 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRare Event Analysis via Stochastic Optimal Control
Apr 14, 2026Rare events such as conformational changes in biomolecules, phase transitions, and chemical reactions are central to the behavior of many physical systems, yet they are extremely difficult to study computationally because unbiased simulations seldom produce them. Transition Path Theory (TPT) provides a rigorous statistical framework for analyzing such events: it characterizes the ensemble of reactive trajectories between two designated metastable states (reactant and product), and its central object--the committor function, which gives the probability that the system will next reach the product rather than the reactant--encodes all essential kinetic and thermodynamic information. We introduce a framework that casts committor estimation as a stochastic optimal control (SOC) problem. In this formulation the committor defines a feedback control--proportional to the gradient of its logarithm--that actively steers trajectories toward the reactive region, thereby enabling efficient sampling of reactive paths. To solve the resulting hitting-time control problem we develop two complementary objectives: a direct backpropagation loss and a principled off-policy Value Matching loss, for which we establish first-order optimality guarantees. We further address metastability, which can trap controlled trajectories in intermediate basins, by introducing an alternative sampling process that preserves the reactive current while lowering effective energy barriers. On benchmark systems, the framework yields markedly more accurate committor estimates, reaction rates, and equilibrium constants than existing methods.
Test-time Recursive Thinking: Self-Improvement without External Feedback
Feb 03, 2026Modern Large Language Models (LLMs) have shown rapid improvements in reasoning capabilities, driven largely by reinforcement learning (RL) with verifiable rewards. Here, we ask whether these LLMs can self-improve without the need for additional training. We identify two core challenges for such systems: (i) efficiently generating diverse, high-quality candidate solutions, and (ii) reliably selecting correct answers in the absence of ground-truth supervision. To address these challenges, we propose Test-time Recursive Thinking (TRT), an iterative self-improvement framework that conditions generation on rollout-specific strategies, accumulated knowledge, and self-generated verification signals. Using TRT, open-source models reach 100% accuracy on AIME-25/24, and on LiveCodeBench's most difficult problems, closed-source models improve by 10.4-14.8 percentage points without external feedback.
Diffusion Large Language Models for Black-Box Optimization
Jan 20, 2026Offline black-box optimization (BBO) aims to find optimal designs based solely on an offline dataset of designs and their labels. Such scenarios frequently arise in domains like DNA sequence design and robotics, where only a few labeled data points are available. Traditional methods typically rely on task-specific proxy or generative models, overlooking the in-context learning capabilities of pre-trained large language models (LLMs). Recent efforts have adapted autoregressive LLMs to BBO by framing task descriptions and offline datasets as natural language prompts, enabling direct design generation. However, these designs often contain bidirectional dependencies, which left-to-right models struggle to capture. In this paper, we explore diffusion LLMs for BBO, leveraging their bidirectional modeling and iterative refinement capabilities. This motivates our in-context denoising module: we condition the diffusion LLM on the task description and the offline dataset, both formatted in natural language, and prompt it to denoise masked designs into improved candidates. To guide the generation toward high-performing designs, we introduce masked diffusion tree search, which casts the denoising process as a step-wise Monte Carlo Tree Search that dynamically balances exploration and exploitation. Each node represents a partially masked design, each denoising step is an action, and candidates are evaluated via expected improvement under a Gaussian Process trained on the offline dataset. Our method, dLLM, achieves state-of-the-art results in few-shot settings on design-bench.
FlowRL: Matching Reward Distributions for LLM Reasoning
Sep 18, 2025We propose FlowRL: matching the full reward distribution via flow balancing instead of maximizing rewards in large language model (LLM) reinforcement learning (RL). Recent advanced reasoning models adopt reward-maximizing methods (\eg, PPO and GRPO), which tend to over-optimize dominant reward signals while neglecting less frequent but valid reasoning paths, thus reducing diversity. In contrast, we transform scalar rewards into a normalized target distribution using a learnable partition function, and then minimize the reverse KL divergence between the policy and the target distribution. We implement this idea as a flow-balanced optimization method that promotes diverse exploration and generalizable reasoning trajectories. We conduct experiments on math and code reasoning tasks: FlowRL achieves a significant average improvement of $10.0\%$ over GRPO and $5.1\%$ over PPO on math benchmarks, and performs consistently better on code reasoning tasks. These results highlight reward distribution-matching as a key step toward efficient exploration and diverse reasoning in LLM reinforcement learning.
Nabla-R2D3: Effective and Efficient 3D Diffusion Alignment with 2D Rewards
Jun 18, 2025Generating high-quality and photorealistic 3D assets remains a longstanding challenge in 3D vision and computer graphics. Although state-of-the-art generative models, such as diffusion models, have made significant progress in 3D generation, they often fall short of human-designed content due to limited ability to follow instructions, align with human preferences, or produce realistic textures, geometries, and physical attributes. In this paper, we introduce Nabla-R2D3, a highly effective and sample-efficient reinforcement learning alignment framework for 3D-native diffusion models using 2D rewards. Built upon the recently proposed Nabla-GFlowNet method, which matches the score function to reward gradients in a principled manner for reward finetuning, our Nabla-R2D3 enables effective adaptation of 3D diffusion models using only 2D reward signals. Extensive experiments show that, unlike vanilla finetuning baselines which either struggle to converge or suffer from reward hacking, Nabla-R2D3 consistently achieves higher rewards and reduced prior forgetting within a few finetuning steps.
Self-Evolving Curriculum for LLM Reasoning
May 20, 2025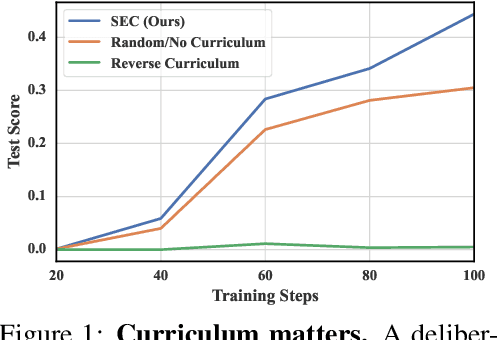
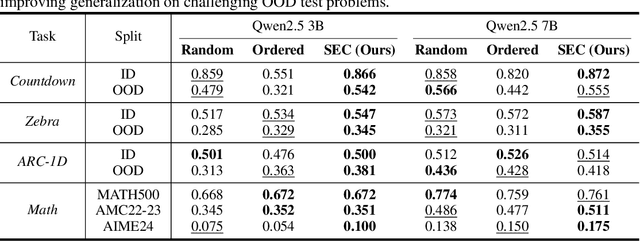
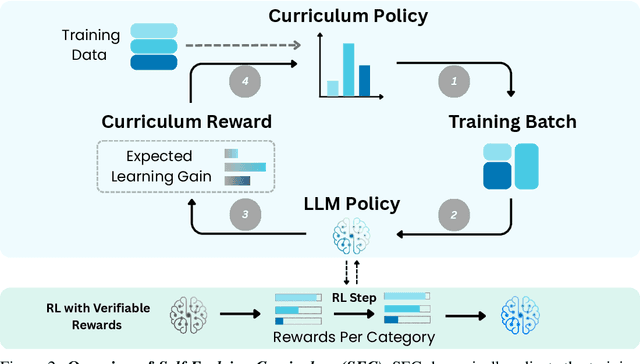
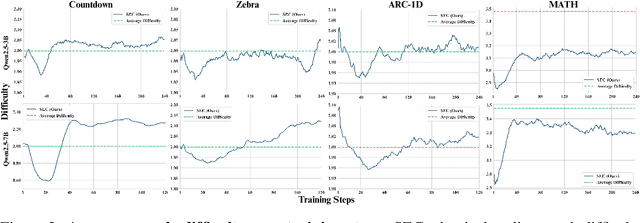
Reinforcement learning (RL) has proven effective for fine-tuning large language models (LLMs), significantly enhancing their reasoning abilities in domains such as mathematics and code generation. A crucial factor influencing RL fine-tuning success is the training curriculum: the order in which training problems are presented. While random curricula serve as common baselines, they remain suboptimal; manually designed curricula often rely heavily on heuristics, and online filtering methods can be computationally prohibitive. To address these limitations, we propose Self-Evolving Curriculum (SEC), an automatic curriculum learning method that learns a curriculum policy concurrently with the RL fine-tuning process. Our approach formulates curriculum selection as a non-stationary Multi-Armed Bandit problem, treating each problem category (e.g., difficulty level or problem type) as an individual arm. We leverage the absolute advantage from policy gradient methods as a proxy measure for immediate learning gain. At each training step, the curriculum policy selects categories to maximize this reward signal and is updated using the TD(0) method. Across three distinct reasoning domains: planning, inductive reasoning, and mathematics, our experiments demonstrate that SEC significantly improves models' reasoning capabilities, enabling better generalization to harder, out-of-distribution test problems. Additionally, our approach achieves better skill balance when fine-tuning simultaneously on multiple reasoning domains. These findings highlight SEC as a promising strategy for RL fine-tuning of LLMs.
Learning to Sample Effective and Diverse Prompts for Text-to-Image Generation
Feb 17, 2025Recent advances in text-to-image diffusion models have achieved impressive image generation capabilities. However, it remains challenging to control the generation process with desired properties (e.g., aesthetic quality, user intention), which can be expressed as black-box reward functions. In this paper, we focus on prompt adaptation, which refines the original prompt into model-preferred prompts to generate desired images. While prior work uses reinforcement learning (RL) to optimize prompts, we observe that applying RL often results in generating similar postfixes and deterministic behaviors. To this end, we introduce \textbf{P}rompt \textbf{A}daptation with \textbf{G}FlowNets (\textbf{PAG}), a novel approach that frames prompt adaptation as a probabilistic inference problem. Our key insight is that leveraging Generative Flow Networks (GFlowNets) allows us to shift from reward maximization to sampling from an unnormalized density function, enabling both high-quality and diverse prompt generation. However, we identify that a naive application of GFlowNets suffers from mode collapse and uncovers a previously overlooked phenomenon: the progressive loss of neural plasticity in the model, which is compounded by inefficient credit assignment in sequential prompt generation. To address this critical challenge, we develop a systematic approach in PAG with flow reactivation, reward-prioritized sampling, and reward decomposition for prompt adaptation. Extensive experiments validate that PAG successfully learns to sample effective and diverse prompts for text-to-image generation. We also show that PAG exhibits strong robustness across various reward functions and transferability to different text-to-image models.
No Trick, No Treat: Pursuits and Challenges Towards Simulation-free Training of Neural Samplers
Feb 10, 2025



We consider the sampling problem, where the aim is to draw samples from a distribution whose density is known only up to a normalization constant. Recent breakthroughs in generative modeling to approximate a high-dimensional data distribution have sparked significant interest in developing neural network-based methods for this challenging problem. However, neural samplers typically incur heavy computational overhead due to simulating trajectories during training. This motivates the pursuit of simulation-free training procedures of neural samplers. In this work, we propose an elegant modification to previous methods, which allows simulation-free training with the help of a time-dependent normalizing flow. However, it ultimately suffers from severe mode collapse. On closer inspection, we find that nearly all successful neural samplers rely on Langevin preconditioning to avoid mode collapsing. We systematically analyze several popular methods with various objective functions and demonstrate that, in the absence of Langevin preconditioning, most of them fail to adequately cover even a simple target. Finally, we draw attention to a strong baseline by combining the state-of-the-art MCMC method, Parallel Tempering (PT), with an additional generative model to shed light on future explorations of neural samplers.
Efficient Diversity-Preserving Diffusion Alignment via Gradient-Informed GFlowNets
Dec 10, 2024While one commonly trains large diffusion models by collecting datasets on target downstream tasks, it is often desired to align and finetune pretrained diffusion models on some reward functions that are either designed by experts or learned from small-scale datasets. Existing methods for finetuning diffusion models typically suffer from lack of diversity in generated samples, lack of prior preservation, and/or slow convergence in finetuning. Inspired by recent successes in generative flow networks (GFlowNets), a class of probabilistic models that sample with the unnormalized density of a reward function, we propose a novel GFlowNet method dubbed Nabla-GFlowNet (abbreviated as $\nabla$-GFlowNet), the first GFlowNet method that leverages the rich signal in reward gradients, together with an objective called $\nabla$-DB plus its variant residual $\nabla$-DB designed for prior-preserving diffusion alignment. We show that our proposed method achieves fast yet diversity- and prior-preserving alignment of Stable Diffusion, a large-scale text-conditioned image diffusion model, on different realistic reward functions.
DODT: Enhanced Online Decision Transformer Learning through Dreamer's Actor-Critic Trajectory Forecasting
Oct 15, 2024
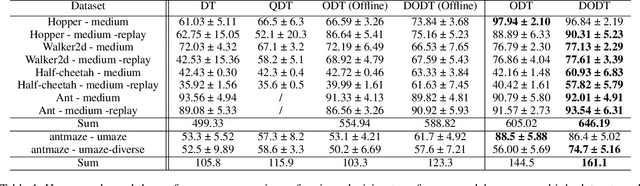
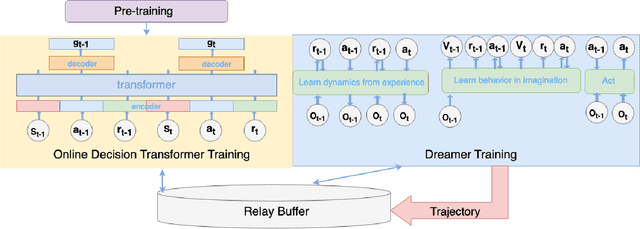
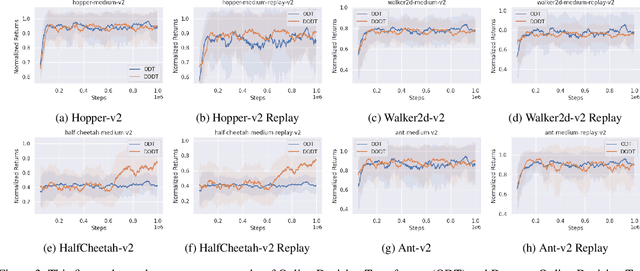
Advancements in reinforcement learning have led to the development of sophisticated models capable of learning complex decision-making tasks. However, efficiently integrating world models with decision transformers remains a challenge. In this paper, we introduce a novel approach that combines the Dreamer algorithm's ability to generate anticipatory trajectories with the adaptive learning strengths of the Online Decision Transformer. Our methodology enables parallel training where Dreamer-produced trajectories enhance the contextual decision-making of the transformer, creating a bidirectional enhancement loop. We empirically demonstrate the efficacy of our approach on a suite of challenging benchmarks, achieving notable improvements in sample efficiency and reward maximization over existing methods. Our results indicate that the proposed integrated framework not only accelerates learning but also showcases robustness in diverse and dynamic scenarios, marking a significant step forward in model-based reinforcement learning.