 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePuzzleWorld: A Benchmark for Multimodal, Open-Ended Reasoning in Puzzlehunts
Jun 06, 2025Puzzlehunts are a genre of complex, multi-step puzzles lacking well-defined problem definitions. In contrast to conventional reasoning benchmarks consisting of tasks with clear instructions, puzzlehunts require models to discover the underlying problem structure from multimodal evidence and iterative reasoning, mirroring real-world domains such as scientific discovery, exploratory data analysis, or investigative problem-solving. Despite recent progress in foundation models, their performance on such open-ended settings remains largely untested. In this paper, we introduce PuzzleWorld, a large-scale benchmark of 667 puzzlehunt-style problems designed to assess step-by-step, open-ended, and creative multimodal reasoning. Each puzzle is annotated with the final solution, detailed reasoning traces, and cognitive skill labels, enabling holistic benchmarking and fine-grained diagnostic analysis. Most state-of-the-art models achieve only 1-2% final answer accuracy, with the best model solving only 14% of puzzles and reaching 40% stepwise accuracy. To demonstrate the value of our reasoning annotations, we show that fine-tuning a small model on reasoning traces improves stepwise reasoning from 4% to 11%, while training on final answers alone degrades performance to near zero. Our error analysis reveals that current models exhibit myopic reasoning, are bottlenecked by the limitations of language-based inference, and lack sketching capabilities crucial for visual and spatial reasoning. We release PuzzleWorld at https://github.com/MIT-MI/PuzzleWorld to support future work on building more general, open-ended, and creative reasoning systems.
MimeQA: Towards Socially-Intelligent Nonverbal Foundation Models
Feb 23, 2025Socially intelligent AI that can understand and interact seamlessly with humans in daily lives is increasingly important as AI becomes more closely integrated with peoples' daily activities. However, current works in artificial social reasoning all rely on language-only, or language-dominant approaches to benchmark and training models, resulting in systems that are improving in verbal communication but struggle with nonverbal social understanding. To address this limitation, we tap into a novel source of data rich in nonverbal and social interactions -- mime videos. Mimes refer to the art of expression through gesture and movement without spoken words, which presents unique challenges and opportunities in interpreting non-verbal social communication. We contribute a new dataset called MimeQA, obtained by sourcing 221 videos from YouTube, through rigorous annotation and verification, resulting in a benchmark with 101 videos and 806 question-answer pairs. Using MimeQA, we evaluate state-of-the-art video large language models (vLLMs) and find that their overall accuracy ranges from 15-30%. Our analysis reveals that vLLMs often fail to ground imagined objects and over-rely on the text prompt while ignoring subtle nonverbal interactions. Our data resources are released at https://github.com/MIT-MI/MimeQA to inspire future work in foundation models that embody true social intelligence capable of interpreting non-verbal human interactions.
Understanding the Emergence of Multimodal Representation Alignment
Feb 22, 2025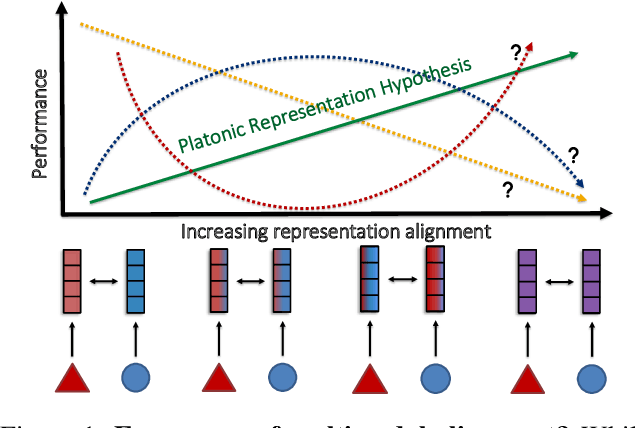


Multimodal representation learning is fundamentally about transforming incomparable modalities into comparable representations. While prior research primarily focused on explicitly aligning these representations through targeted learning objectives and model architectures, a recent line of work has found that independently trained unimodal models of increasing scale and performance can become implicitly aligned with each other. These findings raise fundamental questions regarding the emergence of aligned representations in multimodal learning. Specifically: (1) when and why does alignment emerge implicitly? and (2) is alignment a reliable indicator of performance? Through a comprehensive empirical investigation, we demonstrate that both the emergence of alignment and its relationship with task performance depend on several critical data characteristics. These include, but are not necessarily limited to, the degree of similarity between the modalities and the balance between redundant and unique information they provide for the task. Our findings suggest that alignment may not be universally beneficial; rather, its impact on performance varies depending on the dataset and task. These insights can help practitioners determine whether increasing alignment between modalities is advantageous or, in some cases, detrimental to achieving optimal performance. Code is released at https://github.com/MeganTj/multimodal_alignment.
How Can Large Language Models Help Humans in Design and Manufacturing?
Jul 25, 2023The advancement of Large Language Models (LLMs), including GPT-4, provides exciting new opportunities for generative design. We investigate the application of this tool across the entire design and manufacturing workflow. Specifically, we scrutinize the utility of LLMs in tasks such as: converting a text-based prompt into a design specification, transforming a design into manufacturing instructions, producing a design space and design variations, computing the performance of a design, and searching for designs predicated on performance. Through a series of examples, we highlight both the benefits and the limitations of the current LLMs. By exposing these limitations, we aspire to catalyze the continued improvement and progression of these models.
Neurosymbolic Programming for Science
Oct 10, 2022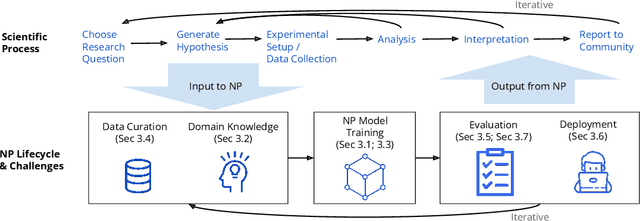
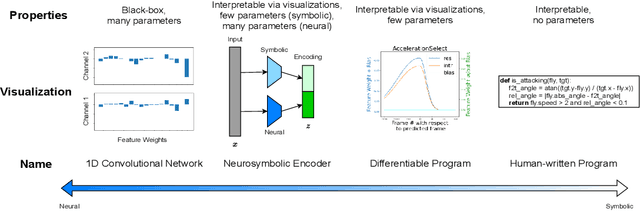
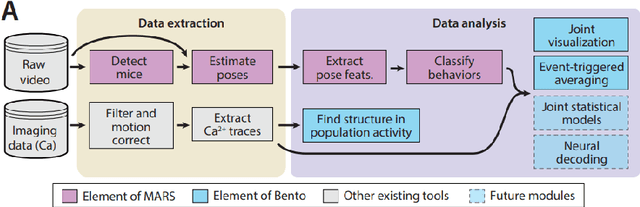
Neurosymbolic Programming (NP) techniques have the potential to accelerate scientific discovery across fields. These models combine neural and symbolic components to learn complex patterns and representations from data, using high-level concepts or known constraints. As a result, NP techniques can interface with symbolic domain knowledge from scientists, such as prior knowledge and experimental context, to produce interpretable outputs. Here, we identify opportunities and challenges between current NP models and scientific workflows, with real-world examples from behavior analysis in science. We define concrete next steps to move the NP for science field forward, to enable its use broadly for workflows across the natural and social sciences.
ZeroC: A Neuro-Symbolic Model for Zero-shot Concept Recognition and Acquisition at Inference Time
Jul 03, 2022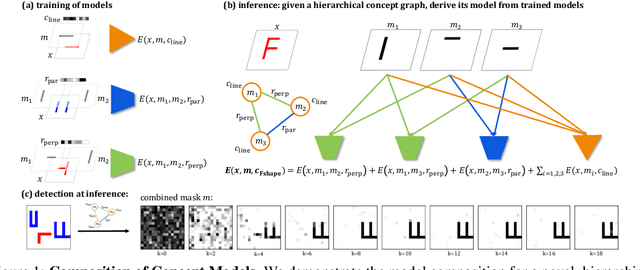
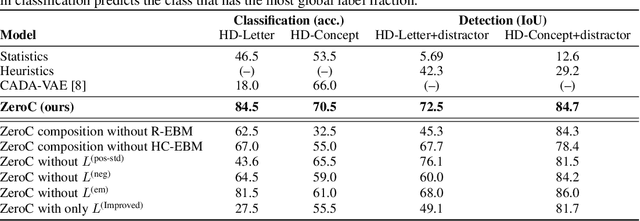
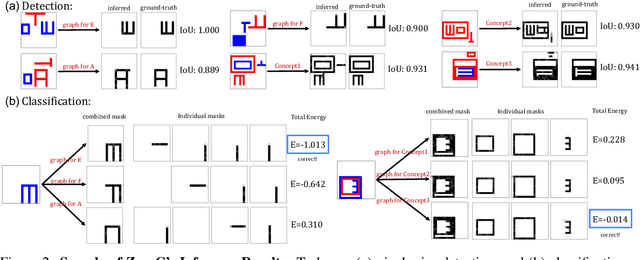
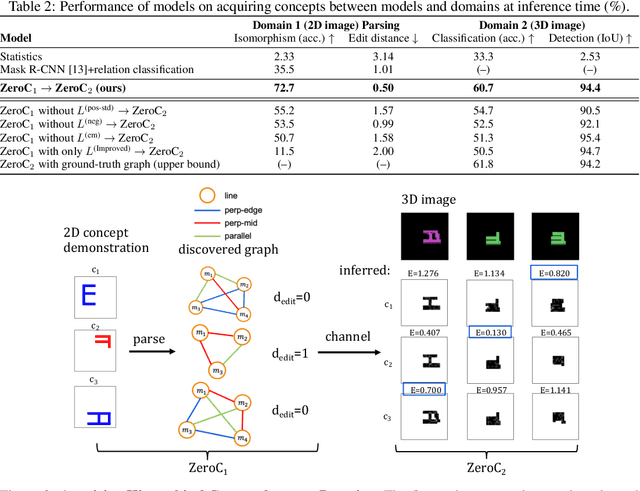
Humans have the remarkable ability to recognize and acquire novel visual concepts in a zero-shot manner. Given a high-level, symbolic description of a novel concept in terms of previously learned visual concepts and their relations, humans can recognize novel concepts without seeing any examples. Moreover, they can acquire new concepts by parsing and communicating symbolic structures using learned visual concepts and relations. Endowing these capabilities in machines is pivotal in improving their generalization capability at inference time. In this work, we introduce Zero-shot Concept Recognition and Acquisition (ZeroC), a neuro-symbolic architecture that can recognize and acquire novel concepts in a zero-shot way. ZeroC represents concepts as graphs of constituent concept models (as nodes) and their relations (as edges). To allow inference time composition, we employ energy-based models (EBMs) to model concepts and relations. We design ZeroC architecture so that it allows a one-to-one mapping between a symbolic graph structure of a concept and its corresponding EBM, which for the first time, allows acquiring new concepts, communicating its graph structure, and applying it to classification and detection tasks (even across domains) at inference time. We introduce algorithms for learning and inference with ZeroC. We evaluate ZeroC on a challenging grid-world dataset which is designed to probe zero-shot concept recognition and acquisition, and demonstrate its capability.
Interpreting Expert Annotation Differences in Animal Behavior
Jun 11, 2021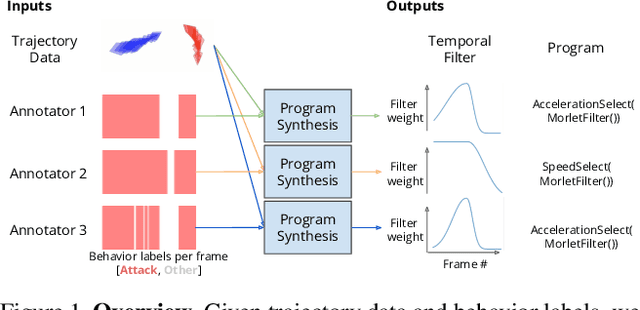

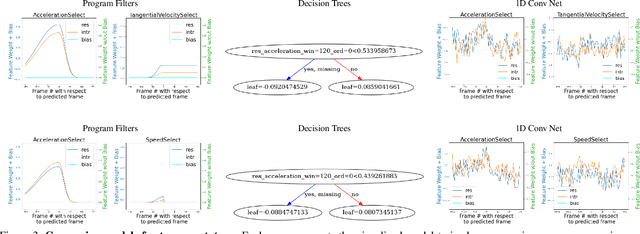
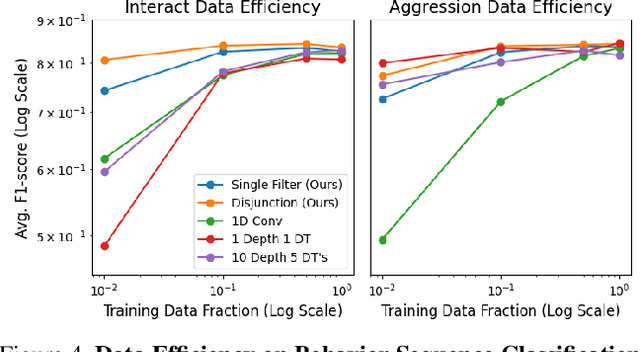
Hand-annotated data can vary due to factors such as subjective differences, intra-rater variability, and differing annotator expertise. We study annotations from different experts who labelled the same behavior classes on a set of animal behavior videos, and observe a variation in annotation styles. We propose a new method using program synthesis to help interpret annotation differences for behavior analysis. Our model selects relevant trajectory features and learns a temporal filter as part of a program, which corresponds to estimated importance an annotator places on that feature at each timestamp. Our experiments on a dataset from behavioral neuroscience demonstrate that compared to baseline approaches, our method is more accurate at capturing annotator labels and learns interpretable temporal filters. We believe that our method can lead to greater reproducibility of behavior annotations used in scientific studies. We plan to release our code.