 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe data heat island effect: quantifying the impact of AI data centers in a warming world
Mar 21, 2026The strong and continuous increase of AI-based services leads to the steady proliferation of AI data centres worldwide with the unavoidable escalation of their power consumption. It is unknown how this energy demand for computational purposes will impact the surrounding environment. Here, we focus our attention on the heat dissipation of AI hyperscalers. Taking advantage of land surface temperature measurements acquired by remote sensing platforms over the last decades, we are able to obtain a robust assessment of the temperature increase recorded in the areas surrounding AI data centres globally. We estimate that the land surface temperature increases by 2°C on average after the start of operations of an AI data centre, inducing local microclimate zones, which we call the data heat island effect. We assess the impact on the communities, quantifying that more than 340 million people could be affected by this temperature increase. Our results show that the data heat island effect could have a remarkable influence on communities and regional welfare in the future, hence becoming part of the conversation around environmentally sustainable AI worldwide.
Hierarchy of extreme-event predictability in turbulence revealed by machine learning
Mar 14, 2026Extreme-event predictability in turbulence is strongly state dependent, yet event-by-event predictability horizons are difficult to quantify without access to governing equations or costly perturbation ensembles. Here we train an autoregressive conditional diffusion model on direct numerical simulations of the two-dimensional Kolmogorov flow and use a CRPS-based skill score to define an event-wise predictability horizon. Enstrophy extremes exhibit a pronounced hierarchy: forecast skill persists from $\approx 1$ to $> 4$ Lyapunov times across events. Spectral filtering shows that these horizons are controlled predominantly by large-scale structures. Extremes are preceded by intense strain cores organizing quadrupolar vortex packets, whose lifetime sharply separates long- from short-horizon events. These results identify coherent-structure persistence as a governing mechanism for the predictability of turbulence extremes and provide a data-driven route to diagnose predictability limits from observations.
OmniSapiens: A Foundation Model for Social Behavior Processing via Heterogeneity-Aware Relative Policy Optimization
Feb 11, 2026To develop socially intelligent AI, existing approaches typically model human behavioral dimensions (e.g., affective, cognitive, or social attributes) in isolation. Although useful, task-specific modeling often increases training costs and limits generalization across behavioral settings. Recent reasoning RL methods facilitate training a single unified model across multiple behavioral tasks, but do not explicitly address learning across different heterogeneous behavioral data. To address this gap, we introduce Heterogeneity-Aware Relative Policy Optimization (HARPO), an RL method that balances leaning across heterogeneous tasks and samples. This is achieved by modulating advantages to ensure that no single task or sample carries disproportionate influence during policy optimization. Using HARPO, we develop and release Omnisapiens-7B 2.0, a foundation model for social behavior processing. Relative to existing behavioral foundation models, Omnisapiens-7B 2.0 achieves the strongest performance across behavioral tasks, with gains of up to +16.85% and +9.37% on multitask and held-out settings respectively, while producing more explicit and robust reasoning traces. We also validate HARPO against recent RL methods, where it achieves the most consistently strong performance across behavioral tasks.
Enhancing Language Models for Robust Greenwashing Detection
Jan 29, 2026Sustainability reports are critical for ESG assessment, yet greenwashing and vague claims often undermine their reliability. Existing NLP models lack robustness to these practices, typically relying on surface-level patterns that generalize poorly. We propose a parameter-efficient framework that structures LLM latent spaces by combining contrastive learning with an ordinal ranking objective to capture graded distinctions between concrete actions and ambiguous claims. Our approach incorporates gated feature modulation to filter disclosure noise and utilizes MetaGradNorm to stabilize multi-objective optimization. Experiments in cross-category settings demonstrate superior robustness over standard baselines while revealing a trade-off between representational rigidity and generalization.
eXIAA: eXplainable Injections for Adversarial Attack
Nov 13, 2025Post-hoc explainability methods are a subset of Machine Learning (ML) that aim to provide a reason for why a model behaves in a certain way. In this paper, we show a new black-box model-agnostic adversarial attack for post-hoc explainable Artificial Intelligence (XAI), particularly in the image domain. The goal of the attack is to modify the original explanations while being undetected by the human eye and maintain the same predicted class. In contrast to previous methods, we do not require any access to the model or its weights, but only to the model's computed predictions and explanations. Additionally, the attack is accomplished in a single step while significantly changing the provided explanations, as demonstrated by empirical evaluation. The low requirements of our method expose a critical vulnerability in current explainability methods, raising concerns about their reliability in safety-critical applications. We systematically generate attacks based on the explanations generated by post-hoc explainability methods (saliency maps, integrated gradients, and DeepLIFT SHAP) for pretrained ResNet-18 and ViT-B16 on ImageNet. The results show that our attacks could lead to dramatically different explanations without changing the predictive probabilities. We validate the effectiveness of our attack, compute the induced change based on the explanation with mean absolute difference, and verify the closeness of the original image and the corrupted one with the Structural Similarity Index Measure (SSIM).
Human Behavior Atlas: Benchmarking Unified Psychological and Social Behavior Understanding
Oct 06, 2025Using intelligent systems to perceive psychological and social behaviors, that is, the underlying affective, cognitive, and pathological states that are manifested through observable behaviors and social interactions, remains a challenge due to their complex, multifaceted, and personalized nature. Existing work tackling these dimensions through specialized datasets and single-task systems often miss opportunities for scalability, cross-task transfer, and broader generalization. To address this gap, we curate Human Behavior Atlas, a unified benchmark of diverse behavioral tasks designed to support the development of unified models for understanding psychological and social behaviors. Human Behavior Atlas comprises over 100,000 samples spanning text, audio, and visual modalities, covering tasks on affective states, cognitive states, pathologies, and social processes. Our unification efforts can reduce redundancy and cost, enable training to scale efficiently across tasks, and enhance generalization of behavioral features across domains. On Human Behavior Atlas, we train three models: OmniSapiens-7B SFT, OmniSapiens-7B BAM, and OmniSapiens-7B RL. We show that training on Human Behavior Atlas enables models to consistently outperform existing multimodal LLMs across diverse behavioral tasks. Pretraining on Human Behavior Atlas also improves transfer to novel behavioral datasets; with the targeted use of behavioral descriptors yielding meaningful performance gains.
Deriving Strategic Market Insights with Large Language Models: A Benchmark for Forward Counterfactual Generation
May 26, 2025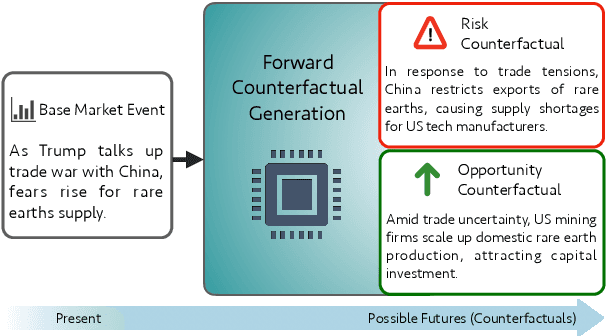
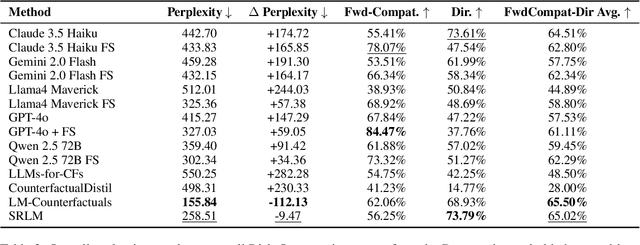
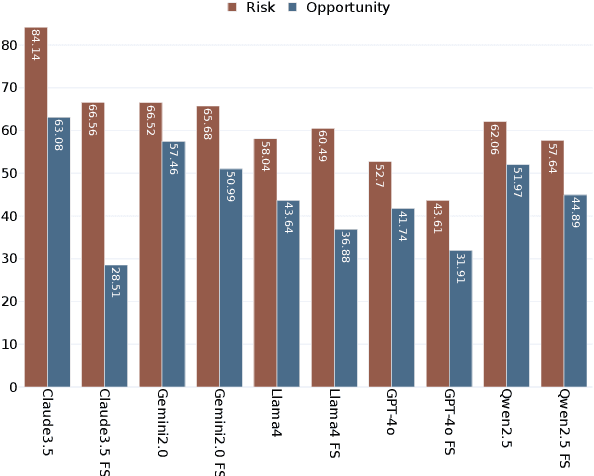
Counterfactual reasoning typically involves considering alternatives to actual events. While often applied to understand past events, a distinct form-forward counterfactual reasoning-focuses on anticipating plausible future developments. This type of reasoning is invaluable in dynamic financial markets, where anticipating market developments can powerfully unveil potential risks and opportunities for stakeholders, guiding their decision-making. However, performing this at scale is challenging due to the cognitive demands involved, underscoring the need for automated solutions. Large Language Models (LLMs) offer promise, but remain unexplored for this application. To address this gap, we introduce a novel benchmark, Fin-Force-FINancial FORward Counterfactual Evaluation. By curating financial news headlines and providing structured evaluation, Fin-Force supports LLM based forward counterfactual generation. This paves the way for scalable and automated solutions for exploring and anticipating future market developments, thereby providing structured insights for decision-making. Through experiments on Fin-Force, we evaluate state-of-the-art LLMs and counterfactual generation methods, analyzing their limitations and proposing insights for future research.
ClimaEmpact: Domain-Aligned Small Language Models and Datasets for Extreme Weather Analytics
Apr 27, 2025Accurate assessments of extreme weather events are vital for research and policy, yet localized and granular data remain scarce in many parts of the world. This data gap limits our ability to analyze potential outcomes and implications of extreme weather events, hindering effective decision-making. Large Language Models (LLMs) can process vast amounts of unstructured text data, extract meaningful insights, and generate detailed assessments by synthesizing information from multiple sources. Furthermore, LLMs can seamlessly transfer their general language understanding to smaller models, enabling these models to retain key knowledge while being fine-tuned for specific tasks. In this paper, we propose Extreme Weather Reasoning-Aware Alignment (EWRA), a method that enhances small language models (SLMs) by incorporating structured reasoning paths derived from LLMs, and ExtremeWeatherNews, a large dataset of extreme weather event-related news articles. EWRA and ExtremeWeatherNews together form the overall framework, ClimaEmpact, that focuses on addressing three critical extreme-weather tasks: categorization of tangible vulnerabilities/impacts, topic labeling, and emotion analysis. By aligning SLMs with advanced reasoning strategies on ExtremeWeatherNews (and its derived dataset ExtremeAlign used specifically for SLM alignment), EWRA improves the SLMs' ability to generate well-grounded and domain-specific responses for extreme weather analytics. Our results show that the approach proposed guides SLMs to output domain-aligned responses, surpassing the performance of task-specific models and offering enhanced real-world applicability for extreme weather analytics.
Dynamical errors in machine learning forecasts
Apr 16, 2025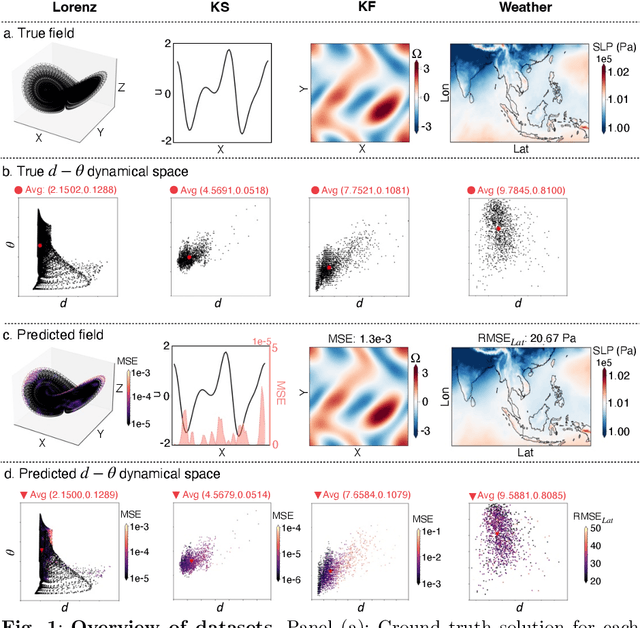
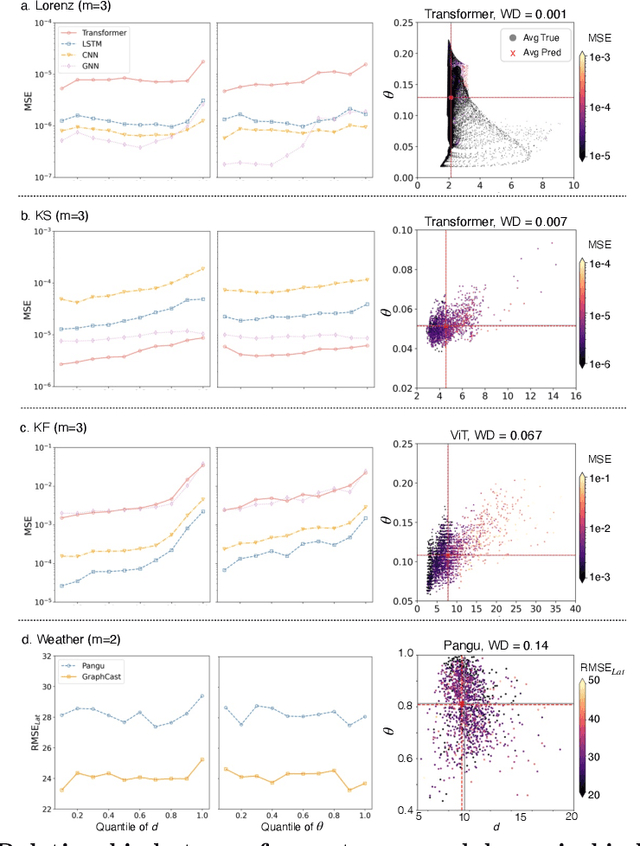
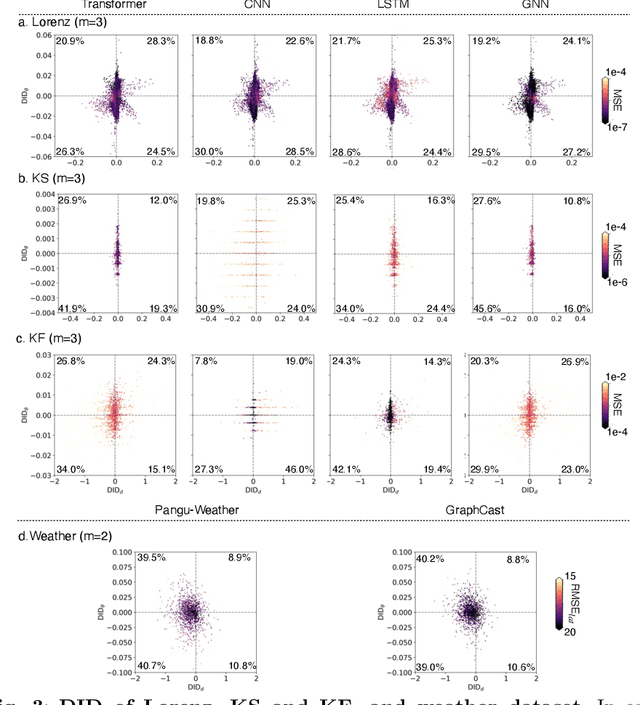
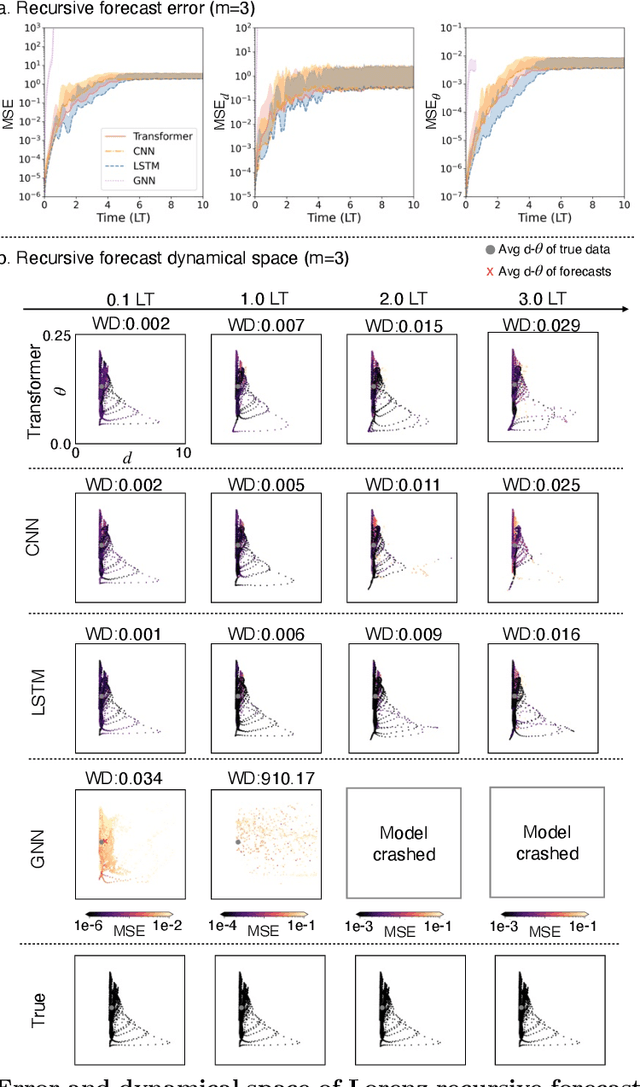
In machine learning forecasting, standard error metrics such as mean absolute error (MAE) and mean squared error (MSE) quantify discrepancies between predictions and target values. However, these metrics do not directly evaluate the physical and/or dynamical consistency of forecasts, an increasingly critical concern in scientific and engineering applications. Indeed, a fundamental yet often overlooked question is whether machine learning forecasts preserve the dynamical behavior of the underlying system. Addressing this issue is essential for assessing the fidelity of machine learning models and identifying potential failure modes, particularly in applications where maintaining correct dynamical behavior is crucial. In this work, we investigate the relationship between standard forecasting error metrics, such as MAE and MSE, and the dynamical properties of the underlying system. To achieve this goal, we use two recently developed dynamical indices: the instantaneous dimension ($d$), and the inverse persistence ($\theta$). Our results indicate that larger forecast errors -- e.g., higher MSE -- tend to occur in states with higher $d$ (higher complexity) and higher $\theta$ (lower persistence). To further assess dynamical consistency, we propose error metrics based on the dynamical indices that measure the discrepancy of the forecasted $d$ and $\theta$ versus their correct values. Leveraging these dynamical indices-based metrics, we analyze direct and recursive forecasting strategies for three canonical datasets -- Lorenz, Kuramoto-Sivashinsky equation, and Kolmogorov flow -- as well as a real-world weather forecasting task. Our findings reveal substantial distortions in dynamical properties in ML forecasts, especially for long forecast lead times or long recursive simulations, providing complementary information on ML forecast fidelity that can be used to improve ML models.
XAI4Extremes: An interpretable machine learning framework for understanding extreme-weather precursors under climate change
Mar 11, 2025Extreme weather events are increasing in frequency and intensity due to climate change. This, in turn, is exacting a significant toll in communities worldwide. While prediction skills are increasing with advances in numerical weather prediction and artificial intelligence tools, extreme weather still present challenges. More specifically, identifying the precursors of such extreme weather events and how these precursors may evolve under climate change remain unclear. In this paper, we propose to use post-hoc interpretability methods to construct relevance weather maps that show the key extreme-weather precursors identified by deep learning models. We then compare this machine view with existing domain knowledge to understand whether deep learning models identified patterns in data that may enrich our understanding of extreme-weather precursors. We finally bin these relevant maps into different multi-year time periods to understand the role that climate change is having on these precursors. The experiments are carried out on Indochina heatwaves, but the methodology can be readily extended to other extreme weather events worldwide.