 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMELD: Mel-Spectrogram-Based Speech Language Modeling with Discrete Latent Variables
May 28, 2026Recent speech language models rely on encoders that are optimized separately from autoregressive models. Since these encoders are unaware of the downstream objectives, the extracted representations may not be optimal for downstream tasks. To address this limitation, we introduce a discrete latent variable model on mel spectrograms that jointly optimizes the encoder and the speech language model. Joint optimization not only brings improvements over codec-based and other mel-spectrogram-based baselines on zero-shot Text-to-Speech (TTS) and Speech-to-Text (STT) tasks, but also effectively alleviates common issues in autoregressive mel-spectrogram modeling, such as prolonged silence generation and word omissions.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Physics-informed Ground Reaction Dynamics from Human Motion Capture
Jul 02, 2025
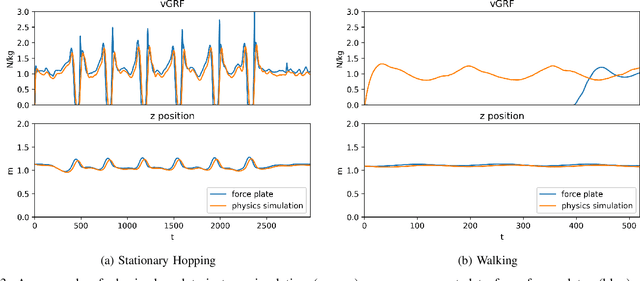


Body dynamics are crucial information for the analysis of human motions in important research fields, ranging from biomechanics, sports science to computer vision and graphics. Modern approaches collect the body dynamics, external reactive force specifically, via force plates, synchronizing with human motion capture data, and learn to estimate the dynamics from a black-box deep learning model. Being specialized devices, force plates can only be installed in laboratory setups, imposing a significant limitation on the learning of human dynamics. To this end, we propose a novel method for estimating human ground reaction dynamics directly from the more reliable motion capture data with physics laws and computational simulation as constrains. We introduce a highly accurate and robust method for computing ground reaction forces from motion capture data using Euler's integration scheme and PD algorithm. The physics-based reactive forces are used to inform the learning model about the physics-informed motion dynamics thus improving the estimation accuracy. The proposed approach was tested on the GroundLink dataset, outperforming the baseline model on: 1) the ground reaction force estimation accuracy compared to the force plates measurement; and 2) our simulated root trajectory precision. The implementation code is available at https://github.com/cuongle1206/Phys-GRD
From Visual Explanations to Counterfactual Explanations with Latent Diffusion
Apr 12, 2025



Visual counterfactual explanations are ideal hypothetical images that change the decision-making of the classifier with high confidence toward the desired class while remaining visually plausible and close to the initial image. In this paper, we propose a new approach to tackle two key challenges in recent prominent works: i) determining which specific counterfactual features are crucial for distinguishing the "concept" of the target class from the original class, and ii) supplying valuable explanations for the non-robust classifier without relying on the support of an adversarially robust model. Our method identifies the essential region for modification through algorithms that provide visual explanations, and then our framework generates realistic counterfactual explanations by combining adversarial attacks based on pruning the adversarial gradient of the target classifier and the latent diffusion model. The proposed method outperforms previous state-of-the-art results on various evaluation criteria on ImageNet and CelebA-HQ datasets. In general, our method can be applied to arbitrary classifiers, highlight the strong association between visual and counterfactual explanations, make semantically meaningful changes from the target classifier, and provide observers with subtle counterfactual images.
* 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Textless Streaming Speech-to-Speech Translation using Semantic Speech Tokens
Oct 04, 2024



Cascaded speech-to-speech translation systems often suffer from the error accumulation problem and high latency, which is a result of cascaded modules whose inference delays accumulate. In this paper, we propose a transducer-based speech translation model that outputs discrete speech tokens in a low-latency streaming fashion. This approach eliminates the need for generating text output first, followed by machine translation (MT) and text-to-speech (TTS) systems. The produced speech tokens can be directly used to generate a speech signal with low latency by utilizing an acoustic language model (LM) to obtain acoustic tokens and an audio codec model to retrieve the waveform. Experimental results show that the proposed method outperforms other existing approaches and achieves state-of-the-art results for streaming translation in terms of BLEU, average latency, and BLASER 2.0 scores for multiple language pairs using the CVSS-C dataset as a benchmark.
Seed-Music: A Unified Framework for High Quality and Controlled Music Generation
Sep 13, 2024



We introduce Seed-Music, a suite of music generation systems capable of producing high-quality music with fine-grained style control. Our unified framework leverages both auto-regressive language modeling and diffusion approaches to support two key music creation workflows: \textit{controlled music generation} and \textit{post-production editing}. For controlled music generation, our system enables vocal music generation with performance controls from multi-modal inputs, including style descriptions, audio references, musical scores, and voice prompts. For post-production editing, it offers interactive tools for editing lyrics and vocal melodies directly in the generated audio. We encourage readers to listen to demo audio examples at https://team.doubao.com/seed-music .
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
PRoDeliberation: Parallel Robust Deliberation for End-to-End Spoken Language Understanding
Jun 12, 2024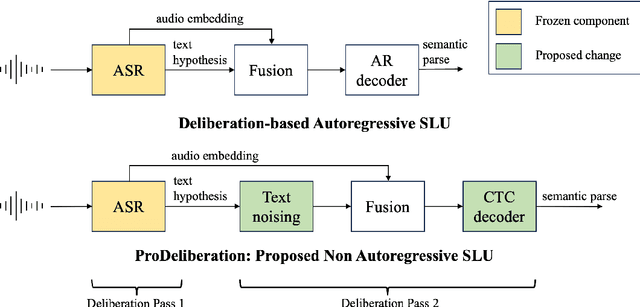
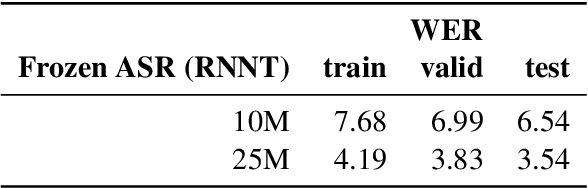
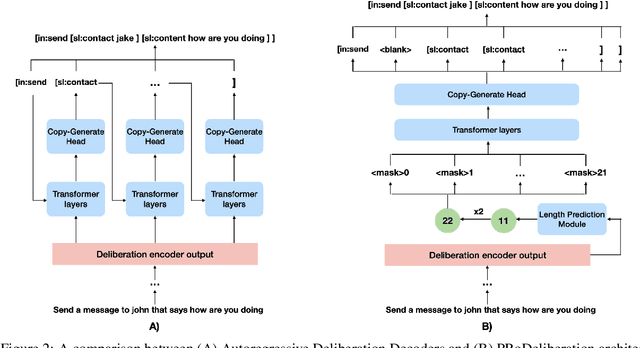

Spoken Language Understanding (SLU) is a critical component of voice assistants; it consists of converting speech to semantic parses for task execution. Previous works have explored end-to-end models to improve the quality and robustness of SLU models with Deliberation, however these models have remained autoregressive, resulting in higher latencies. In this work we introduce PRoDeliberation, a novel method leveraging a Connectionist Temporal Classification-based decoding strategy as well as a denoising objective to train robust non-autoregressive deliberation models. We show that PRoDeliberation achieves the latency reduction of parallel decoding (2-10x improvement over autoregressive models) while retaining the ability to correct Automatic Speech Recognition (ASR) mistranscriptions of autoregressive deliberation systems. We further show that the design of the denoising training allows PRoDeliberation to overcome the limitations of small ASR devices, and we provide analysis on the necessity of each component of the system.
Seq2seq for Automatic Paraphasia Detection in Aphasic Speech
Dec 16, 2023Paraphasias are speech errors that are often characteristic of aphasia and they represent an important signal in assessing disease severity and subtype. Traditionally, clinicians manually identify paraphasias by transcribing and analyzing speech-language samples, which can be a time-consuming and burdensome process. Identifying paraphasias automatically can greatly help clinicians with the transcription process and ultimately facilitate more efficient and consistent aphasia assessment. Previous research has demonstrated the feasibility of automatic paraphasia detection by training an automatic speech recognition (ASR) model to extract transcripts and then training a separate paraphasia detection model on a set of hand-engineered features. In this paper, we propose a novel, sequence-to-sequence (seq2seq) model that is trained end-to-end (E2E) to perform both ASR and paraphasia detection tasks. We show that the proposed model outperforms the previous state-of-the-art approach for both word-level and utterance-level paraphasia detection tasks and provide additional follow-up evaluations to further understand the proposed model behavior.
StemGen: A music generation model that listens
Dec 14, 2023

End-to-end generation of musical audio using deep learning techniques has seen an explosion of activity recently. However, most models concentrate on generating fully mixed music in response to abstract conditioning information. In this work, we present an alternative paradigm for producing music generation models that can listen and respond to musical context. We describe how such a model can be constructed using a non-autoregressive, transformer-based model architecture and present a number of novel architectural and sampling improvements. We train the described architecture on both an open-source and a proprietary dataset. We evaluate the produced models using standard quality metrics and a new approach based on music information retrieval descriptors. The resulting model reaches the audio quality of state-of-the-art text-conditioned models, as well as exhibiting strong musical coherence with its context.