 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmboCoach-Bench: Benchmarking AI Agents on Developing Embodied Robots
Jan 29, 2026The field of Embodied AI is witnessing a rapid evolution toward general-purpose robotic systems, fueled by high-fidelity simulation and large-scale data collection. However, this scaling capability remains severely bottlenecked by a reliance on labor-intensive manual oversight from intricate reward shaping to hyperparameter tuning across heterogeneous backends. Inspired by LLMs' success in software automation and science discovery, we introduce \textsc{EmboCoach-Bench}, a benchmark evaluating the capacity of LLM agents to autonomously engineer embodied policies. Spanning 32 expert-curated RL and IL tasks, our framework posits executable code as the universal interface. We move beyond static generation to assess a dynamic closed-loop workflow, where agents leverage environment feedback to iteratively draft, debug, and optimize solutions, spanning improvements from physics-informed reward design to policy architectures such as diffusion policies. Extensive evaluations yield three critical insights: (1) autonomous agents can qualitatively surpass human-engineered baselines by 26.5\% in average success rate; (2) agentic workflow with environment feedback effectively strengthens policy development and substantially narrows the performance gap between open-source and proprietary models; and (3) agents exhibit self-correction capabilities for pathological engineering cases, successfully resurrecting task performance from near-total failures through iterative simulation-in-the-loop debugging. Ultimately, this work establishes a foundation for self-evolving embodied intelligence, accelerating the paradigm shift from labor-intensive manual tuning to scalable, autonomous engineering in embodied AI field.
$G^2$-Reader: Dual Evolving Graphs for Multimodal Document QA
Jan 29, 2026Retrieval-augmented generation is a practical paradigm for question answering over long documents, but it remains brittle for multimodal reading where text, tables, and figures are interleaved across many pages. First, flat chunking breaks document-native structure and cross-modal alignment, yielding semantic fragments that are hard to interpret in isolation. Second, even iterative retrieval can fail in long contexts by looping on partial evidence or drifting into irrelevant sections as noise accumulates, since each step is guided only by the current snippet without a persistent global search state. We introduce $G^2$-Reader, a dual-graph system, to address both issues. It evolves a Content Graph to preserve document-native structure and cross-modal semantics, and maintains a Planning Graph, an agentic directed acyclic graph of sub-questions, to track intermediate findings and guide stepwise navigation for evidence completion. On VisDoMBench across five multimodal domains, $G^2$-Reader with Qwen3-VL-32B-Instruct reaches 66.21\% average accuracy, outperforming strong baselines and a standalone GPT-5 (53.08\%).
AgentIF-OneDay: A Task-level Instruction-Following Benchmark for General AI Agents in Daily Scenarios
Jan 28, 2026The capacity of AI agents to effectively handle tasks of increasing duration and complexity continues to grow, demonstrating exceptional performance in coding, deep research, and complex problem-solving evaluations. However, in daily scenarios, the perception of these advanced AI capabilities among general users remains limited. We argue that current evaluations prioritize increasing task difficulty without sufficiently addressing the diversity of agentic tasks necessary to cover the daily work, life, and learning activities of a broad demographic. To address this, we propose AgentIF-OneDay, aimed at determining whether general users can utilize natural language instructions and AI agents to complete a diverse array of daily tasks. These tasks require not only solving problems through dialogue but also understanding various attachment types and delivering tangible file-based results. The benchmark is structured around three user-centric categories: Open Workflow Execution, which assesses adherence to explicit and complex workflows; Latent Instruction, which requires agents to infer implicit instructions from attachments; and Iterative Refinement, which involves modifying or expanding upon ongoing work. We employ instance-level rubrics and a refined evaluation pipeline that aligns LLM-based verification with human judgment, achieving an 80.1% agreement rate using Gemini-3-Pro. AgentIF-OneDay comprises 104 tasks covering 767 scoring points. We benchmarked four leading general AI agents and found that agent products built based on APIs and ChatGPT agents based on agent RL remain in the first tier simultaneously. Leading LLM APIs and open-source models have internalized agentic capabilities, enabling AI application teams to develop cutting-edge Agent products.
Toward Efficient Agents: Memory, Tool learning, and Planning
Jan 20, 2026Recent years have witnessed increasing interest in extending large language models into agentic systems. While the effectiveness of agents has continued to improve, efficiency, which is crucial for real-world deployment, has often been overlooked. This paper therefore investigates efficiency from three core components of agents: memory, tool learning, and planning, considering costs such as latency, tokens, steps, etc. Aimed at conducting comprehensive research addressing the efficiency of the agentic system itself, we review a broad range of recent approaches that differ in implementation yet frequently converge on shared high-level principles including but not limited to bounding context via compression and management, designing reinforcement learning rewards to minimize tool invocation, and employing controlled search mechanisms to enhance efficiency, which we discuss in detail. Accordingly, we characterize efficiency in two complementary ways: comparing effectiveness under a fixed cost budget, and comparing cost at a comparable level of effectiveness. This trade-off can also be viewed through the Pareto frontier between effectiveness and cost. From this perspective, we also examine efficiency oriented benchmarks by summarizing evaluation protocols for these components and consolidating commonly reported efficiency metrics from both benchmark and methodological studies. Moreover, we discuss the key challenges and future directions, with the goal of providing promising insights.
Toward Ultra-Long-Horizon Agentic Science: Cognitive Accumulation for Machine Learning Engineering
Jan 15, 2026The advancement of artificial intelligence toward agentic science is currently bottlenecked by the challenge of ultra-long-horizon autonomy, the ability to sustain strategic coherence and iterative correction over experimental cycles spanning days or weeks. While Large Language Models (LLMs) have demonstrated prowess in short-horizon reasoning, they are easily overwhelmed by execution details in the high-dimensional, delayed-feedback environments of real-world research, failing to consolidate sparse feedback into coherent long-term guidance. Here, we present ML-Master 2.0, an autonomous agent that masters ultra-long-horizon machine learning engineering (MLE) which is a representative microcosm of scientific discovery. By reframing context management as a process of cognitive accumulation, our approach introduces Hierarchical Cognitive Caching (HCC), a multi-tiered architecture inspired by computer systems that enables the structural differentiation of experience over time. By dynamically distilling transient execution traces into stable knowledge and cross-task wisdom, HCC allows agents to decouple immediate execution from long-term experimental strategy, effectively overcoming the scaling limits of static context windows. In evaluations on OpenAI's MLE-Bench under 24-hour budgets, ML-Master 2.0 achieves a state-of-the-art medal rate of 56.44%. Our findings demonstrate that ultra-long-horizon autonomy provides a scalable blueprint for AI capable of autonomous exploration beyond human-precedent complexities.
Deploy-Master: Automating the Deployment of 50,000+ Agent-Ready Scientific Tools in One Day
Jan 07, 2026Open-source scientific software is abundant, yet most tools remain difficult to compile, configure, and reuse, sustaining a small-workshop mode of scientific computing. This deployment bottleneck limits reproducibility, large-scale evaluation, and the practical integration of scientific tools into modern AI-for-Science (AI4S) and agentic workflows. We present Deploy-Master, a one-stop agentic workflow for large-scale tool discovery, build specification inference, execution-based validation, and publication. Guided by a taxonomy spanning 90+ scientific and engineering domains, our discovery stage starts from a recall-oriented pool of over 500,000 public repositories and progressively filters it to 52,550 executable tool candidates under license- and quality-aware criteria. Deploy-Master transforms heterogeneous open-source repositories into runnable, containerized capabilities grounded in execution rather than documentation claims. In a single day, we performed 52,550 build attempts and constructed reproducible runtime environments for 50,112 scientific tools. Each successful tool is validated by a minimal executable command and registered in SciencePedia for search and reuse, enabling direct human use and optional agent-based invocation. Beyond delivering runnable tools, we report a deployment trace at the scale of 50,000 tools, characterizing throughput, cost profiles, failure surfaces, and specification uncertainty that become visible only at scale. These results explain why scientific software remains difficult to operationalize and motivate shared, observable execution substrates as a foundation for scalable AI4S and agentic science.
Bohrium + SciMaster: Building the Infrastructure and Ecosystem for Agentic Science at Scale
Dec 23, 2025



AI agents are emerging as a practical way to run multi-step scientific workflows that interleave reasoning with tool use and verification, pointing to a shift from isolated AI-assisted steps toward \emph{agentic science at scale}. This shift is increasingly feasible, as scientific tools and models can be invoked through stable interfaces and verified with recorded execution traces, and increasingly necessary, as AI accelerates scientific output and stresses the peer-review and publication pipeline, raising the bar for traceability and credible evaluation. However, scaling agentic science remains difficult: workflows are hard to observe and reproduce; many tools and laboratory systems are not agent-ready; execution is hard to trace and govern; and prototype AI Scientist systems are often bespoke, limiting reuse and systematic improvement from real workflow signals. We argue that scaling agentic science requires an infrastructure-and-ecosystem approach, instantiated in Bohrium+SciMaster. Bohrium acts as a managed, traceable hub for AI4S assets -- akin to a HuggingFace of AI for Science -- that turns diverse scientific data, software, compute, and laboratory systems into agent-ready capabilities. SciMaster orchestrates these capabilities into long-horizon scientific workflows, on which scientific agents can be composed and executed. Between infrastructure and orchestration, a \emph{scientific intelligence substrate} organizes reusable models, knowledge, and components into executable building blocks for workflow reasoning and action, enabling composition, auditability, and improvement through use. We demonstrate this stack with eleven representative master agents in real workflows, achieving orders-of-magnitude reductions in end-to-end scientific cycle time and generating execution-grounded signals from real workloads at multi-million scale.
PhysMaster: Building an Autonomous AI Physicist for Theoretical and Computational Physics Research
Dec 22, 2025Advances in LLMs have produced agents with knowledge and operational capabilities comparable to human scientists, suggesting potential to assist, accelerate, and automate research. However, existing studies mainly evaluate such systems on well-defined benchmarks or general tasks like literature retrieval, limiting their end-to-end problem-solving ability in open scientific scenarios. This is particularly true in physics, which is abstract, mathematically intensive, and requires integrating analytical reasoning with code-based computation. To address this, we propose PhysMaster, an LLM-based agent functioning as an autonomous theoretical and computational physicist. PhysMaster couples absract reasoning with numerical computation and leverages LANDAU, the Layered Academic Data Universe, which preserves retrieved literature, curated prior knowledge, and validated methodological traces, enhancing decision reliability and stability. It also employs an adaptive exploration strategy balancing efficiency and open-ended exploration, enabling robust performance in ultra-long-horizon tasks. We evaluate PhysMaster on problems from high-energy theory, condensed matter theory to astrophysics, including: (i) acceleration, compressing labor-intensive research from months to hours; (ii) automation, autonomously executing hypothesis-driven loops ; and (iii) autonomous discovery, independently exploring open problems.
Unveiling the Impact of Data and Model Scaling on High-Level Control for Humanoid Robots
Nov 12, 2025
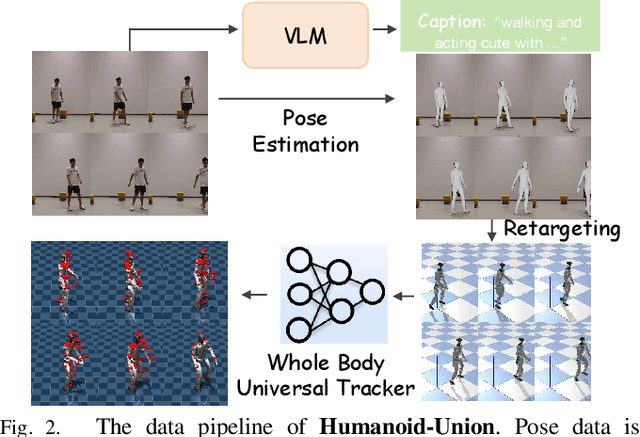
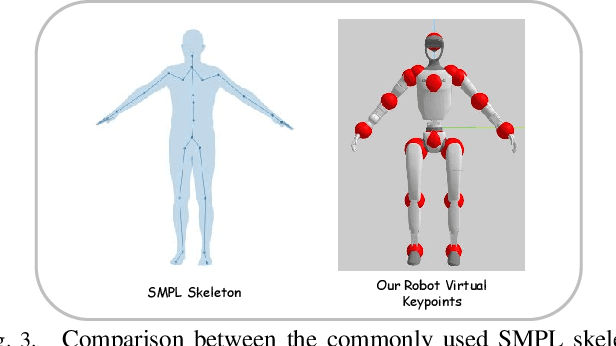
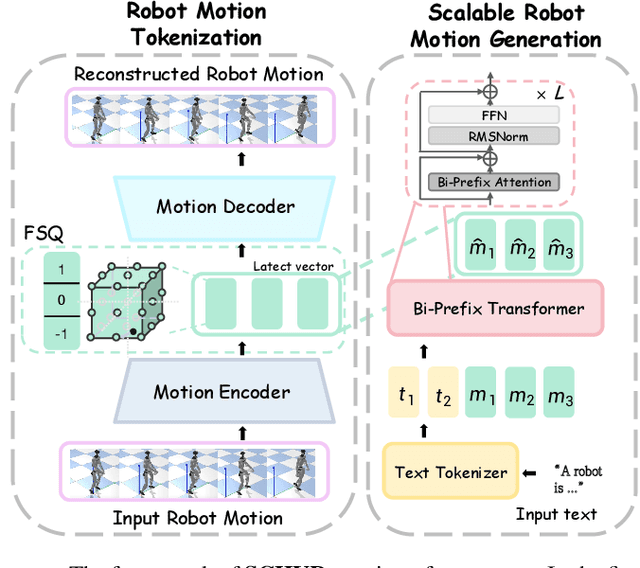
Data scaling has long remained a critical bottleneck in robot learning. For humanoid robots, human videos and motion data are abundant and widely available, offering a free and large-scale data source. Besides, the semantics related to the motions enable modality alignment and high-level robot control learning. However, how to effectively mine raw video, extract robot-learnable representations, and leverage them for scalable learning remains an open problem. To address this, we introduce Humanoid-Union, a large-scale dataset generated through an autonomous pipeline, comprising over 260 hours of diverse, high-quality humanoid robot motion data with semantic annotations derived from human motion videos. The dataset can be further expanded via the same pipeline. Building on this data resource, we propose SCHUR, a scalable learning framework designed to explore the impact of large-scale data on high-level control in humanoid robots. Experimental results demonstrate that SCHUR achieves high robot motion generation quality and strong text-motion alignment under data and model scaling, with 37\% reconstruction improvement under MPJPE and 25\% alignment improvement under FID comparing with previous methods. Its effectiveness is further validated through deployment in real-world humanoid robot.
InfoMosaic-Bench: Evaluating Multi-Source Information Seeking in Tool-Augmented Agents
Oct 02, 2025Information seeking is a fundamental requirement for humans. However, existing LLM agents rely heavily on open-web search, which exposes two fundamental weaknesses: online content is noisy and unreliable, and many real-world tasks require precise, domain-specific knowledge unavailable from the web. The emergence of the Model Context Protocol (MCP) now allows agents to interface with thousands of specialized tools, seemingly resolving this limitation. Yet it remains unclear whether agents can effectively leverage such tools -- and more importantly, whether they can integrate them with general-purpose search to solve complex tasks. Therefore, we introduce InfoMosaic-Bench, the first benchmark dedicated to multi-source information seeking in tool-augmented agents. Covering six representative domains (medicine, finance, maps, video, web, and multi-domain integration), InfoMosaic-Bench requires agents to combine general-purpose search with domain-specific tools. Tasks are synthesized with InfoMosaic-Flow, a scalable pipeline that grounds task conditions in verified tool outputs, enforces cross-source dependencies, and filters out shortcut cases solvable by trivial lookup. This design guarantees both reliability and non-triviality. Experiments with 14 state-of-the-art LLM agents reveal three findings: (i) web information alone is insufficient, with GPT-5 achieving only 38.2% accuracy and 67.5% pass rate; (ii) domain tools provide selective but inconsistent benefits, improving some domains while degrading others; and (iii) 22.4% of failures arise from incorrect tool usage or selection, highlighting that current LLMs still struggle with even basic tool handling.