 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatermarking Generative Categorical Data
Paper and Code
Nov 16, 2024
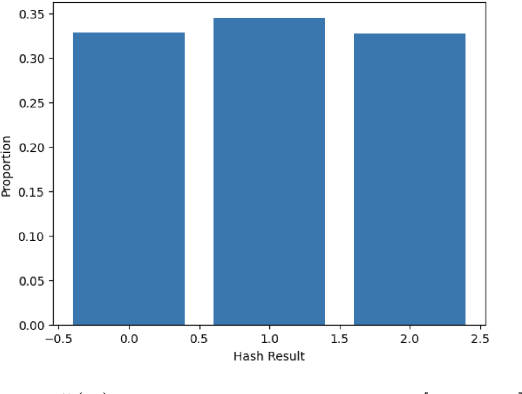
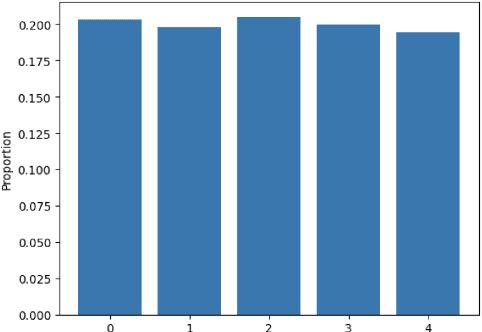
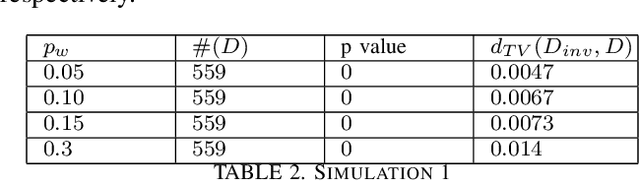
In this paper, we propose a novel statistical framework for watermarking generative categorical data. Our method systematically embeds pre-agreed secret signals by splitting the data distribution into two components and modifying one distribution based on a deterministic relationship with the other, ensuring the watermark is embedded at the distribution-level. To verify the watermark, we introduce an insertion inverse algorithm and detect its presence by measuring the total variation distance between the inverse-decoded data and the original distribution. Unlike previous categorical watermarking methods, which primarily focus on embedding watermarks into a given dataset, our approach operates at the distribution-level, allowing for verification from a statistical distributional perspective. This makes it particularly well-suited for the modern paradigm of synthetic data generation, where the underlying data distribution, rather than specific data points, is of primary importance. The effectiveness of our method is demonstrated through both theoretical analysis and empirical validation.