 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroAtlas: Benchmarking Foundation Models for Clinical EEG and Brain-Computer Interfaces
May 14, 2026Foundation models (FMs) promise to extract unified representations that generalize across downstream tasks. They have emerged across fields, including electroencephalography (EEG), but it is less clear how effective they are in this particular field. Published evaluations differ in datasets, in the EEG-specific preprocessing that might influence reported results, and in the reported metrics, frequently obscuring the clinical relevance in EEG. We introduce NeuroAtlas, the largest EEG benchmark to date: 42 datasets and 260k hours covering clinical EEG (epilepsy, sleep medicine, brain age estimation) and brain-computer interfaces, and include multiple datasets per task along with bespoke clinical evaluation metrics. Besides evaluating EEG-FMs with respect to supervised baselines, we present results from generic time-series FMs. We report three findings. First, EEG-specific FMs do not consistently outperform time-series FMs, which have neither EEG-focused architectures nor been pretrained on EEG. Second, standard machine learning metrics are insufficient to assess clinical utility: thus, we thoroughly evaluate more appropriate measures such as the quality of event-level decision-making, hypnogram-derived features, and the brain-age gap in the domains of epilepsy, sleep, and brain age, respectively. Third, model rankings and performance can vary substantially within domains. We conclude that pretrained models perform largely on par, with only narrow advantages for a few, and that current models do not yet deliver on the promise of an out-of-the-box unified EEG model. NeuroAtlas exposes this gap and provides the datasets and metrics for the next generation of unified EEG FMs.
Interleaved Head Attention
Feb 24, 2026Multi-Head Attention (MHA) is the core computational primitive underlying modern Large Language Models (LLMs). However, MHA suffers from a fundamental linear scaling limitation: $H$ attention heads produce exactly $H$ independent attention matrices, with no communication between heads during attention computation. This becomes problematic for multi-step reasoning, where correct answers depend on aggregating evidence from multiple parts of the context and composing latent token-to-token relations over a chain of intermediate inferences. To address this, we propose Interleaved Head Attention (IHA), which enables cross-head mixing by constructing $P$ pseudo-heads per head (typically $P=H$), where each pseudo query/key/value is a learned linear combination of all $H$ original queries, keys and values respectively. Interactions between pseudo-query and pseudo-key heads induce up to $P^2$ attention patterns per head with modest parameter overhead $\mathcal{O}(H^2P)$. We provide theory showing improved efficiency in terms of number of parameters on the synthetic Polynomial task (IHA uses $Θ(\sqrt{k}n^2)$ parameters vs. $Θ(kn^2)$ for MHA) and on the synthetic order-sensitive CPM-3 task (IHA uses $\lceil\sqrt{N_{\max}}\rceil$ heads vs. $N_{\max}$ for MHA). On real-world benchmarks, IHA improves Multi-Key retrieval on RULER by 10-20% (4k-16k) and, after fine-tuning for reasoning on OpenThoughts, improves GSM8K by 5.8% and MATH-500 by 2.8% (Majority Vote) over full attention.
OmniSapiens: A Foundation Model for Social Behavior Processing via Heterogeneity-Aware Relative Policy Optimization
Feb 11, 2026To develop socially intelligent AI, existing approaches typically model human behavioral dimensions (e.g., affective, cognitive, or social attributes) in isolation. Although useful, task-specific modeling often increases training costs and limits generalization across behavioral settings. Recent reasoning RL methods facilitate training a single unified model across multiple behavioral tasks, but do not explicitly address learning across different heterogeneous behavioral data. To address this gap, we introduce Heterogeneity-Aware Relative Policy Optimization (HARPO), an RL method that balances leaning across heterogeneous tasks and samples. This is achieved by modulating advantages to ensure that no single task or sample carries disproportionate influence during policy optimization. Using HARPO, we develop and release Omnisapiens-7B 2.0, a foundation model for social behavior processing. Relative to existing behavioral foundation models, Omnisapiens-7B 2.0 achieves the strongest performance across behavioral tasks, with gains of up to +16.85% and +9.37% on multitask and held-out settings respectively, while producing more explicit and robust reasoning traces. We also validate HARPO against recent RL methods, where it achieves the most consistently strong performance across behavioral tasks.
MURPHY: Multi-Turn GRPO for Self Correcting Code Generation
Nov 11, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a powerful framework for enhancing the reasoning capabilities of large language models (LLMs). However, existing approaches such as Group Relative Policy Optimization (GRPO) and its variants, while effective on reasoning benchmarks, struggle with agentic tasks that require iterative decision-making. We introduce Murphy, a multi-turn reflective optimization framework that extends GRPO by incorporating iterative self-correction during training. By leveraging both quantitative and qualitative execution feedback, Murphy enables models to progressively refine their reasoning across multiple turns. Evaluations on code generation benchmarks with model families such as Qwen and OLMo show that Murphy consistently improves performance, achieving up to a 8% relative gain in pass@1 over GRPO, on similar compute budgets.
What One Cannot, Two Can: Two-Layer Transformers Provably Represent Induction Heads on Any-Order Markov Chains
Aug 10, 2025In-context learning (ICL) is a hallmark capability of transformers, through which trained models learn to adapt to new tasks by leveraging information from the input context. Prior work has shown that ICL emerges in transformers due to the presence of special circuits called induction heads. Given the equivalence between induction heads and conditional k-grams, a recent line of work modeling sequential inputs as Markov processes has revealed the fundamental impact of model depth on its ICL capabilities: while a two-layer transformer can efficiently represent a conditional 1-gram model, its single-layer counterpart cannot solve the task unless it is exponentially large. However, for higher order Markov sources, the best known constructions require at least three layers (each with a single attention head) - leaving open the question: can a two-layer single-head transformer represent any kth-order Markov process? In this paper, we precisely address this and theoretically show that a two-layer transformer with one head per layer can indeed represent any conditional k-gram. Thus, our result provides the tightest known characterization of the interplay between transformer depth and Markov order for ICL. Building on this, we further analyze the learning dynamics of our two-layer construction, focusing on a simplified variant for first-order Markov chains, illustrating how effective in-context representations emerge during training. Together, these results deepen our current understanding of transformer-based ICL and illustrate how even shallow architectures can surprisingly exhibit strong ICL capabilities on structured sequence modeling tasks.
PuzzleWorld: A Benchmark for Multimodal, Open-Ended Reasoning in Puzzlehunts
Jun 06, 2025Puzzlehunts are a genre of complex, multi-step puzzles lacking well-defined problem definitions. In contrast to conventional reasoning benchmarks consisting of tasks with clear instructions, puzzlehunts require models to discover the underlying problem structure from multimodal evidence and iterative reasoning, mirroring real-world domains such as scientific discovery, exploratory data analysis, or investigative problem-solving. Despite recent progress in foundation models, their performance on such open-ended settings remains largely untested. In this paper, we introduce PuzzleWorld, a large-scale benchmark of 667 puzzlehunt-style problems designed to assess step-by-step, open-ended, and creative multimodal reasoning. Each puzzle is annotated with the final solution, detailed reasoning traces, and cognitive skill labels, enabling holistic benchmarking and fine-grained diagnostic analysis. Most state-of-the-art models achieve only 1-2% final answer accuracy, with the best model solving only 14% of puzzles and reaching 40% stepwise accuracy. To demonstrate the value of our reasoning annotations, we show that fine-tuning a small model on reasoning traces improves stepwise reasoning from 4% to 11%, while training on final answers alone degrades performance to near zero. Our error analysis reveals that current models exhibit myopic reasoning, are bottlenecked by the limitations of language-based inference, and lack sketching capabilities crucial for visual and spatial reasoning. We release PuzzleWorld at https://github.com/MIT-MI/PuzzleWorld to support future work on building more general, open-ended, and creative reasoning systems.
TAMP: Token-Adaptive Layerwise Pruning in Multimodal Large Language Models
Apr 15, 2025Multimodal Large Language Models (MLLMs) have shown remarkable versatility in understanding diverse multimodal data and tasks. However, these capabilities come with an increased model scale. While post-training pruning reduces model size in unimodal models, its application to MLLMs often yields limited success. Our analysis discovers that conventional methods fail to account for the unique token attributes across layers and modalities inherent to MLLMs. Inspired by this observation, we propose TAMP, a simple yet effective pruning framework tailored for MLLMs, featuring two key components: (1) Diversity-Aware Sparsity, which adjusts sparsity ratio per layer based on diversities among multimodal output tokens, preserving more parameters in high-diversity layers; and (2) Adaptive Multimodal Input Activation, which identifies representative multimodal input tokens using attention scores to guide unstructured weight pruning. We validate our method on two state-of-the-art MLLMs: LLaVA-NeXT, designed for vision-language tasks, and VideoLLaMA2, capable of processing audio, visual, and language modalities. Empirical experiments across various multimodal evaluation benchmarks demonstrate that each component of our approach substantially outperforms existing pruning techniques.
Understanding the Emergence of Multimodal Representation Alignment
Feb 22, 2025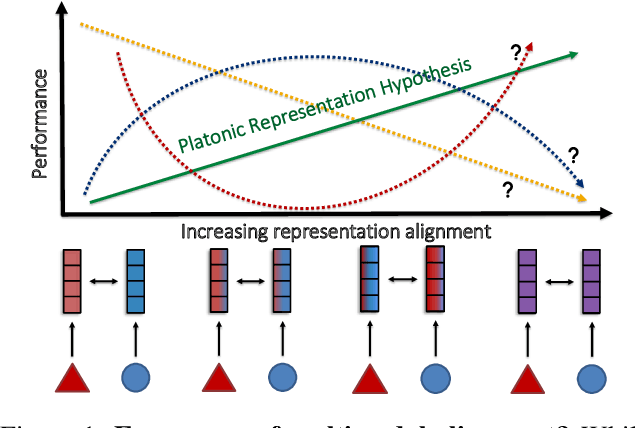


Multimodal representation learning is fundamentally about transforming incomparable modalities into comparable representations. While prior research primarily focused on explicitly aligning these representations through targeted learning objectives and model architectures, a recent line of work has found that independently trained unimodal models of increasing scale and performance can become implicitly aligned with each other. These findings raise fundamental questions regarding the emergence of aligned representations in multimodal learning. Specifically: (1) when and why does alignment emerge implicitly? and (2) is alignment a reliable indicator of performance? Through a comprehensive empirical investigation, we demonstrate that both the emergence of alignment and its relationship with task performance depend on several critical data characteristics. These include, but are not necessarily limited to, the degree of similarity between the modalities and the balance between redundant and unique information they provide for the task. Our findings suggest that alignment may not be universally beneficial; rather, its impact on performance varies depending on the dataset and task. These insights can help practitioners determine whether increasing alignment between modalities is advantageous or, in some cases, detrimental to achieving optimal performance. Code is released at https://github.com/MeganTj/multimodal_alignment.
Local to Global: Learning Dynamics and Effect of Initialization for Transformers
Jun 05, 2024



In recent years, transformer-based models have revolutionized deep learning, particularly in sequence modeling. To better understand this phenomenon, there is a growing interest in using Markov input processes to study transformers. However, our current understanding in this regard remains limited with many fundamental questions about how transformers learn Markov chains still unanswered. In this paper, we address this by focusing on first-order Markov chains and single-layer transformers, providing a comprehensive characterization of the learning dynamics in this context. Specifically, we prove that transformer parameters trained on next-token prediction loss can either converge to global or local minima, contingent on the initialization and the Markovian data properties, and we characterize the precise conditions under which this occurs. To the best of our knowledge, this is the first result of its kind highlighting the role of initialization. We further demonstrate that our theoretical findings are corroborated by empirical evidence. Based on these insights, we provide guidelines for the initialization of transformer parameters and demonstrate their effectiveness. Finally, we outline several open problems in this arena. Code is available at: \url{https://anonymous.4open.science/r/Local-to-Global-C70B/}.
FiGURe: Simple and Efficient Unsupervised Node Representations with Filter Augmentations
Oct 04, 2023



Unsupervised node representations learnt using contrastive learning-based methods have shown good performance on downstream tasks. However, these methods rely on augmentations that mimic low-pass filters, limiting their performance on tasks requiring different eigen-spectrum parts. This paper presents a simple filter-based augmentation method to capture different parts of the eigen-spectrum. We show significant improvements using these augmentations. Further, we show that sharing the same weights across these different filter augmentations is possible, reducing the computational load. In addition, previous works have shown that good performance on downstream tasks requires high dimensional representations. Working with high dimensions increases the computations, especially when multiple augmentations are involved. We mitigate this problem and recover good performance through lower dimensional embeddings using simple random Fourier feature projections. Our method, FiGURe achieves an average gain of up to 4.4%, compared to the state-of-the-art unsupervised models, across all datasets in consideration, both homophilic and heterophilic. Our code can be found at: https://github.com/microsoft/figure.