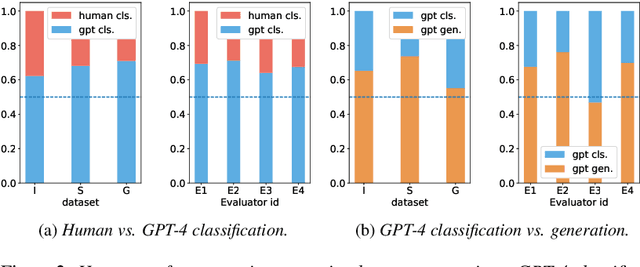
Training emotion recognition models has relied heavily on human annotated data, which present diversity, quality, and cost challenges. In this paper, we explore the potential of Large Language Models (LLMs), specifically GPT4, in automating or assisting emotion annotation. We compare GPT4 with supervised models and or humans in three aspects: agreement with human annotations, alignment with human perception, and impact on model training. We find that common metrics that use aggregated human annotations as ground truth can underestimate the performance, of GPT-4 and our human evaluation experiment reveals a consistent preference for GPT-4 annotations over humans across multiple datasets and evaluators. Further, we investigate the impact of using GPT-4 as an annotation filtering process to improve model training. Together, our findings highlight the great potential of LLMs in emotion annotation tasks and underscore the need for refined evaluation methodologies.
Beyond Binary: Multiclass Paraphasia Detection with Generative Pretrained Transformers and End-to-End Models
Jul 16, 2024
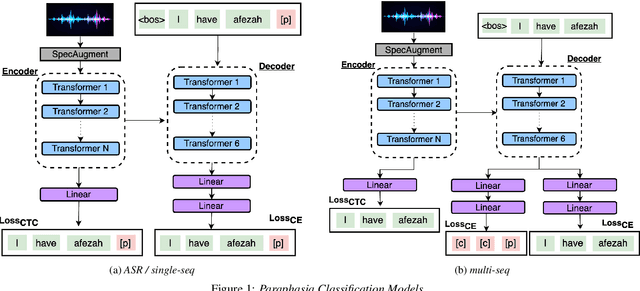
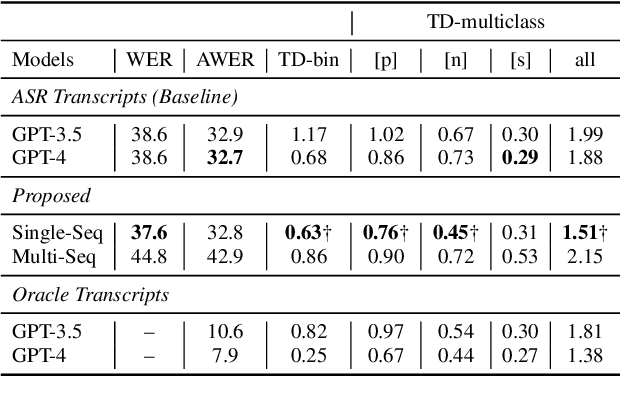
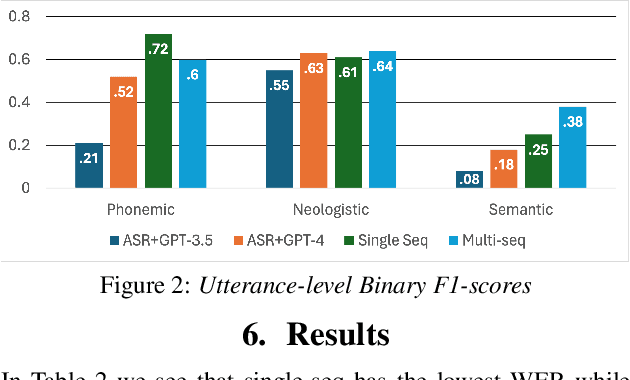
Aphasia is a language disorder that can lead to speech errors known as paraphasias, which involve the misuse, substitution, or invention of words. Automatic paraphasia detection can help those with Aphasia by facilitating clinical assessment and treatment planning options. However, most automatic paraphasia detection works have focused solely on binary detection, which involves recognizing only the presence or absence of a paraphasia. Multiclass paraphasia detection represents an unexplored area of research that focuses on identifying multiple types of paraphasias and where they occur in a given speech segment. We present novel approaches that use a generative pretrained transformer (GPT) to identify paraphasias from transcripts as well as two end-to-end approaches that focus on modeling both automatic speech recognition (ASR) and paraphasia classification as multiple sequences vs. a single sequence. We demonstrate that a single sequence model outperforms GPT baselines for multiclass paraphasia detection.
Beyond Empirical Windowing: An Attention-Based Approach for Trust Prediction in Autonomous Vehicles
Dec 15, 2023Humans' internal states play a key role in human-machine interaction, leading to the rise of human state estimation as a prominent field. Compared to swift state changes such as surprise and irritation, modeling gradual states like trust and satisfaction are further challenged by label sparsity: long time-series signals are usually associated with a single label, making it difficult to identify the critical span of state shifts. Windowing has been one widely-used technique to enable localized analysis of long time-series data. However, the performance of downstream models can be sensitive to the window size, and determining the optimal window size demands domain expertise and extensive search. To address this challenge, we propose a Selective Windowing Attention Network (SWAN), which employs window prompts and masked attention transformation to enable the selection of attended intervals with flexible lengths. We evaluate SWAN on the task of trust prediction on a new multimodal driving simulation dataset. Experiments show that SWAN significantly outperforms an existing empirical window selection baseline and neural network baselines including CNN-LSTM and Transformer. Furthermore, it shows robustness across a wide span of windowing ranges, compared to the traditional windowing approach.