 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing TableQA through Verifiable Reasoning Trace Reward
Jan 30, 2026A major challenge in training TableQA agents, compared to standard text- and image-based agents, is that answers cannot be inferred from a static input but must be reasoned through stepwise transformations of the table state, introducing multi-step reasoning complexity and environmental interaction. This leads to a research question: Can explicit feedback on table transformation action improve model reasoning capability? In this work, we introduce RE-Tab, a plug-and-play framework that architecturally enhances trajectory search via lightweight, training-free reward modeling by formulating the problem as a Partially Observable Markov Decision Process. We demonstrate that providing explicit verifiable rewards during State Transition (``What is the best action?'') and Simulative Reasoning (``Am I sure about the output?'') is crucial to steer the agent's navigation in table states. By enforcing stepwise reasoning with reward feedback in table transformations, RE-Tab achieves state-of-the-art performance in TableQA with almost 25\% drop in inference cost. Furthermore, a direct plug-and-play implementation of RE-Tab brings up to 41.77% improvement in QA accuracy and 33.33% drop in test-time inference samples for consistent answer. Consistent improvement pattern across various LLMs and state-of-the-art benchmarks further confirms RE-Tab's generalisability. The repository is available at https://github.com/ThomasK1018/RE_Tab .
A Probabilistic Perspective on Model Collapse
May 20, 2025In recent years, model collapse has become a critical issue in language model training, making it essential to understand the underlying mechanisms driving this phenomenon. In this paper, we investigate recursive parametric model training from a probabilistic perspective, aiming to characterize the conditions under which model collapse occurs and, crucially, how it can be mitigated. We conceptualize the recursive training process as a random walk of the model estimate, highlighting how the sample size influences the step size and how the estimation procedure determines the direction and potential bias of the random walk. Under mild conditions, we rigorously show that progressively increasing the sample size at each training step is necessary to prevent model collapse. In particular, when the estimation is unbiased, the required growth rate follows a superlinear pattern. This rate needs to be accelerated even further in the presence of substantial estimation bias. Building on this probabilistic framework, we also investigate the probability that recursive training on synthetic data yields models that outperform those trained solely on real data. Moreover, we extend these results to general parametric model family in an asymptotic regime. Finally, we validate our theoretical results through extensive simulations and a real-world dataset.
Golden Ratio Mixing of Real and Synthetic Data for Stabilizing Generative Model Training
Feb 25, 2025Recent studies identified an intriguing phenomenon in recursive generative model training known as model collapse, where models trained on data generated by previous models exhibit severe performance degradation. Addressing this issue and developing more effective training strategies have become central challenges in generative model research. In this paper, we investigate this phenomenon theoretically within a novel framework, where generative models are iteratively trained on a combination of newly collected real data and synthetic data from the previous training step. To develop an optimal training strategy for integrating real and synthetic data, we evaluate the performance of a weighted training scheme in various scenarios, including Gaussian distribution estimation and linear regression. We theoretically characterize the impact of the mixing proportion and weighting scheme of synthetic data on the final model's performance. Our key finding is that, across different settings, the optimal weighting scheme under different proportions of synthetic data asymptotically follows a unified expression, revealing a fundamental trade-off between leveraging synthetic data and generative model performance. Notably, in some cases, the optimal weight assigned to real data corresponds precisely to the reciprocal of the golden ratio. Finally, we validate our theoretical results on extensive simulated datasets and a real tabular dataset.
Watermarking Generative Categorical Data
Nov 16, 2024
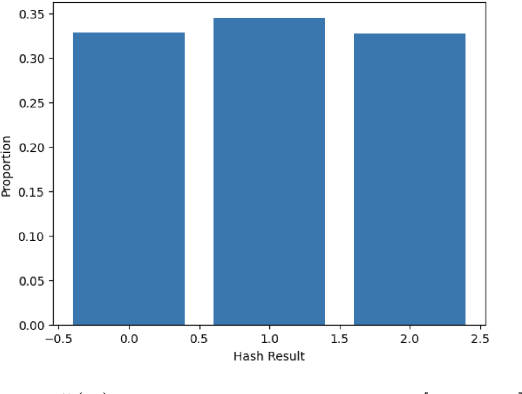
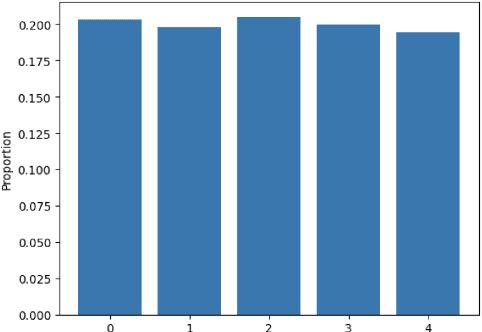
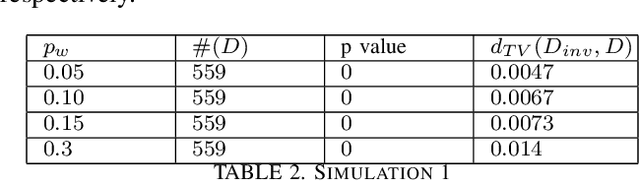
In this paper, we propose a novel statistical framework for watermarking generative categorical data. Our method systematically embeds pre-agreed secret signals by splitting the data distribution into two components and modifying one distribution based on a deterministic relationship with the other, ensuring the watermark is embedded at the distribution-level. To verify the watermark, we introduce an insertion inverse algorithm and detect its presence by measuring the total variation distance between the inverse-decoded data and the original distribution. Unlike previous categorical watermarking methods, which primarily focus on embedding watermarks into a given dataset, our approach operates at the distribution-level, allowing for verification from a statistical distributional perspective. This makes it particularly well-suited for the modern paradigm of synthetic data generation, where the underlying data distribution, rather than specific data points, is of primary importance. The effectiveness of our method is demonstrated through both theoretical analysis and empirical validation.
Latent Energy-Based Odyssey: Black-Box Optimization via Expanded Exploration in the Energy-Based Latent Space
May 27, 2024Offline Black-Box Optimization (BBO) aims at optimizing a black-box function using the knowledge from a pre-collected offline dataset of function values and corresponding input designs. However, the high-dimensional and highly-multimodal input design space of black-box function pose inherent challenges for most existing methods that model and operate directly upon input designs. These issues include but are not limited to high sample complexity, which relates to inaccurate approximation of black-box function; and insufficient coverage and exploration of input design modes, which leads to suboptimal proposal of new input designs. In this work, we consider finding a latent space that serves as a compressed yet accurate representation of the design-value joint space, enabling effective latent exploration of high-value input design modes. To this end, we formulate an learnable energy-based latent space, and propose Noise-intensified Telescoping density-Ratio Estimation (NTRE) scheme for variational learning of an accurate latent space model without costly Markov Chain Monte Carlo. The optimization process is then exploration of high-value designs guided by the learned energy-based model in the latent space, formulated as gradient-based sampling from a latent-variable-parameterized inverse model. We show that our particular parameterization encourages expanded exploration around high-value design modes, motivated by inversion thinking of a fundamental result of conditional covariance matrix typically used for variance reduction. We observe that our method, backed by an accurately learned informative latent space and an expanding-exploration model design, yields significant improvements over strong previous methods on both synthetic and real world datasets such as the design-bench suite.
Watermarking Generative Tabular Data
May 22, 2024



In this paper, we introduce a simple yet effective tabular data watermarking mechanism with statistical guarantees. We show theoretically that the proposed watermark can be effectively detected, while faithfully preserving the data fidelity, and also demonstrates appealing robustness against additive noise attack. The general idea is to achieve the watermarking through a strategic embedding based on simple data binning. Specifically, it divides the feature's value range into finely segmented intervals and embeds watermarks into selected ``green list" intervals. To detect the watermarks, we develop a principled statistical hypothesis-testing framework with minimal assumptions: it remains valid as long as the underlying data distribution has a continuous density function. The watermarking efficacy is demonstrated through rigorous theoretical analysis and empirical validation, highlighting its utility in enhancing the security of synthetic and real-world datasets.
An ODE Model for Dynamic Matching in Heterogeneous Networks
Mar 08, 2023



We study the problem of dynamic matching in heterogeneous networks, where agents are subject to compatibility restrictions and stochastic arrival and departure times. In particular, we consider networks with one type of easy-to-match agents and multiple types of hard-to-match agents, each subject to its own compatibility constraints. Such a setting arises in many real-world applications, including kidney exchange programs and carpooling platforms. We introduce a novel approach to modeling dynamic matching by establishing the ordinary differential equation (ODE) model, which offers a new perspective for evaluating various matching algorithms. We study two algorithms, namely the Greedy and Patient Algorithms, where both algorithms prioritize matching compatible hard-to-match agents over easy-to-match agents in heterogeneous networks. Our results demonstrate the trade-off between the conflicting goals of matching agents quickly and optimally, offering insights into the design of real-world dynamic matching systems. We provide simulations and a real-world case study using data from the Organ Procurement and Transplantation Network to validate theoretical predictions.