 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Cross-Problem Vehicle Routing via Federated Learning
Apr 12, 2026Vehicle routing problems (VRPs) constitute a core optimization challenge in modern logistics and supply chain management. The recent neural combinatorial optimization (NCO) has demonstrated superior efficiency over some traditional algorithms. While serving as a primary NCO approach for solving general VRPs, current cross-problem learning paradigms are still subject to performance degradation and generalizability decay, when transferring from simple VRP variants to those involving different and complex constraints. To strengthen the paradigms, this paper offers an innovative "Multi-problem Pre-train, then Single-problem Fine-tune" framework with Federated Learning (MPSF-FL). This framework exploits the common knowledge of a federated global model to foster efficient cross-problem knowledge sharing and transfer among local models for single-problem fine-tuning. In this way, local models effectively retain common VRP knowledge from up-to-date global model, while being efficiently adapted to downstream VRPs with heterogeneous complex constraints. Experimental results demonstrate that our framework not only enhances the performance in diverse VRPs, but also improves the generalizability in unseen problems.
AsyncTLS: Efficient Generative LLM Inference with Asynchronous Two-level Sparse Attention
Apr 09, 2026Long-context inference in LLMs faces the dual challenges of quadratic attention complexity and prohibitive KV cache memory. While token-level sparse attention offers superior accuracy, its indexing overhead is costly; block-level methods improve efficiency but sacrifice precision. We propose AsyncTLS, a hierarchical sparse attention system that combines coarse-grained block filtering with fine-grained token selection to balance accuracy and efficiency, coupled with an asynchronous offloading engine that overlaps KV cache transfers with computation via temporal locality exploitation. Evaluated on Qwen3 and GLM-4.7-Flash across GQA, and MLA architectures, AsyncTLS achieves accuracy comparable to full attention while delivering 1.2x - 10.0x operator speedups and 1.3x - 4.7x end-to-end throughput improvements on 48k - 96k contexts.
GRASP: Gradient Realignment via Active Shared Perception for Multi-Agent Collaborative Optimization
Apr 01, 2026Non-stationarity arises from concurrent policy updates and leads to persistent environmental fluctuations. Existing approaches like Centralized Training with Decentralized Execution (CTDE) and sequential update schemes mitigate this issue. However, since the perception of the policies of other agents remains dependent on sampling environmental interaction data, the agent essentially operates in a passive perception state. This inevitably triggers equilibrium oscillations and significantly slows the convergence speed of the system. To address this issue, we propose Gradient Realignment via Active Shared Perception (GRASP), a novel framework that defines generalized Bellman equilibrium as a stable objective for policy evolution. The core mechanism of GRASP involves utilizing the independent gradients of agents to derive a defined consensus gradient, enabling agents to actively perceive policy updates and optimize team collaboration. Theoretically, we leverage the Kakutani Fixed-Point Theorem to prove that the consensus direction $u^*$ guarantees the existence and attainability of this equilibrium. Extensive experiments on StarCraft II Multi-Agent Challenge (SMAC) and Google Research Football (GRF) demonstrate the scalability and promising performance of the framework.
LongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Efficient Context Scaling with LongCat ZigZag Attention
Dec 30, 2025We introduce LongCat ZigZag Attention (LoZA), which is a sparse attention scheme designed to transform any existing full-attention models into sparse versions with rather limited compute budget. In long-context scenarios, LoZA can achieve significant speed-ups both for prefill-intensive (e.g., retrieval-augmented generation) and decode-intensive (e.g., tool-integrated reasoning) cases. Specifically, by applying LoZA to LongCat-Flash during mid-training, we serve LongCat-Flash-Exp as a long-context foundation model that can swiftly process up to 1 million tokens, enabling efficient long-term reasoning and long-horizon agentic capabilities.
ChronoEdit: Towards Temporal Reasoning for Image Editing and World Simulation
Oct 05, 2025Recent advances in large generative models have significantly advanced image editing and in-context image generation, yet a critical gap remains in ensuring physical consistency, where edited objects must remain coherent. This capability is especially vital for world simulation related tasks. In this paper, we present ChronoEdit, a framework that reframes image editing as a video generation problem. First, ChronoEdit treats the input and edited images as the first and last frames of a video, allowing it to leverage large pretrained video generative models that capture not only object appearance but also the implicit physics of motion and interaction through learned temporal consistency. Second, ChronoEdit introduces a temporal reasoning stage that explicitly performs editing at inference time. Under this setting, the target frame is jointly denoised with reasoning tokens to imagine a plausible editing trajectory that constrains the solution space to physically viable transformations. The reasoning tokens are then dropped after a few steps to avoid the high computational cost of rendering a full video. To validate ChronoEdit, we introduce PBench-Edit, a new benchmark of image-prompt pairs for contexts that require physical consistency, and demonstrate that ChronoEdit surpasses state-of-the-art baselines in both visual fidelity and physical plausibility. Code and models for both the 14B and 2B variants of ChronoEdit will be released on the project page: https://research.nvidia.com/labs/toronto-ai/chronoedit
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
Cosmos-Drive-Dreams: Scalable Synthetic Driving Data Generation with World Foundation Models
Jun 11, 2025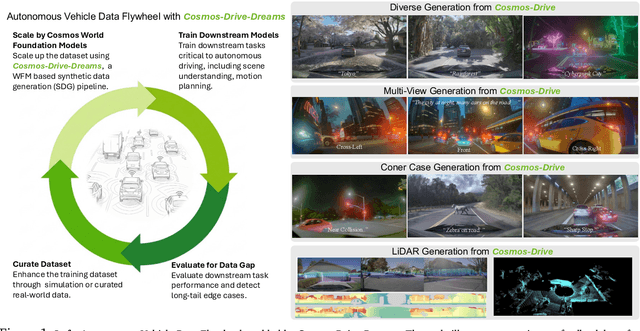
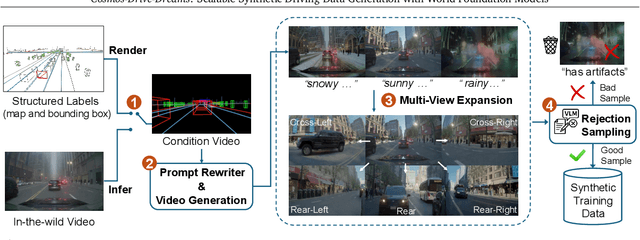
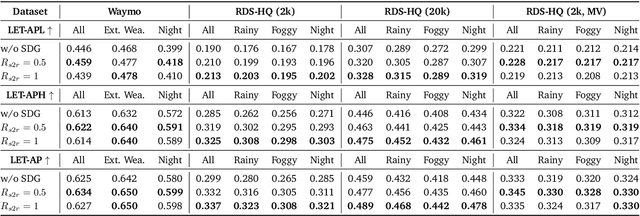
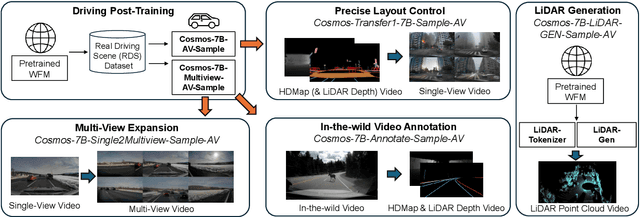
Collecting and annotating real-world data for safety-critical physical AI systems, such as Autonomous Vehicle (AV), is time-consuming and costly. It is especially challenging to capture rare edge cases, which play a critical role in training and testing of an AV system. To address this challenge, we introduce the Cosmos-Drive-Dreams - a synthetic data generation (SDG) pipeline that aims to generate challenging scenarios to facilitate downstream tasks such as perception and driving policy training. Powering this pipeline is Cosmos-Drive, a suite of models specialized from NVIDIA Cosmos world foundation model for the driving domain and are capable of controllable, high-fidelity, multi-view, and spatiotemporally consistent driving video generation. We showcase the utility of these models by applying Cosmos-Drive-Dreams to scale the quantity and diversity of driving datasets with high-fidelity and challenging scenarios. Experimentally, we demonstrate that our generated data helps in mitigating long-tail distribution problems and enhances generalization in downstream tasks such as 3D lane detection, 3D object detection and driving policy learning. We open source our pipeline toolkit, dataset and model weights through the NVIDIA's Cosmos platform. Project page: https://research.nvidia.com/labs/toronto-ai/cosmos_drive_dreams
Deep Learning Reforms Image Matching: A Survey and Outlook
Jun 05, 2025Image matching, which establishes correspondences between two-view images to recover 3D structure and camera geometry, serves as a cornerstone in computer vision and underpins a wide range of applications, including visual localization, 3D reconstruction, and simultaneous localization and mapping (SLAM). Traditional pipelines composed of ``detector-descriptor, feature matcher, outlier filter, and geometric estimator'' falter in challenging scenarios. Recent deep-learning advances have significantly boosted both robustness and accuracy. This survey adopts a unique perspective by comprehensively reviewing how deep learning has incrementally transformed the classical image matching pipeline. Our taxonomy highly aligns with the traditional pipeline in two key aspects: i) the replacement of individual steps in the traditional pipeline with learnable alternatives, including learnable detector-descriptor, outlier filter, and geometric estimator; and ii) the merging of multiple steps into end-to-end learnable modules, encompassing middle-end sparse matcher, end-to-end semi-dense/dense matcher, and pose regressor. We first examine the design principles, advantages, and limitations of both aspects, and then benchmark representative methods on relative pose recovery, homography estimation, and visual localization tasks. Finally, we discuss open challenges and outline promising directions for future research. By systematically categorizing and evaluating deep learning-driven strategies, this survey offers a clear overview of the evolving image matching landscape and highlights key avenues for further innovation.