 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho is Speaking or Who is Depressed? A Controlled Study of Speaker Leakage in Speech-Based Depression Detection
Apr 15, 2026This study investigates whether speech-based depression detection models learn depression-related acoustic biomarkers or instead rely on speaker identity cues. Using the DAIC-WOZ dataset, we propose a data-splitting strategy that controls speaker overlap between training and test sets while keeping the training size constant, and evaluate three models of varying complexity. Results show that speaker overlap significantly boosts performance, whereas accuracy drops sharply on unseen speakers. Even with a Domain-Adversarial Neural Network, a substantial performance gap remains. These findings indicate that depression-related features extracted by current speech models are highly entangled with speaker identity. Conventional evaluation protocols may therefore overestimate generalization and clinical utility, highlighting the need for strictly speaker-independent evaluation.
What You Feel Is Not What They See: On Predicting Self-Reported Emotion from Third-Party Observer Labels
Jan 29, 2026Self-reported emotion labels capture internal experience, while third-party labels reflect external perception. These perspectives often diverge, limiting the applicability of third-party-trained models to self-report contexts. This gap is critical in mental health, where accurate self-report modeling is essential for guiding intervention. We present the first cross-corpus evaluation of third-party-trained models on self-reports. We find activation unpredictable (CCC approximately 0) and valence moderately predictable (CCC approximately 0.3). Crucially, when content is personally significant to the speaker, models achieve high performance for valence (CCC approximately 0.6-0.8). Our findings point to personal significance as a key pathway for aligning external perception with internal experience and underscore the challenge of self-report activation modeling.
Contrastive Distillation of Emotion Knowledge from LLMs for Zero-Shot Emotion Recognition
May 23, 2025The ability to handle various emotion labels without dedicated training is crucial for building adaptable Emotion Recognition (ER) systems. Conventional ER models rely on training using fixed label sets and struggle to generalize beyond them. On the other hand, Large Language Models (LLMs) have shown strong zero-shot ER performance across diverse label spaces, but their scale limits their use on edge devices. In this work, we propose a contrastive distillation framework that transfers rich emotional knowledge from LLMs into a compact model without the use of human annotations. We use GPT-4 to generate descriptive emotion annotations, offering rich supervision beyond fixed label sets. By aligning text samples with emotion descriptors in a shared embedding space, our method enables zero-shot prediction on different emotion classes, granularity, and label schema. The distilled model is effective across multiple datasets and label spaces, outperforming strong baselines of similar size and approaching GPT-4's zero-shot performance, while being over 10,000 times smaller.
Rethinking Emotion Annotations in the Era of Large Language Models
Dec 10, 2024
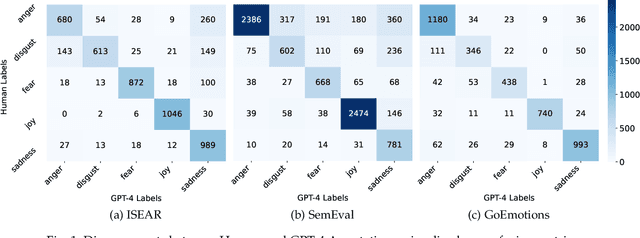
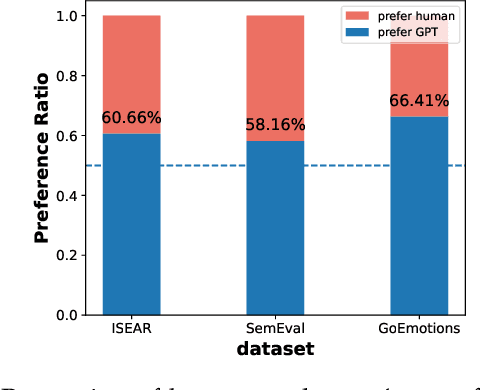
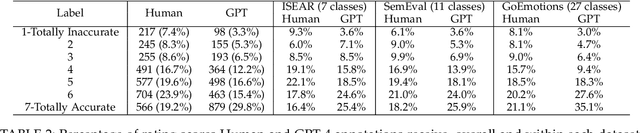
Modern affective computing systems rely heavily on datasets with human-annotated emotion labels, for training and evaluation. However, human annotations are expensive to obtain, sensitive to study design, and difficult to quality control, because of the subjective nature of emotions. Meanwhile, Large Language Models (LLMs) have shown remarkable performance on many Natural Language Understanding tasks, emerging as a promising tool for text annotation. In this work, we analyze the complexities of emotion annotation in the context of LLMs, focusing on GPT-4 as a leading model. In our experiments, GPT-4 achieves high ratings in a human evaluation study, painting a more positive picture than previous work, in which human labels served as the only ground truth. On the other hand, we observe differences between human and GPT-4 emotion perception, underscoring the importance of human input in annotation studies. To harness GPT-4's strength while preserving human perspective, we explore two ways of integrating GPT-4 into emotion annotation pipelines, showing its potential to flag low-quality labels, reduce the workload of human annotators, and improve downstream model learning performance and efficiency. Together, our findings highlight opportunities for new emotion labeling practices and suggest the use of LLMs as a promising tool to aid human annotation.
From Text to Emotion: Unveiling the Emotion Annotation Capabilities of LLMs
Aug 30, 2024
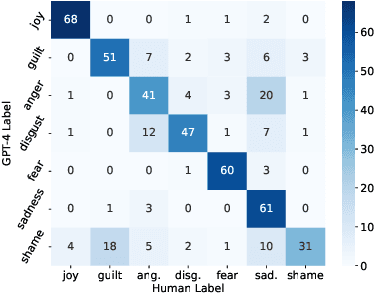
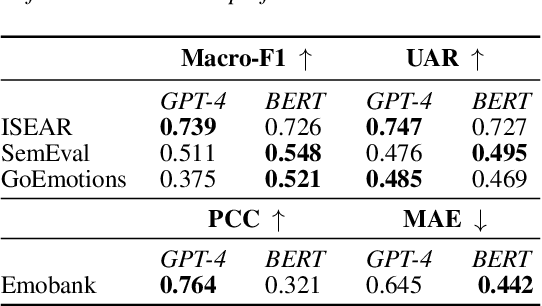
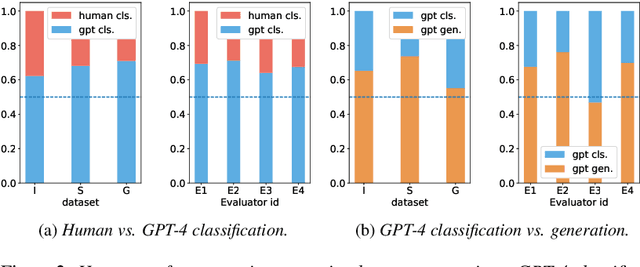
Training emotion recognition models has relied heavily on human annotated data, which present diversity, quality, and cost challenges. In this paper, we explore the potential of Large Language Models (LLMs), specifically GPT4, in automating or assisting emotion annotation. We compare GPT4 with supervised models and or humans in three aspects: agreement with human annotations, alignment with human perception, and impact on model training. We find that common metrics that use aggregated human annotations as ground truth can underestimate the performance, of GPT-4 and our human evaluation experiment reveals a consistent preference for GPT-4 annotations over humans across multiple datasets and evaluators. Further, we investigate the impact of using GPT-4 as an annotation filtering process to improve model training. Together, our findings highlight the great potential of LLMs in emotion annotation tasks and underscore the need for refined evaluation methodologies.
Why Antiwork: A RoBERTa-Based System for Work-Related Stress Identification and Leading Factor Analysis
Aug 24, 2024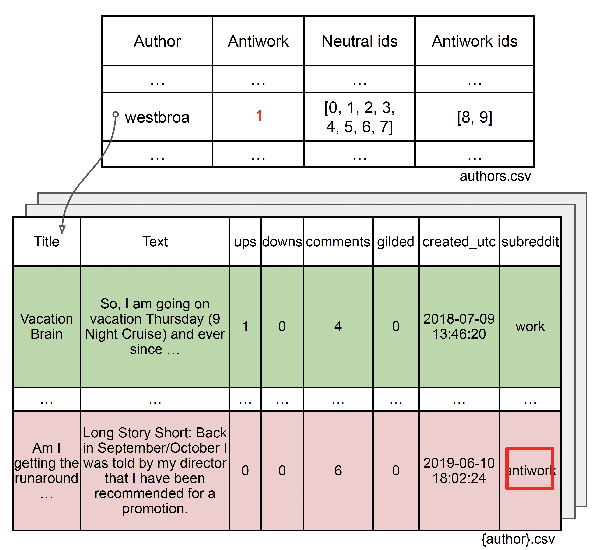

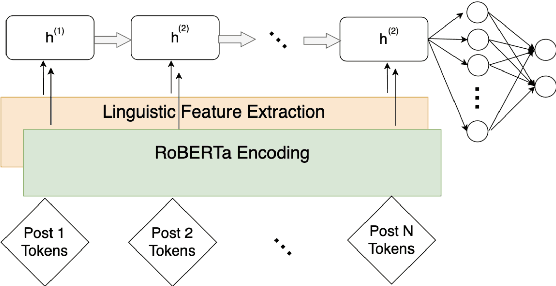

Harsh working environments and work-related stress have been known to contribute to mental health problems such as anxiety, depression, and suicidal ideation. As such, it is paramount to create solutions that can both detect employee unhappiness and find the root cause of the problem. While prior works have examined causes of mental health using machine learning, they typically focus on general mental health analysis, with few of them focusing on explainable solutions or looking at the workplace-specific setting. r/antiwork is a subreddit for the antiwork movement, which is the desire to stop working altogether. Using this subreddit as a proxy for work environment dissatisfaction, we create a new dataset for antiwork sentiment detection and subsequently train a model that highlights the words with antiwork sentiments. Following this, we performed a qualitative and quantitative analysis to uncover some of the key insights into the mindset of individuals who identify with the antiwork movement and how their working environments influenced them. We find that working environments that do not give employees authority or responsibility, frustrating recruiting experiences, and unfair compensation, are some of the leading causes of the antiwork sentiment, resulting in a lack of self-confidence and motivation among their employees.
The Whole Is Bigger Than the Sum of Its Parts: Modeling Individual Annotators to Capture Emotional Variability
Aug 21, 2024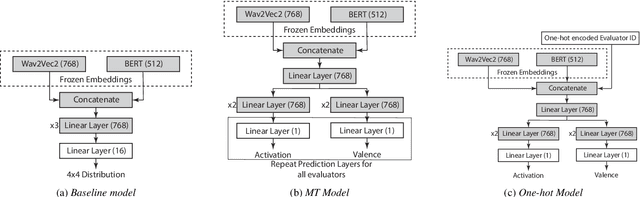

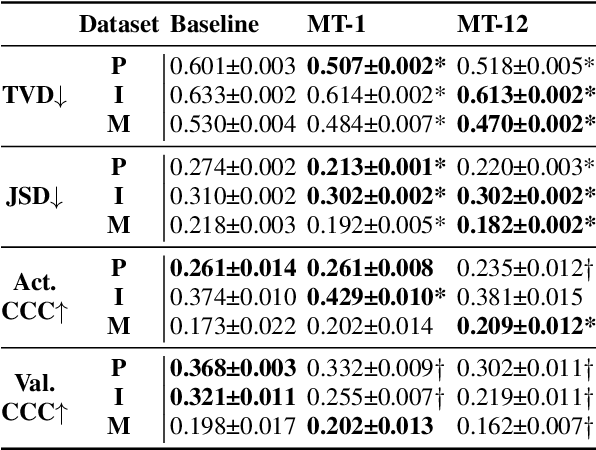
Emotion expression and perception are nuanced, complex, and highly subjective processes. When multiple annotators label emotional data, the resulting labels contain high variability. Most speech emotion recognition tasks address this by averaging annotator labels as ground truth. However, this process omits the nuance of emotion and inter-annotator variability, which are important signals to capture. Previous work has attempted to learn distributions to capture emotion variability, but these methods also lose information about the individual annotators. We address these limitations by learning to predict individual annotators and by introducing a novel method to create distributions from continuous model outputs that permit the learning of emotion distributions during model training. We show that this combined approach can result in emotion distributions that are more accurate than those seen in prior work, in both within- and cross-corpus settings.
Beyond Binary: Multiclass Paraphasia Detection with Generative Pretrained Transformers and End-to-End Models
Jul 16, 2024
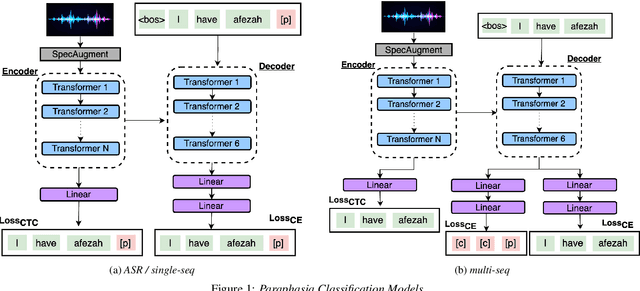
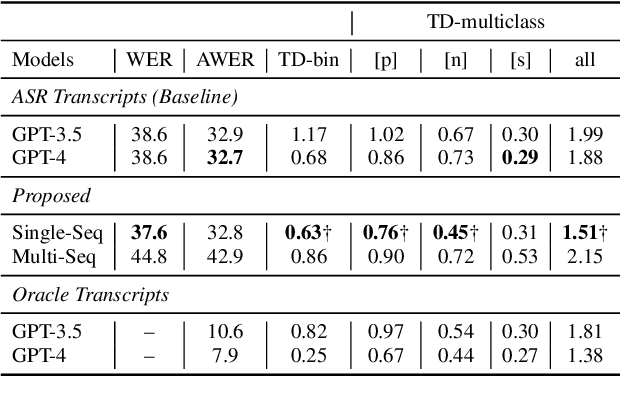
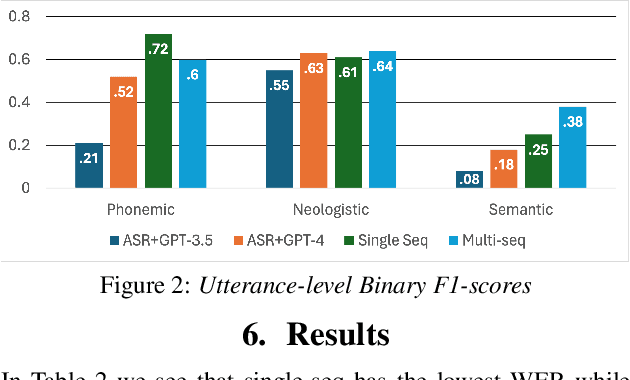
Aphasia is a language disorder that can lead to speech errors known as paraphasias, which involve the misuse, substitution, or invention of words. Automatic paraphasia detection can help those with Aphasia by facilitating clinical assessment and treatment planning options. However, most automatic paraphasia detection works have focused solely on binary detection, which involves recognizing only the presence or absence of a paraphasia. Multiclass paraphasia detection represents an unexplored area of research that focuses on identifying multiple types of paraphasias and where they occur in a given speech segment. We present novel approaches that use a generative pretrained transformer (GPT) to identify paraphasias from transcripts as well as two end-to-end approaches that focus on modeling both automatic speech recognition (ASR) and paraphasia classification as multiple sequences vs. a single sequence. We demonstrate that a single sequence model outperforms GPT baselines for multiclass paraphasia detection.
Seq2seq for Automatic Paraphasia Detection in Aphasic Speech
Dec 16, 2023Paraphasias are speech errors that are often characteristic of aphasia and they represent an important signal in assessing disease severity and subtype. Traditionally, clinicians manually identify paraphasias by transcribing and analyzing speech-language samples, which can be a time-consuming and burdensome process. Identifying paraphasias automatically can greatly help clinicians with the transcription process and ultimately facilitate more efficient and consistent aphasia assessment. Previous research has demonstrated the feasibility of automatic paraphasia detection by training an automatic speech recognition (ASR) model to extract transcripts and then training a separate paraphasia detection model on a set of hand-engineered features. In this paper, we propose a novel, sequence-to-sequence (seq2seq) model that is trained end-to-end (E2E) to perform both ASR and paraphasia detection tasks. We show that the proposed model outperforms the previous state-of-the-art approach for both word-level and utterance-level paraphasia detection tasks and provide additional follow-up evaluations to further understand the proposed model behavior.
Automatic Disfluency Detection from Untranscribed Speech
Nov 01, 2023
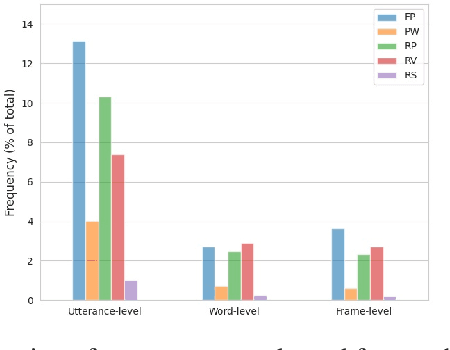
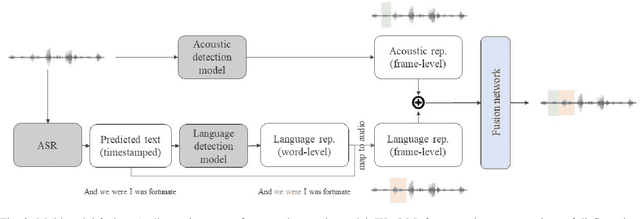
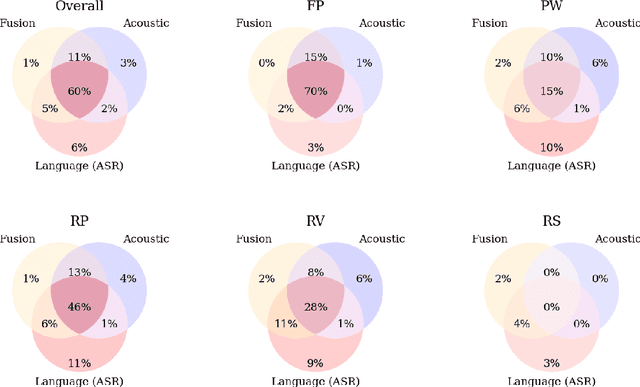
Speech disfluencies, such as filled pauses or repetitions, are disruptions in the typical flow of speech. Stuttering is a speech disorder characterized by a high rate of disfluencies, but all individuals speak with some disfluencies and the rates of disfluencies may by increased by factors such as cognitive load. Clinically, automatic disfluency detection may help in treatment planning for individuals who stutter. Outside of the clinic, automatic disfluency detection may serve as a pre-processing step to improve natural language understanding in downstream applications. With this wide range of applications in mind, we investigate language, acoustic, and multimodal methods for frame-level automatic disfluency detection and categorization. Each of these methods relies on audio as an input. First, we evaluate several automatic speech recognition (ASR) systems in terms of their ability to transcribe disfluencies, measured using disfluency error rates. We then use these ASR transcripts as input to a language-based disfluency detection model. We find that disfluency detection performance is largely limited by the quality of transcripts and alignments. We find that an acoustic-based approach that does not require transcription as an intermediate step outperforms the ASR language approach. Finally, we present multimodal architectures which we find improve disfluency detection performance over the unimodal approaches. Ultimately, this work introduces novel approaches for automatic frame-level disfluency and categorization. In the long term, this will help researchers incorporate automatic disfluency detection into a range of applications.