 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Text to Emotion: Unveiling the Emotion Annotation Capabilities of LLMs
Aug 30, 2024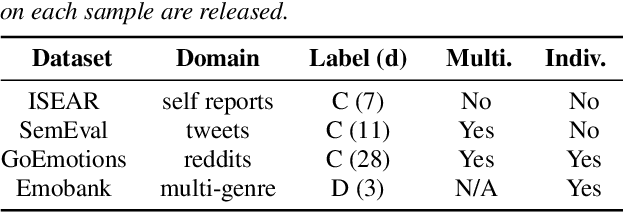
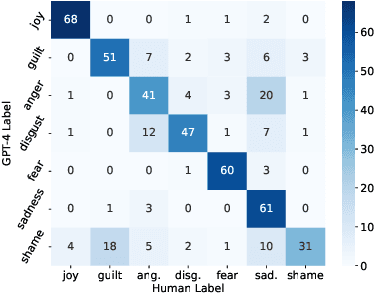
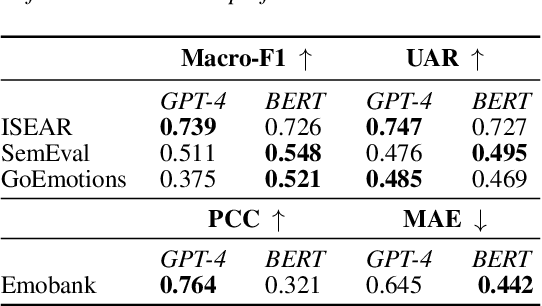
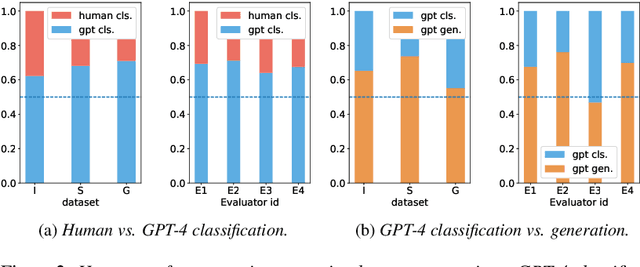
Training emotion recognition models has relied heavily on human annotated data, which present diversity, quality, and cost challenges. In this paper, we explore the potential of Large Language Models (LLMs), specifically GPT4, in automating or assisting emotion annotation. We compare GPT4 with supervised models and or humans in three aspects: agreement with human annotations, alignment with human perception, and impact on model training. We find that common metrics that use aggregated human annotations as ground truth can underestimate the performance, of GPT-4 and our human evaluation experiment reveals a consistent preference for GPT-4 annotations over humans across multiple datasets and evaluators. Further, we investigate the impact of using GPT-4 as an annotation filtering process to improve model training. Together, our findings highlight the great potential of LLMs in emotion annotation tasks and underscore the need for refined evaluation methodologies.
Lessons from the Trenches on Reproducible Evaluation of Language Models
May 23, 2024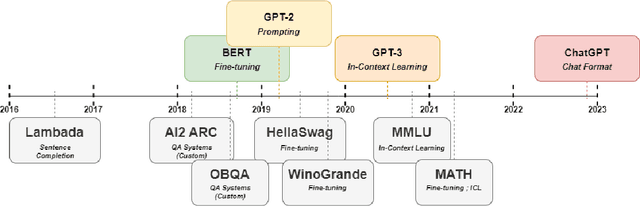
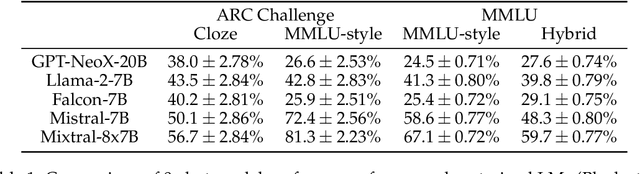
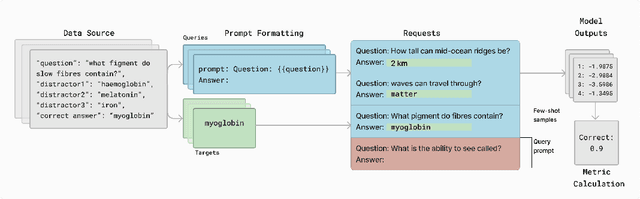

Effective evaluation of language models remains an open challenge in NLP. Researchers and engineers face methodological issues such as the sensitivity of models to evaluation setup, difficulty of proper comparisons across methods, and the lack of reproducibility and transparency. In this paper we draw on three years of experience in evaluating large language models to provide guidance and lessons for researchers. First, we provide an overview of common challenges faced in language model evaluation. Second, we delineate best practices for addressing or lessening the impact of these challenges on research. Third, we present the Language Model Evaluation Harness (lm-eval): an open source library for independent, reproducible, and extensible evaluation of language models that seeks to address these issues. We describe the features of the library as well as case studies in which the library has been used to alleviate these methodological concerns.
Implicit Design Choices and Their Impact on Emotion Recognition Model Development and Evaluation
Sep 06, 2023Emotion recognition is a complex task due to the inherent subjectivity in both the perception and production of emotions. The subjectivity of emotions poses significant challenges in developing accurate and robust computational models. This thesis examines critical facets of emotion recognition, beginning with the collection of diverse datasets that account for psychological factors in emotion production. To handle the challenge of non-representative training data, this work collects the Multimodal Stressed Emotion dataset, which introduces controlled stressors during data collection to better represent real-world influences on emotion production. To address issues with label subjectivity, this research comprehensively analyzes how data augmentation techniques and annotation schemes impact emotion perception and annotator labels. It further handles natural confounding variables and variations by employing adversarial networks to isolate key factors like stress from learned emotion representations during model training. For tackling concerns about leakage of sensitive demographic variables, this work leverages adversarial learning to strip sensitive demographic information from multimodal encodings. Additionally, it proposes optimized sociological evaluation metrics aligned with cost-effective, real-world needs for model testing. This research advances robust, practical emotion recognition through multifaceted studies of challenges in datasets, labels, modeling, demographic and membership variable encoding in representations, and evaluation. The groundwork has been laid for cost-effective, generalizable emotion recognition models that are less likely to encode sensitive demographic information.
Best Practices for Noise-Based Augmentation to Improve the Performance of Emotion Recognition "In the Wild"
Apr 18, 2021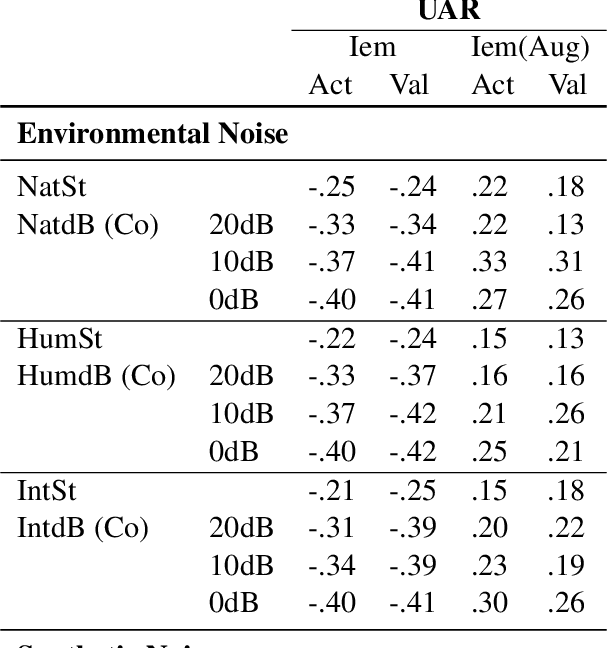

Emotion recognition as a key component of high-stake downstream applications has been shown to be effective, such as classroom engagement or mental health assessments. These systems are generally trained on small datasets collected in single laboratory environments, and hence falter when tested on data that has different noise characteristics. Multiple noise-based data augmentation approaches have been proposed to counteract this challenge in other speech domains. But, unlike speech recognition and speaker verification, in emotion recognition, noise-based data augmentation may change the underlying label of the original emotional sample. In this work, we generate realistic noisy samples of a well known emotion dataset (IEMOCAP) using multiple categories of environmental and synthetic noise. We evaluate how both human and machine emotion perception changes when noise is introduced. We find that some commonly used augmentation techniques for emotion recognition significantly change human perception, which may lead to unreliable evaluation metrics such as evaluating efficiency of adversarial attack. We also find that the trained state-of-the-art emotion recognition models fail to classify unseen noise-augmented samples, even when trained on noise augmented datasets. This finding demonstrates the brittleness of these systems in real-world conditions. We propose a set of recommendations for noise-based augmentation of emotion datasets and for how to deploy these emotion recognition systems "in the wild".
Why Should I Trust a Model is Private? Using Shifts in Model Explanation for Evaluating Privacy-Preserving Emotion Recognition Model
Apr 18, 2021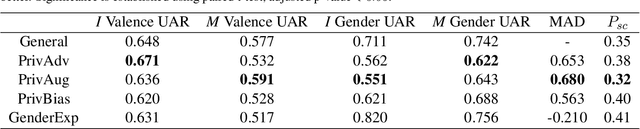
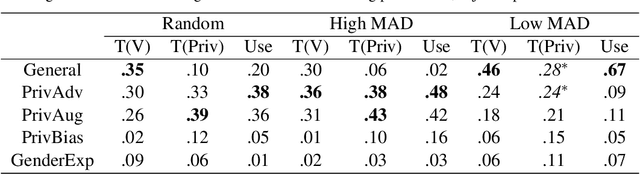
Privacy preservation is a crucial component of any real-world application. Yet, in applications relying on machine learning backends, this is challenging because models often capture more than a designer may have envisioned, resulting in the potential leakage of sensitive information. For example, emotion recognition models are susceptible to learning patterns between the target variable and other sensitive variables, patterns that can be maliciously re-purposed to obtain protected information. In this paper, we concentrate on using interpretable methods to evaluate a model's efficacy to preserve privacy with respect to sensitive variables. We focus on saliency-based explanations, explanations that highlight regions of the input text, which allows us to understand how model explanations shift when models are trained to preserve privacy. We show how certain commonly-used methods that seek to preserve privacy might not align with human perception of privacy preservation. We also show how some of these induce spurious correlations in the model between the input and the primary as well as secondary task, even if the improvement in evaluation metric is significant. Such correlations can hence lead to false assurances about the perceived privacy of the model because especially when used in cross corpus conditions. We conduct crowdsourcing experiments to evaluate the inclination of the evaluators to choose a particular model for a given task when model explanations are provided, and find that correlation of interpretation differences with sociolinguistic biases can be used as a proxy for user trust.
Privacy Enhanced Multimodal Neural Representations for Emotion Recognition
Oct 29, 2019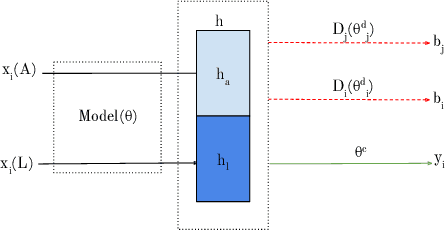
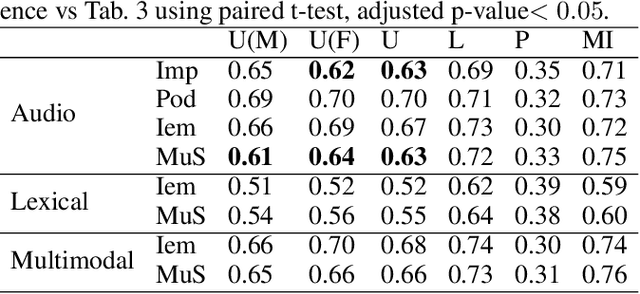
Many mobile applications and virtual conversational agents now aim to recognize and adapt to emotions. To enable this, data are transmitted from users' devices and stored on central servers. Yet, these data contain sensitive information that could be used by mobile applications without user's consent or, maliciously, by an eavesdropping adversary. In this work, we show how multimodal representations trained for a primary task, here emotion recognition, can unintentionally leak demographic information, which could override a selected opt-out option by the user. We analyze how this leakage differs in representations obtained from textual, acoustic, and multimodal data. We use an adversarial learning paradigm to unlearn the private information present in a representation and investigate the effect of varying the strength of the adversarial component on the primary task and on the privacy metric, defined here as the inability of an attacker to predict specific demographic information. We evaluate this paradigm on multiple datasets and show that we can improve the privacy metric while not significantly impacting the performance on the primary task. To the best of our knowledge, this is the first work to analyze how the privacy metric differs across modalities and how multiple privacy concerns can be tackled while still maintaining performance on emotion recognition.
Controlling for Confounders in Multimodal Emotion Classification via Adversarial Learning
Aug 23, 2019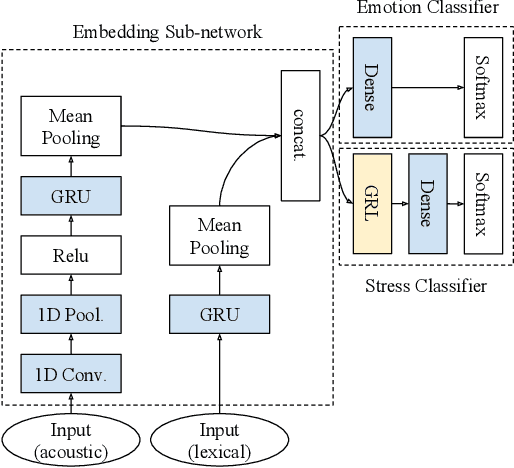

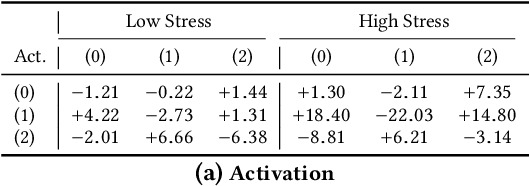
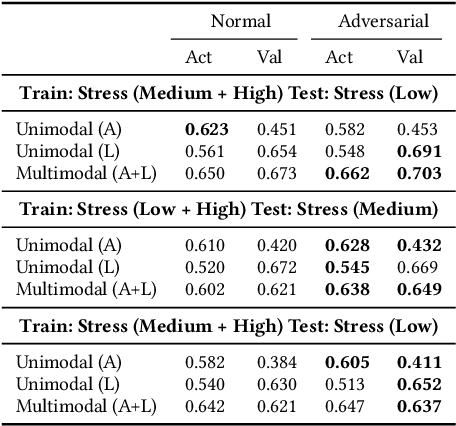
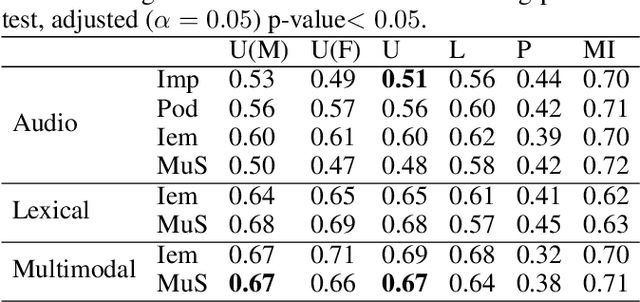
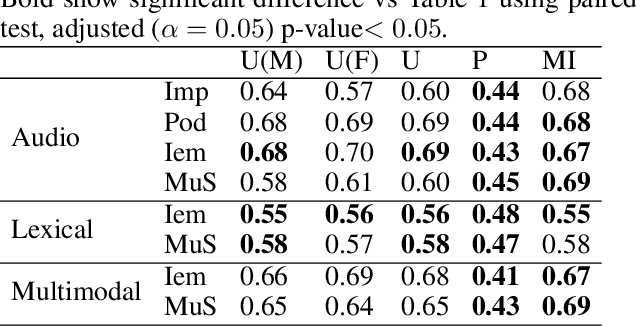
Various psychological factors affect how individuals express emotions. Yet, when we collect data intended for use in building emotion recognition systems, we often try to do so by creating paradigms that are designed just with a focus on eliciting emotional behavior. Algorithms trained with these types of data are unlikely to function outside of controlled environments because our emotions naturally change as a function of these other factors. In this work, we study how the multimodal expressions of emotion change when an individual is under varying levels of stress. We hypothesize that stress produces modulations that can hide the true underlying emotions of individuals and that we can make emotion recognition algorithms more generalizable by controlling for variations in stress. To this end, we use adversarial networks to decorrelate stress modulations from emotion representations. We study how stress alters acoustic and lexical emotional predictions, paying special attention to how modulations due to stress affect the transferability of learned emotion recognition models across domains. Our results show that stress is indeed encoded in trained emotion classifiers and that this encoding varies across levels of emotions and across the lexical and acoustic modalities. Our results also show that emotion recognition models that control for stress during training have better generalizability when applied to new domains, compared to models that do not control for stress during training. We conclude that is is necessary to consider the effect of extraneous psychological factors when building and testing emotion recognition models.
MuSE-ing on the Impact of Utterance Ordering On Crowdsourced Emotion Annotations
Mar 27, 2019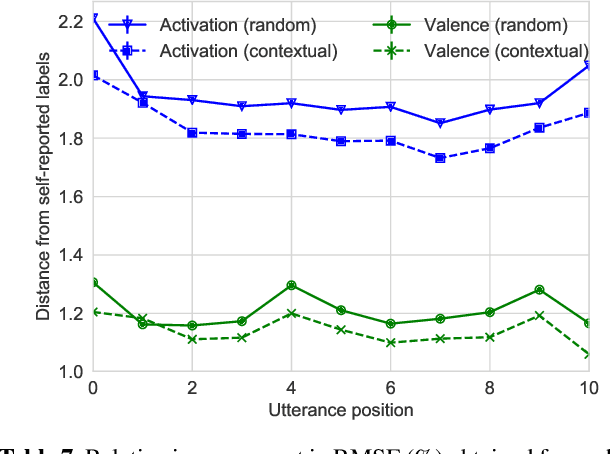
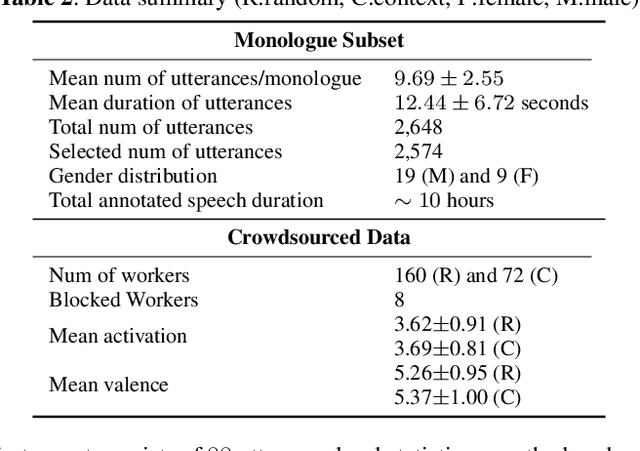

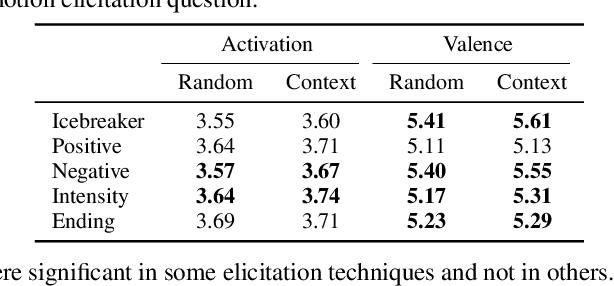
Emotion recognition algorithms rely on data annotated with high quality labels. However, emotion expression and perception are inherently subjective. There is generally not a single annotation that can be unambiguously declared "correct". As a result, annotations are colored by the manner in which they were collected. In this paper, we conduct crowdsourcing experiments to investigate this impact on both the annotations themselves and on the performance of these algorithms. We focus on one critical question: the effect of context. We present a new emotion dataset, Multimodal Stressed Emotion (MuSE), and annotate the dataset using two conditions: randomized, in which annotators are presented with clips in random order, and contextualized, in which annotators are presented with clips in order. We find that contextual labeling schemes result in annotations that are more similar to a speaker's own self-reported labels and that labels generated from randomized schemes are most easily predictable by automated systems.
"Hang in There": Lexical and Visual Analysis to Identify Posts Warranting Empathetic Responses
Mar 12, 2019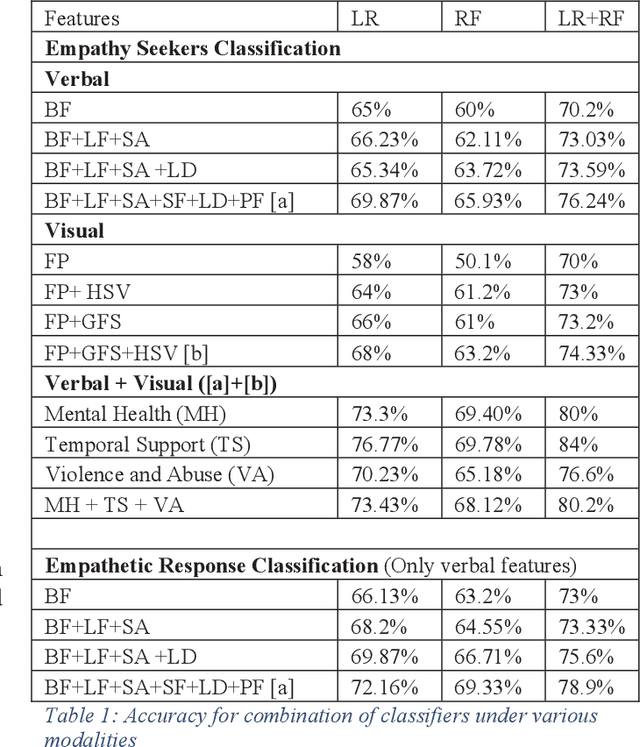
In the past few years, social media has risen as a platform where people express and share personal incidences about abuse, violence and mental health issues. There is a need to pinpoint such posts and learn the kind of response expected. For this purpose, we understand the sentiment that a personal story elicits on different posts present on different social media sites, on the topics of abuse or mental health. In this paper, we propose a method supported by hand-crafted features to judge if the post requires an empathetic response. The model is trained upon posts from various web-pages and corresponding comments, on both the captions and the images. We were able to obtain 80% accuracy in tagging posts requiring empathetic responses.
The Truth and Nothing but the Truth: Multimodal Analysis for Deception Detection
Mar 11, 2019
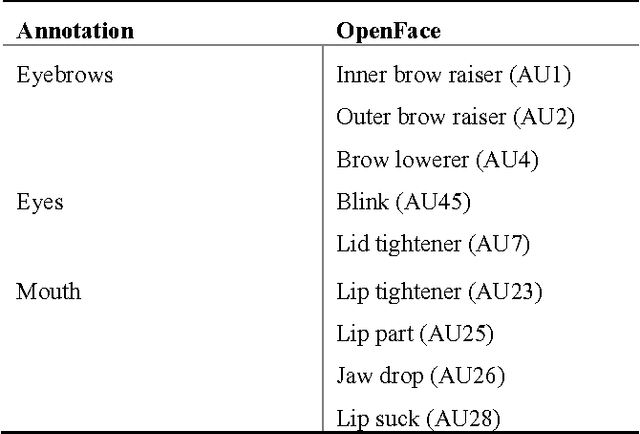
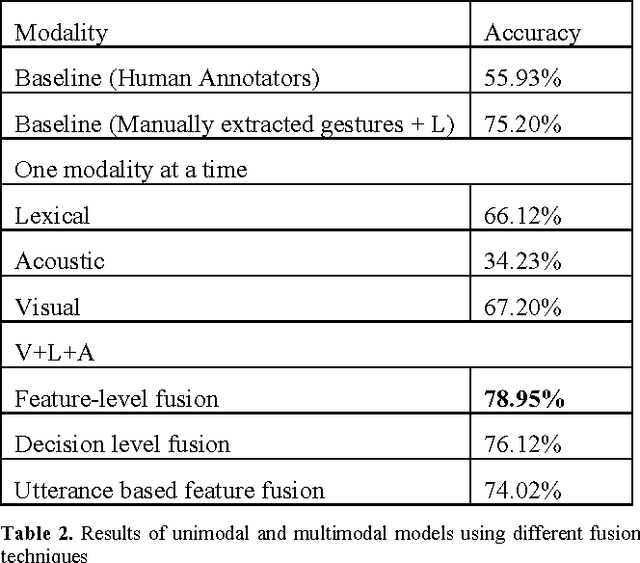
We propose a data-driven method for automatic deception detection in real-life trial data using visual and verbal cues. Using OpenFace with facial action unit recognition, we analyze the movement of facial features of the witness when posed with questions and the acoustic patterns using OpenSmile. We then perform a lexical analysis on the spoken words, emphasizing the use of pauses and utterance breaks, feeding that to a Support Vector Machine to test deceit or truth prediction. We then try out a method to incorporate utterance-based fusion of visual and lexical analysis, using string based matching.