 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowSteer: Interactive Agentic Workflow Orchestration via End-to-End Reinforcement Learning
Feb 02, 2026In recent years, a variety of powerful agentic workflows have been applied to solve a wide range of human problems. However, existing workflow orchestration still faces key challenges, including high manual cost, reliance on specific operators/large language models (LLMs), and sparse reward signals. To address these challenges, we propose FlowSteer, an end-to-end reinforcement learning framework that takes a lightweight policy model as the agent and an executable canvas environment, automating workflow orchestration through multi-turn interaction. In this process, the policy model analyzes execution states and selects editing actions, while the canvas executes operators and returns feedback for iterative refinement. Moreover, FlowSteer provides a plug-and-play framework that supports diverse operator libraries and interchangeable LLM backends. To effectively train this interaction paradigm, we propose Canvas Workflow Relative Policy Optimization (CWRPO), which introduces diversity-constrained rewards with conditional release to stabilize learning and suppress shortcut behaviors. Experimental results on twelve datasets show that FlowSteer significantly outperforms baselines across various tasks.
Enhancing Language Models for Robust Greenwashing Detection
Jan 29, 2026Sustainability reports are critical for ESG assessment, yet greenwashing and vague claims often undermine their reliability. Existing NLP models lack robustness to these practices, typically relying on surface-level patterns that generalize poorly. We propose a parameter-efficient framework that structures LLM latent spaces by combining contrastive learning with an ordinal ranking objective to capture graded distinctions between concrete actions and ambiguous claims. Our approach incorporates gated feature modulation to filter disclosure noise and utilizes MetaGradNorm to stabilize multi-objective optimization. Experiments in cross-category settings demonstrate superior robustness over standard baselines while revealing a trade-off between representational rigidity and generalization.
LLMdoctor: Token-Level Flow-Guided Preference Optimization for Efficient Test-Time Alignment of Large Language Models
Jan 15, 2026Aligning Large Language Models (LLMs) with human preferences is critical, yet traditional fine-tuning methods are computationally expensive and inflexible. While test-time alignment offers a promising alternative, existing approaches often rely on distorted trajectory-level signals or inefficient sampling, fundamentally capping performance and failing to preserve the generative diversity of the base model. This paper introduces LLMdoctor, a novel framework for efficient test-time alignment that operates via a patient-doctor paradigm. It integrates token-level reward acquisition with token-level flow-guided preference optimization (TFPO) to steer a large, frozen patient LLM with a smaller, specialized doctor model. Unlike conventional methods that rely on trajectory-level rewards, LLMdoctor first extracts fine-grained, token-level preference signals from the patient model's behavioral variations. These signals then guide the training of the doctor model via TFPO, which establishes flow consistency across all subtrajectories, enabling precise token-by-token alignment while inherently preserving generation diversity. Extensive experiments demonstrate that LLMdoctor significantly outperforms existing test-time alignment methods and even surpasses the performance of full fine-tuning approaches like DPO.
A Systematic Analysis of Biases in Large Language Models
Dec 16, 2025



Large language models (LLMs) have rapidly become indispensable tools for acquiring information and supporting human decision-making. However, ensuring that these models uphold fairness across varied contexts is critical to their safe and responsible deployment. In this study, we undertake a comprehensive examination of four widely adopted LLMs, probing their underlying biases and inclinations across the dimensions of politics, ideology, alliance, language, and gender. Through a series of carefully designed experiments, we investigate their political neutrality using news summarization, ideological biases through news stance classification, tendencies toward specific geopolitical alliances via United Nations voting patterns, language bias in the context of multilingual story completion, and gender-related affinities as revealed by responses to the World Values Survey. Results indicate that while the LLMs are aligned to be neutral and impartial, they still show biases and affinities of different types.
Human Behavior Atlas: Benchmarking Unified Psychological and Social Behavior Understanding
Oct 06, 2025Using intelligent systems to perceive psychological and social behaviors, that is, the underlying affective, cognitive, and pathological states that are manifested through observable behaviors and social interactions, remains a challenge due to their complex, multifaceted, and personalized nature. Existing work tackling these dimensions through specialized datasets and single-task systems often miss opportunities for scalability, cross-task transfer, and broader generalization. To address this gap, we curate Human Behavior Atlas, a unified benchmark of diverse behavioral tasks designed to support the development of unified models for understanding psychological and social behaviors. Human Behavior Atlas comprises over 100,000 samples spanning text, audio, and visual modalities, covering tasks on affective states, cognitive states, pathologies, and social processes. Our unification efforts can reduce redundancy and cost, enable training to scale efficiently across tasks, and enhance generalization of behavioral features across domains. On Human Behavior Atlas, we train three models: OmniSapiens-7B SFT, OmniSapiens-7B BAM, and OmniSapiens-7B RL. We show that training on Human Behavior Atlas enables models to consistently outperform existing multimodal LLMs across diverse behavioral tasks. Pretraining on Human Behavior Atlas also improves transfer to novel behavioral datasets; with the targeted use of behavioral descriptors yielding meaningful performance gains.
Mind Meets Space: Rethinking Agentic Spatial Intelligence from a Neuroscience-inspired Perspective
Sep 11, 2025Recent advances in agentic AI have led to systems capable of autonomous task execution and language-based reasoning, yet their spatial reasoning abilities remain limited and underexplored, largely constrained to symbolic and sequential processing. In contrast, human spatial intelligence, rooted in integrated multisensory perception, spatial memory, and cognitive maps, enables flexible, context-aware decision-making in unstructured environments. Therefore, bridging this gap is critical for advancing Agentic Spatial Intelligence toward better interaction with the physical 3D world. To this end, we first start from scrutinizing the spatial neural models as studied in computational neuroscience, and accordingly introduce a novel computational framework grounded in neuroscience principles. This framework maps core biological functions to six essential computation modules: bio-inspired multimodal sensing, multi-sensory integration, egocentric-allocentric conversion, an artificial cognitive map, spatial memory, and spatial reasoning. Together, these modules form a perspective landscape for agentic spatial reasoning capability across both virtual and physical environments. On top, we conduct a framework-guided analysis of recent methods, evaluating their relevance to each module and identifying critical gaps that hinder the development of more neuroscience-grounded spatial reasoning modules. We further examine emerging benchmarks and datasets and explore potential application domains ranging from virtual to embodied systems, such as robotics. Finally, we outline potential research directions, emphasizing the promising roadmap that can generalize spatial reasoning across dynamic or unstructured environments. We hope this work will benefit the research community with a neuroscience-grounded perspective and a structured pathway. Our project page can be found at Github.
Bridging Minds and Machines: Toward an Integration of AI and Cognitive Science
Aug 28, 2025Cognitive Science has profoundly shaped disciplines such as Artificial Intelligence (AI), Philosophy, Psychology, Neuroscience, Linguistics, and Culture. Many breakthroughs in AI trace their roots to cognitive theories, while AI itself has become an indispensable tool for advancing cognitive research. This reciprocal relationship motivates a comprehensive review of the intersections between AI and Cognitive Science. By synthesizing key contributions from both perspectives, we observe that AI progress has largely emphasized practical task performance, whereas its cognitive foundations remain conceptually fragmented. We argue that the future of AI within Cognitive Science lies not only in improving performance but also in constructing systems that deepen our understanding of the human mind. Promising directions include aligning AI behaviors with cognitive frameworks, situating AI in embodiment and culture, developing personalized cognitive models, and rethinking AI ethics through cognitive co-evaluation.
SEA-BED: Southeast Asia Embedding Benchmark
Aug 17, 2025
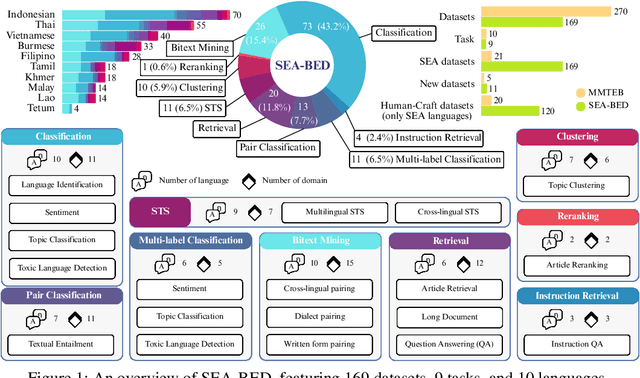


Sentence embeddings are essential for NLP tasks such as semantic search, re-ranking, and textual similarity. Although multilingual benchmarks like MMTEB broaden coverage, Southeast Asia (SEA) datasets are scarce and often machine-translated, missing native linguistic properties. With nearly 700 million speakers, the SEA region lacks a region-specific embedding benchmark. We introduce SEA-BED, the first large-scale SEA embedding benchmark with 169 datasets across 9 tasks and 10 languages, where 71% are formulated by humans, not machine generation or translation. We address three research questions: (1) which SEA languages and tasks are challenging, (2) whether SEA languages show unique performance gaps globally, and (3) how human vs. machine translations affect evaluation. We evaluate 17 embedding models across six studies, analyzing task and language challenges, cross-benchmark comparisons, and translation trade-offs. Results show sharp ranking shifts, inconsistent model performance among SEA languages, and the importance of human-curated datasets for low-resource languages like Burmese.
Understanding Refusal in Language Models with Sparse Autoencoders
May 29, 2025Refusal is a key safety behavior in aligned language models, yet the internal mechanisms driving refusals remain opaque. In this work, we conduct a mechanistic study of refusal in instruction-tuned LLMs using sparse autoencoders to identify latent features that causally mediate refusal behaviors. We apply our method to two open-source chat models and intervene on refusal-related features to assess their influence on generation, validating their behavioral impact across multiple harmful datasets. This enables a fine-grained inspection of how refusal manifests at the activation level and addresses key research questions such as investigating upstream-downstream latent relationship and understanding the mechanisms of adversarial jailbreaking techniques. We also establish the usefulness of refusal features in enhancing generalization for linear probes to out-of-distribution adversarial samples in classification tasks. We open source our code in https://github.com/wj210/refusal_sae.
Deriving Strategic Market Insights with Large Language Models: A Benchmark for Forward Counterfactual Generation
May 26, 2025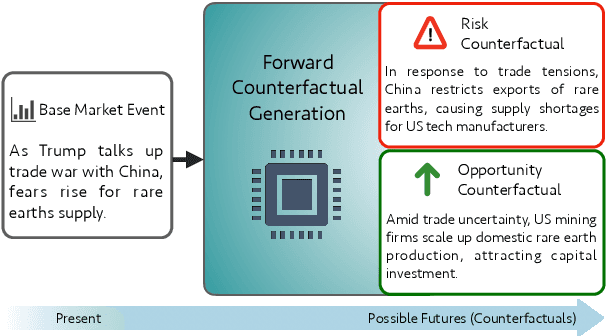
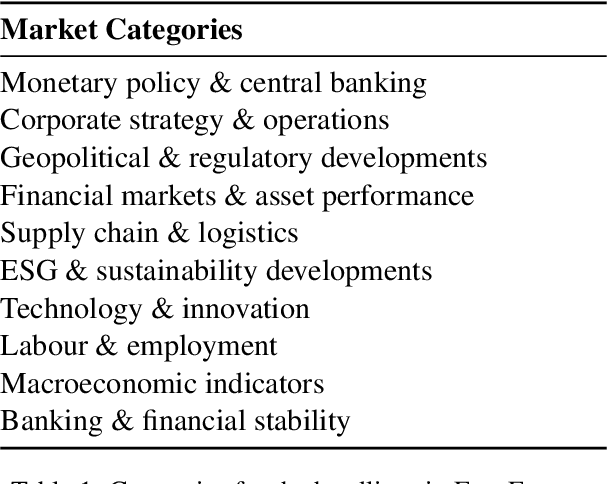
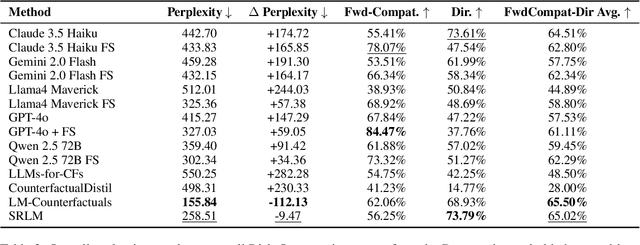
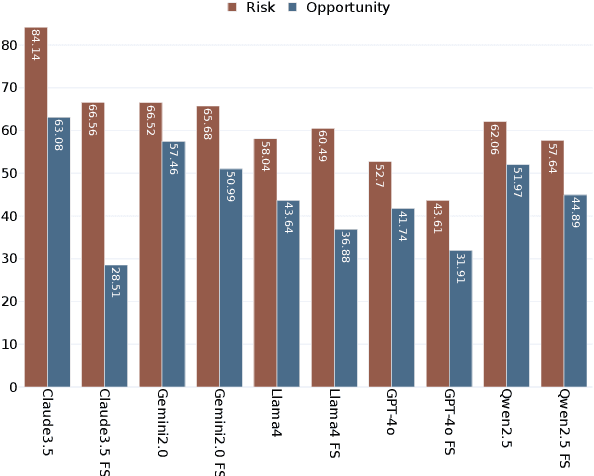
Counterfactual reasoning typically involves considering alternatives to actual events. While often applied to understand past events, a distinct form-forward counterfactual reasoning-focuses on anticipating plausible future developments. This type of reasoning is invaluable in dynamic financial markets, where anticipating market developments can powerfully unveil potential risks and opportunities for stakeholders, guiding their decision-making. However, performing this at scale is challenging due to the cognitive demands involved, underscoring the need for automated solutions. Large Language Models (LLMs) offer promise, but remain unexplored for this application. To address this gap, we introduce a novel benchmark, Fin-Force-FINancial FORward Counterfactual Evaluation. By curating financial news headlines and providing structured evaluation, Fin-Force supports LLM based forward counterfactual generation. This paves the way for scalable and automated solutions for exploring and anticipating future market developments, thereby providing structured insights for decision-making. Through experiments on Fin-Force, we evaluate state-of-the-art LLMs and counterfactual generation methods, analyzing their limitations and proposing insights for future research.