 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vision for Multisensory Intelligence: Sensing, Synergy, and Science
Jan 08, 2026Our experience of the world is multisensory, spanning a synthesis of language, sight, sound, touch, taste, and smell. Yet, artificial intelligence has primarily advanced in digital modalities like text, vision, and audio. This paper outlines a research vision for multisensory artificial intelligence over the next decade. This new set of technologies can change how humans and AI experience and interact with one another, by connecting AI to the human senses and a rich spectrum of signals from physiological and tactile cues on the body, to physical and social signals in homes, cities, and the environment. We outline how this field must advance through three interrelated themes of sensing, science, and synergy. Firstly, research in sensing should extend how AI captures the world in richer ways beyond the digital medium. Secondly, developing a principled science for quantifying multimodal heterogeneity and interactions, developing unified modeling architectures and representations, and understanding cross-modal transfer. Finally, we present new technical challenges to learn synergy between modalities and between humans and AI, covering multisensory integration, alignment, reasoning, generation, generalization, and experience. Accompanying this vision paper are a series of projects, resources, and demos of latest advances from the Multisensory Intelligence group at the MIT Media Lab, see https://mit-mi.github.io/.
Propose, Solve, Verify: Self-Play Through Formal Verification
Dec 20, 2025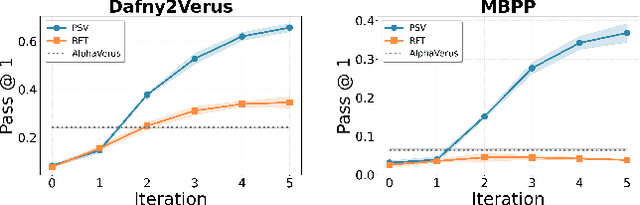
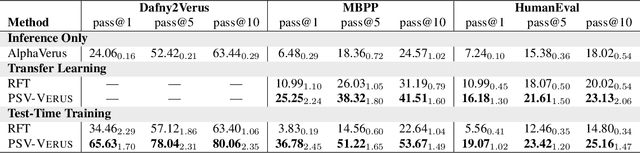
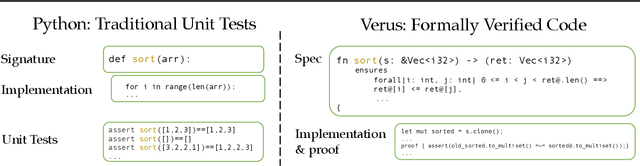

Training models through self-play alone (without any human data) has been a longstanding goal in AI, but its effectiveness for training large language models remains unclear, particularly in code generation where rewards based on unit tests are brittle and prone to error propagation. We study self-play in the verified code generation setting, where formal verification provides reliable correctness signals. We introduce Propose, Solve, Verify (PSV) a simple self-play framework where formal verification signals are used to create a proposer capable of generating challenging synthetic problems and a solver trained via expert iteration. We use PSV to train PSV-Verus, which across three benchmarks improves pass@1 by up to 9.6x over inference-only and expert-iteration baselines. We show that performance scales with the number of generated questions and training iterations, and through ablations identify formal verification and difficulty-aware proposal as essential ingredients for successful self-play.
When Reasoning Meets Its Laws
Dec 19, 2025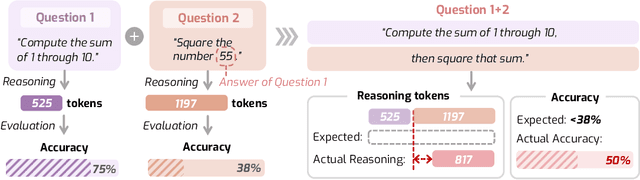
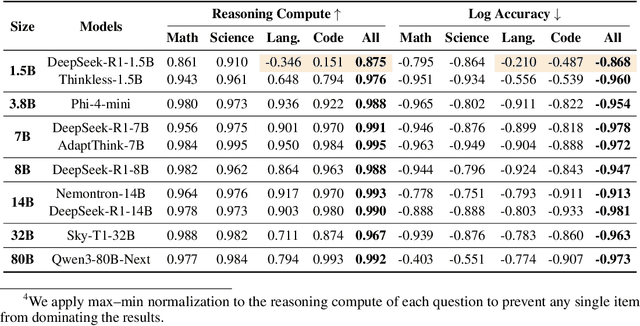
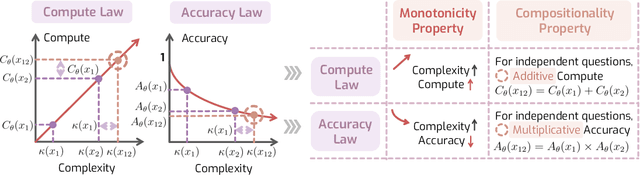
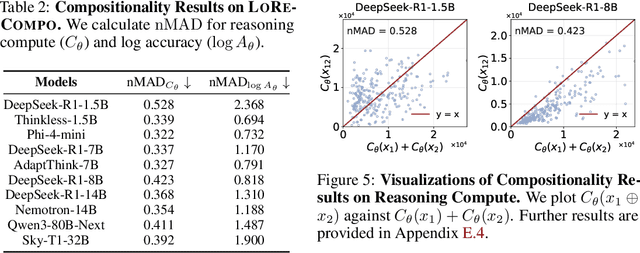
Despite the superior performance of Large Reasoning Models (LRMs), their reasoning behaviors are often counterintuitive, leading to suboptimal reasoning capabilities. To theoretically formalize the desired reasoning behaviors, this paper presents the Laws of Reasoning (LoRe), a unified framework that characterizes intrinsic reasoning patterns in LRMs. We first propose compute law with the hypothesis that the reasoning compute should scale linearly with question complexity. Beyond compute, we extend LoRe with a supplementary accuracy law. Since the question complexity is difficult to quantify in practice, we examine these hypotheses by two properties of the laws, monotonicity and compositionality. We therefore introduce LoRe-Bench, a benchmark that systematically measures these two tractable properties for large reasoning models. Evaluation shows that most reasoning models exhibit reasonable monotonicity but lack compositionality. In response, we develop an effective finetuning approach that enforces compute-law compositionality. Extensive empirical studies demonstrate that better compliance with compute laws yields consistently improved reasoning performance on multiple benchmarks, and uncovers synergistic effects across properties and laws. Project page: https://lore-project.github.io/
OPENTOUCH: Bringing Full-Hand Touch to Real-World Interaction
Dec 18, 2025The human hand is our primary interface to the physical world, yet egocentric perception rarely knows when, where, or how forcefully it makes contact. Robust wearable tactile sensors are scarce, and no existing in-the-wild datasets align first-person video with full-hand touch. To bridge the gap between visual perception and physical interaction, we present OpenTouch, the first in-the-wild egocentric full-hand tactile dataset, containing 5.1 hours of synchronized video-touch-pose data and 2,900 curated clips with detailed text annotations. Using OpenTouch, we introduce retrieval and classification benchmarks that probe how touch grounds perception and action. We show that tactile signals provide a compact yet powerful cue for grasp understanding, strengthen cross-modal alignment, and can be reliably retrieved from in-the-wild video queries. By releasing this annotated vision-touch-pose dataset and benchmark, we aim to advance multimodal egocentric perception, embodied learning, and contact-rich robotic manipulation.
Towards a Science of Scaling Agent Systems
Dec 17, 2025Agents, language model-based systems that are capable of reasoning, planning, and acting are becoming the dominant paradigm for real-world AI applications. Despite this widespread adoption, the principles that determine their performance remain underexplored. We address this by deriving quantitative scaling principles for agent systems. We first formalize a definition for agentic evaluation and characterize scaling laws as the interplay between agent quantity, coordination structure, model capability, and task properties. We evaluate this across four benchmarks: Finance-Agent, BrowseComp-Plus, PlanCraft, and Workbench. With five canonical agent architectures (Single-Agent and four Multi-Agent Systems: Independent, Centralized, Decentralized, Hybrid), instantiated across three LLM families, we perform a controlled evaluation spanning 180 configurations. We derive a predictive model using coordination metrics, that achieves cross-validated R^2=0.524, enabling prediction on unseen task domains. We identify three effects: (1) a tool-coordination trade-off: under fixed computational budgets, tool-heavy tasks suffer disproportionately from multi-agent overhead. (2) a capability saturation: coordination yields diminishing or negative returns once single-agent baselines exceed ~45%. (3) topology-dependent error amplification: independent agents amplify errors 17.2x, while centralized coordination contains this to 4.4x. Centralized coordination improves performance by 80.8% on parallelizable tasks, while decentralized coordination excels on web navigation (+9.2% vs. +0.2%). Yet for sequential reasoning tasks, every multi-agent variants degraded performance by 39-70%. The framework predicts the optimal coordination strategy for 87% of held-out configurations. Out-of-sample validation on GPT-5.2, achieves MAE=0.071 and confirms four of five scaling principles generalize to unseen frontier models.
Schrodinger Audio-Visual Editor: Object-Level Audiovisual Removal
Dec 14, 2025Joint editing of audio and visual content is crucial for precise and controllable content creation. This new task poses challenges due to the limitations of paired audio-visual data before and after targeted edits, and the heterogeneity across modalities. To address the data and modeling challenges in joint audio-visual editing, we introduce SAVEBench, a paired audiovisual dataset with text and mask conditions to enable object-grounded source-to-target learning. With SAVEBench, we train the Schrodinger Audio-Visual Editor (SAVE), an end-to-end flow-matching model that edits audio and video in parallel while keeping them aligned throughout processing. SAVE incorporates a Schrodinger Bridge that learns a direct transport from source to target audiovisual mixtures. Our evaluation demonstrates that the proposed SAVE model is able to remove the target objects in audio and visual content while preserving the remaining content, with stronger temporal synchronization and audiovisual semantic correspondence compared with pairwise combinations of an audio editor and a video editor.
Abstract 3D Perception for Spatial Intelligence in Vision-Language Models
Nov 14, 2025Vision-language models (VLMs) struggle with 3D-related tasks such as spatial cognition and physical understanding, which are crucial for real-world applications like robotics and embodied agents. We attribute this to a modality gap between the 3D tasks and the 2D training of VLM, which led to inefficient retrieval of 3D information from 2D input. To bridge this gap, we introduce SandboxVLM, a simple yet effective framework that leverages abstract bounding boxes to encode geometric structure and physical kinematics for VLM. Specifically, we design a 3D Sandbox reconstruction and perception pipeline comprising four stages: generating multi-view priors with abstract control, proxy elevation, multi-view voting and clustering, and 3D-aware reasoning. Evaluated in zero-shot settings across multiple benchmarks and VLM backbones, our approach consistently improves spatial intelligence, achieving an 8.3\% gain on SAT Real compared with baseline methods for instance. These results demonstrate that equipping VLMs with a 3D abstraction substantially enhances their 3D reasoning ability without additional training, suggesting new possibilities for general-purpose embodied intelligence.
Partial Information Decomposition via Normalizing Flows in Latent Gaussian Distributions
Oct 06, 2025The study of multimodality has garnered significant interest in fields where the analysis of interactions among multiple information sources can enhance predictive modeling, data fusion, and interpretability. Partial information decomposition (PID) has emerged as a useful information-theoretic framework to quantify the degree to which individual modalities independently, redundantly, or synergistically convey information about a target variable. However, existing PID methods depend on optimizing over a joint distribution constrained by estimated pairwise probability distributions, which are costly and inaccurate for continuous and high-dimensional modalities. Our first key insight is that the problem can be solved efficiently when the pairwise distributions are multivariate Gaussians, and we refer to this problem as Gaussian PID (GPID). We propose a new gradient-based algorithm that substantially improves the computational efficiency of GPID based on an alternative formulation of the underlying optimization problem. To generalize the applicability to non-Gaussian data, we learn information-preserving encoders to transform random variables of arbitrary input distributions into pairwise Gaussian random variables. Along the way, we resolved an open problem regarding the optimality of joint Gaussian solutions for GPID. Empirical validation in diverse synthetic examples demonstrates that our proposed method provides more accurate and efficient PID estimates than existing baselines. We further evaluate a series of large-scale multimodal benchmarks to show its utility in real-world applications of quantifying PID in multimodal datasets and selecting high-performing models.
Human Behavior Atlas: Benchmarking Unified Psychological and Social Behavior Understanding
Oct 06, 2025Using intelligent systems to perceive psychological and social behaviors, that is, the underlying affective, cognitive, and pathological states that are manifested through observable behaviors and social interactions, remains a challenge due to their complex, multifaceted, and personalized nature. Existing work tackling these dimensions through specialized datasets and single-task systems often miss opportunities for scalability, cross-task transfer, and broader generalization. To address this gap, we curate Human Behavior Atlas, a unified benchmark of diverse behavioral tasks designed to support the development of unified models for understanding psychological and social behaviors. Human Behavior Atlas comprises over 100,000 samples spanning text, audio, and visual modalities, covering tasks on affective states, cognitive states, pathologies, and social processes. Our unification efforts can reduce redundancy and cost, enable training to scale efficiently across tasks, and enhance generalization of behavioral features across domains. On Human Behavior Atlas, we train three models: OmniSapiens-7B SFT, OmniSapiens-7B BAM, and OmniSapiens-7B RL. We show that training on Human Behavior Atlas enables models to consistently outperform existing multimodal LLMs across diverse behavioral tasks. Pretraining on Human Behavior Atlas also improves transfer to novel behavioral datasets; with the targeted use of behavioral descriptors yielding meaningful performance gains.
RADAR: A Reasoning-Guided Attribution Framework for Explainable Visual Data Analysis
Aug 23, 2025Data visualizations like charts are fundamental tools for quantitative analysis and decision-making across fields, requiring accurate interpretation and mathematical reasoning. The emergence of Multimodal Large Language Models (MLLMs) offers promising capabilities for automated visual data analysis, such as processing charts, answering questions, and generating summaries. However, they provide no visibility into which parts of the visual data informed their conclusions; this black-box nature poses significant challenges to real-world trust and adoption. In this paper, we take the first major step towards evaluating and enhancing the capabilities of MLLMs to attribute their reasoning process by highlighting the specific regions in charts and graphs that justify model answers. To this end, we contribute RADAR, a semi-automatic approach to obtain a benchmark dataset comprising 17,819 diverse samples with charts, questions, reasoning steps, and attribution annotations. We also introduce a method that provides attribution for chart-based mathematical reasoning. Experimental results demonstrate that our reasoning-guided approach improves attribution accuracy by 15% compared to baseline methods, and enhanced attribution capabilities translate to stronger answer generation, achieving an average BERTScore of $\sim$ 0.90, indicating high alignment with ground truth responses. This advancement represents a significant step toward more interpretable and trustworthy chart analysis systems, enabling users to verify and understand model decisions through reasoning and attribution.