 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffect Models Have Weak Generalizability to Atypical Speech
Apr 22, 2025Speech and voice conditions can alter the acoustic properties of speech, which could impact the performance of paralinguistic models for affect for people with atypical speech. We evaluate publicly available models for recognizing categorical and dimensional affect from speech on a dataset of atypical speech, comparing results to datasets of typical speech. We investigate three dimensions of speech atypicality: intelligibility, which is related to pronounciation; monopitch, which is related to prosody, and harshness, which is related to voice quality. We look at (1) distributional trends of categorical affect predictions within the dataset, (2) distributional comparisons of categorical affect predictions to similar datasets of typical speech, and (3) correlation strengths between text and speech predictions for spontaneous speech for valence and arousal. We find that the output of affect models is significantly impacted by the presence and degree of speech atypicalities. For instance, the percentage of speech predicted as sad is significantly higher for all types and grades of atypical speech when compared to similar typical speech datasets. In a preliminary investigation on improving robustness for atypical speech, we find that fine-tuning models on pseudo-labeled atypical speech data improves performance on atypical speech without impacting performance on typical speech. Our results emphasize the need for broader training and evaluation datasets for speech emotion models, and for modeling approaches that are robust to voice and speech differences.
Rethinking Emotion Annotations in the Era of Large Language Models
Dec 10, 2024
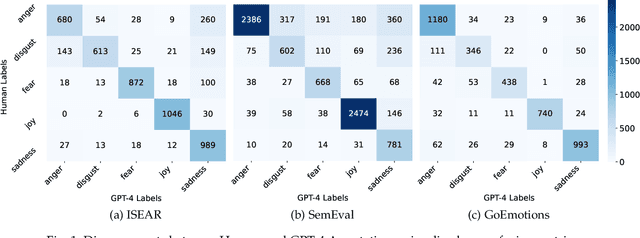
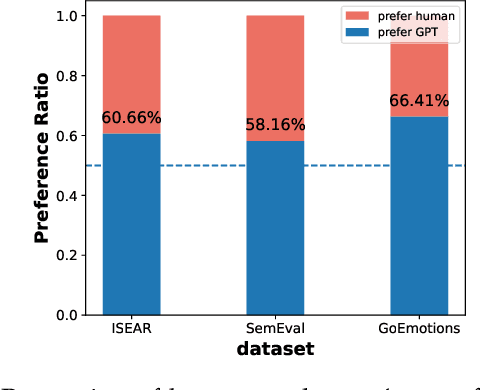
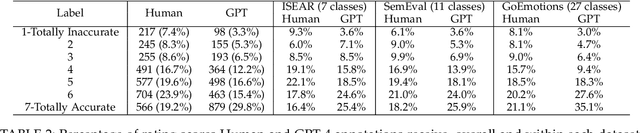
Modern affective computing systems rely heavily on datasets with human-annotated emotion labels, for training and evaluation. However, human annotations are expensive to obtain, sensitive to study design, and difficult to quality control, because of the subjective nature of emotions. Meanwhile, Large Language Models (LLMs) have shown remarkable performance on many Natural Language Understanding tasks, emerging as a promising tool for text annotation. In this work, we analyze the complexities of emotion annotation in the context of LLMs, focusing on GPT-4 as a leading model. In our experiments, GPT-4 achieves high ratings in a human evaluation study, painting a more positive picture than previous work, in which human labels served as the only ground truth. On the other hand, we observe differences between human and GPT-4 emotion perception, underscoring the importance of human input in annotation studies. To harness GPT-4's strength while preserving human perspective, we explore two ways of integrating GPT-4 into emotion annotation pipelines, showing its potential to flag low-quality labels, reduce the workload of human annotators, and improve downstream model learning performance and efficiency. Together, our findings highlight opportunities for new emotion labeling practices and suggest the use of LLMs as a promising tool to aid human annotation.
Seq2seq for Automatic Paraphasia Detection in Aphasic Speech
Dec 16, 2023Paraphasias are speech errors that are often characteristic of aphasia and they represent an important signal in assessing disease severity and subtype. Traditionally, clinicians manually identify paraphasias by transcribing and analyzing speech-language samples, which can be a time-consuming and burdensome process. Identifying paraphasias automatically can greatly help clinicians with the transcription process and ultimately facilitate more efficient and consistent aphasia assessment. Previous research has demonstrated the feasibility of automatic paraphasia detection by training an automatic speech recognition (ASR) model to extract transcripts and then training a separate paraphasia detection model on a set of hand-engineered features. In this paper, we propose a novel, sequence-to-sequence (seq2seq) model that is trained end-to-end (E2E) to perform both ASR and paraphasia detection tasks. We show that the proposed model outperforms the previous state-of-the-art approach for both word-level and utterance-level paraphasia detection tasks and provide additional follow-up evaluations to further understand the proposed model behavior.
Automatic Disfluency Detection from Untranscribed Speech
Nov 01, 2023
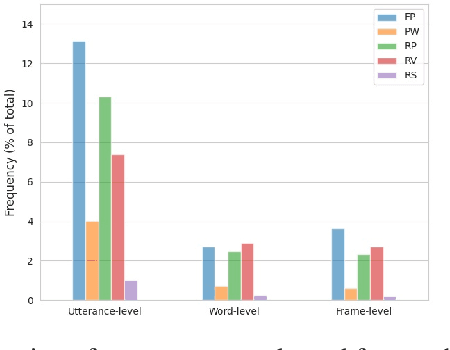
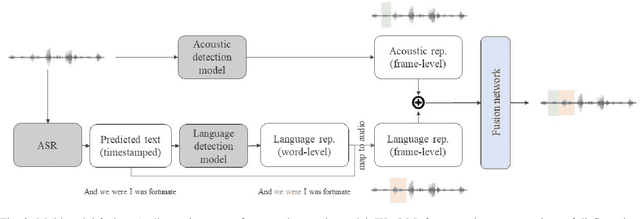
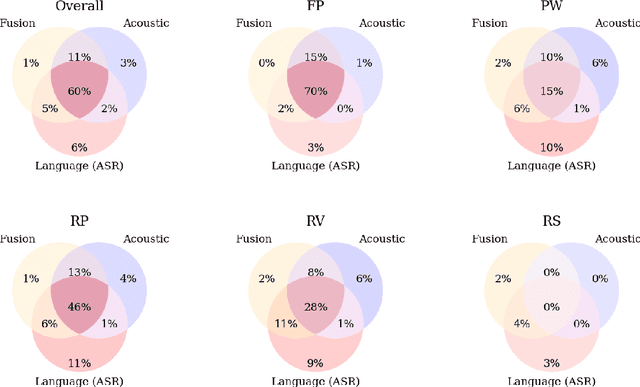
Speech disfluencies, such as filled pauses or repetitions, are disruptions in the typical flow of speech. Stuttering is a speech disorder characterized by a high rate of disfluencies, but all individuals speak with some disfluencies and the rates of disfluencies may by increased by factors such as cognitive load. Clinically, automatic disfluency detection may help in treatment planning for individuals who stutter. Outside of the clinic, automatic disfluency detection may serve as a pre-processing step to improve natural language understanding in downstream applications. With this wide range of applications in mind, we investigate language, acoustic, and multimodal methods for frame-level automatic disfluency detection and categorization. Each of these methods relies on audio as an input. First, we evaluate several automatic speech recognition (ASR) systems in terms of their ability to transcribe disfluencies, measured using disfluency error rates. We then use these ASR transcripts as input to a language-based disfluency detection model. We find that disfluency detection performance is largely limited by the quality of transcripts and alignments. We find that an acoustic-based approach that does not require transcription as an intermediate step outperforms the ASR language approach. Finally, we present multimodal architectures which we find improve disfluency detection performance over the unimodal approaches. Ultimately, this work introduces novel approaches for automatic frame-level disfluency and categorization. In the long term, this will help researchers incorporate automatic disfluency detection into a range of applications.
Articulatory Coordination for Speech Motor Tracking in Huntington Disease
Sep 28, 2021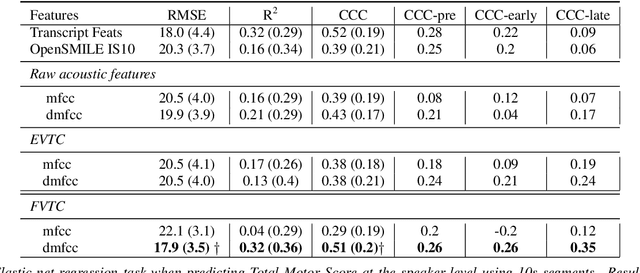
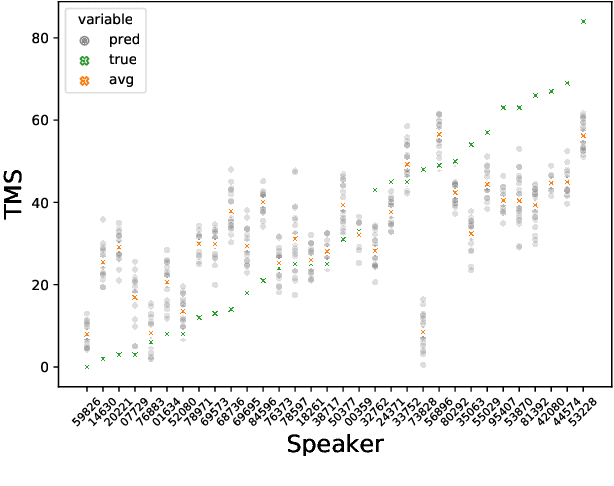
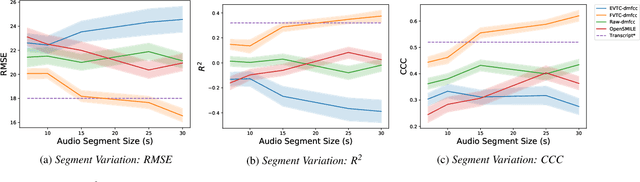
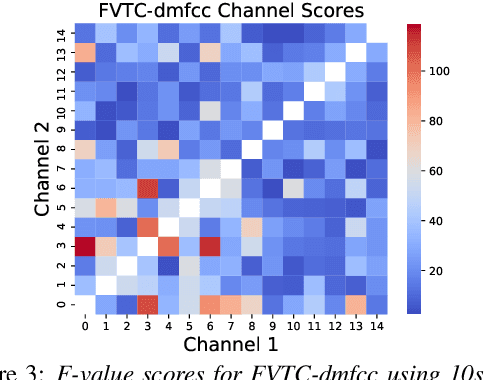
Huntington Disease (HD) is a progressive disorder which often manifests in motor impairment. Motor severity (captured via motor score) is a key component in assessing overall HD severity. However, motor score evaluation involves in-clinic visits with a trained medical professional, which are expensive and not always accessible. Speech analysis provides an attractive avenue for tracking HD severity because speech is easy to collect remotely and provides insight into motor changes. HD speech is typically characterized as having irregular articulation. With this in mind, acoustic features that can capture vocal tract movement and articulatory coordination are particularly promising for characterizing motor symptom progression in HD. In this paper, we present an experiment that uses Vocal Tract Coordination (VTC) features extracted from read speech to estimate a motor score. When using an elastic-net regression model, we find that VTC features significantly outperform other acoustic features across varied-length audio segments, which highlights the effectiveness of these features for both short- and long-form reading tasks. Lastly, we analyze the F-value scores of VTC features to visualize which channels are most related to motor score. This work enables future research efforts to consider VTC features for acoustic analyses which target HD motor symptomatology tracking.
Accounting for Variations in Speech Emotion Recognition with Nonparametric Hierarchical Neural Network
Sep 09, 2021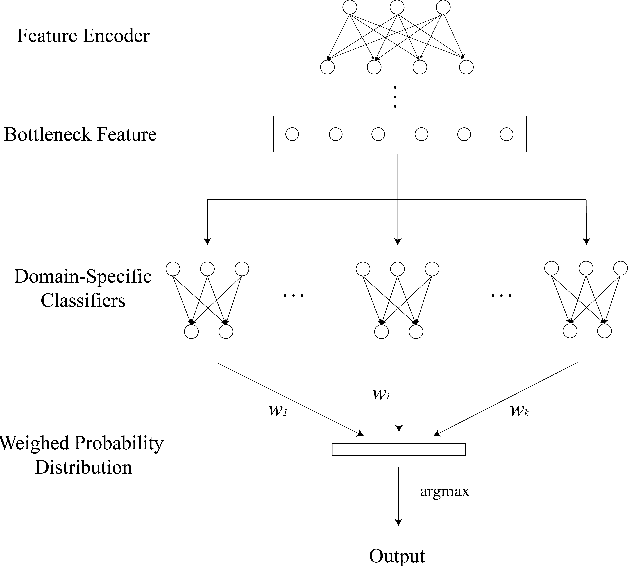

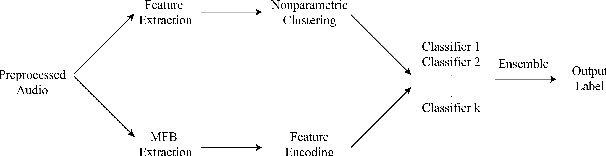

In recent years, deep-learning-based speech emotion recognition models have outperformed classical machine learning models. Previously, neural network designs, such as Multitask Learning, have accounted for variations in emotional expressions due to demographic and contextual factors. However, existing models face a few constraints: 1) they rely on a clear definition of domains (e.g. gender, noise condition, etc.) and the availability of domain labels; 2) they often attempt to learn domain-invariant features while emotion expressions can be domain-specific. In the present study, we propose the Nonparametric Hierarchical Neural Network (NHNN), a lightweight hierarchical neural network model based on Bayesian nonparametric clustering. In comparison to Multitask Learning approaches, the proposed model does not require domain/task labels. In our experiments, the NHNN models generally outperform the models with similar levels of complexity and state-of-the-art models in within-corpus and cross-corpus tests. Through clustering analysis, we show that the NHNN models are able to learn group-specific features and bridge the performance gap between groups.