 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution
Oct 29, 2025Real-world language agents must handle complex, multi-step workflows across diverse Apps. For instance, an agent may manage emails by coordinating with calendars and file systems, or monitor a production database to detect anomalies and generate reports following an operating manual. However, existing language agent benchmarks often focus on narrow domains or simplified tasks that lack the diversity, realism, and long-horizon complexity required to evaluate agents' real-world performance. To address this gap, we introduce the Tool Decathlon (dubbed as Toolathlon), a benchmark for language agents offering diverse Apps and tools, realistic environment setup, and reliable execution-based evaluation. Toolathlon spans 32 software applications and 604 tools, ranging from everyday platforms such as Google Calendar and Notion to professional ones like WooCommerce, Kubernetes, and BigQuery. Most of the tools are based on a high-quality set of Model Context Protocol (MCP) servers that we may have revised or implemented ourselves. Unlike prior works, which primarily ensure functional realism but offer limited environment state diversity, we provide realistic initial environment states from real software, such as Canvas courses with dozens of students or real financial spreadsheets. This benchmark includes 108 manually sourced or crafted tasks in total, requiring interacting with multiple Apps over around 20 turns on average to complete. Each task is strictly verifiable through dedicated evaluation scripts. Comprehensive evaluation of SOTA models highlights their significant shortcomings: the best-performing model, Claude-4.5-Sonnet, achieves only a 38.6% success rate with 20.2 tool calling turns on average, while the top open-weights model DeepSeek-V3.2-Exp reaches 20.1%. We expect Toolathlon to drive the development of more capable language agents for real-world, long-horizon task execution.
Scaling Speculative Decoding with Lookahead Reasoning
Jun 24, 2025Reasoning models excel by generating long chain-of-thoughts, but decoding the resulting thousands of tokens is slow. Token-level speculative decoding (SD) helps, but its benefit is capped, because the chance that an entire $\gamma$-token guess is correct falls exponentially as $\gamma$ grows. This means allocating more compute for longer token drafts faces an algorithmic ceiling -- making the speedup modest and hardware-agnostic. We raise this ceiling with Lookahead Reasoning, which exploits a second, step-level layer of parallelism. Our key insight is that reasoning models generate step-by-step, and each step needs only to be semantically correct, not exact token matching. In Lookahead Reasoning, a lightweight draft model proposes several future steps; the target model expands each proposal in one batched pass, and a verifier keeps semantically correct steps while letting the target regenerate any that fail. Token-level SD still operates within each reasoning step, so the two layers of parallelism multiply. We show Lookahead Reasoning lifts the peak speedup of SD both theoretically and empirically. Across GSM8K, AIME, and other benchmarks, Lookahead Reasoning improves the speedup of SD from 1.4x to 2.1x while preserving answer quality, and its speedup scales better with additional GPU throughput. Our code is available at https://github.com/hao-ai-lab/LookaheadReasoning
MAS-GPT: Training LLMs to Build LLM-based Multi-Agent Systems
Mar 05, 2025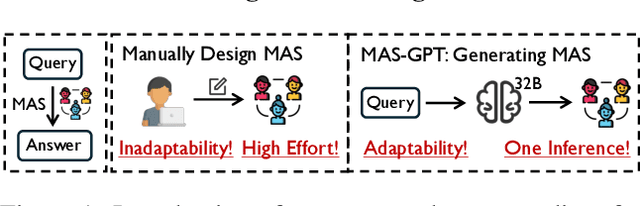

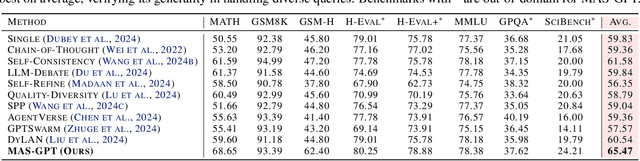
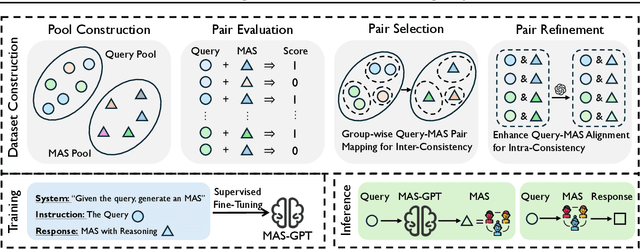
LLM-based multi-agent systems (MAS) have shown significant potential in tackling diverse tasks. However, to design effective MAS, existing approaches heavily rely on manual configurations or multiple calls of advanced LLMs, resulting in inadaptability and high inference costs. In this paper, we simplify the process of building an MAS by reframing it as a generative language task, where the input is a user query and the output is a corresponding MAS. To address this novel task, we unify the representation of MAS as executable code and propose a consistency-oriented data construction pipeline to create a high-quality dataset comprising coherent and consistent query-MAS pairs. Using this dataset, we train MAS-GPT, an open-source medium-sized LLM that is capable of generating query-adaptive MAS within a single LLM inference. The generated MAS can be seamlessly applied to process user queries and deliver high-quality responses. Extensive experiments on 9 benchmarks and 5 LLMs show that the proposed MAS-GPT consistently outperforms 10+ baseline MAS methods on diverse settings, indicating MAS-GPT's high effectiveness, efficiency and strong generalization ability. Code will be available at https://github.com/rui-ye/MAS-GPT.
Leveraging Unstructured Text Data for Federated Instruction Tuning of Large Language Models
Sep 11, 2024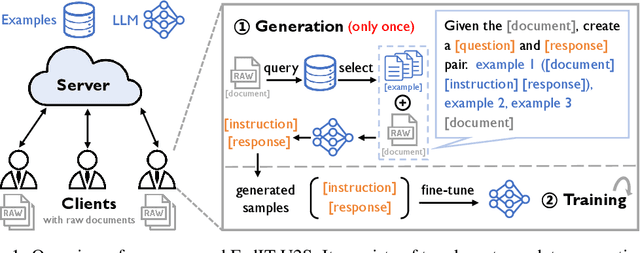


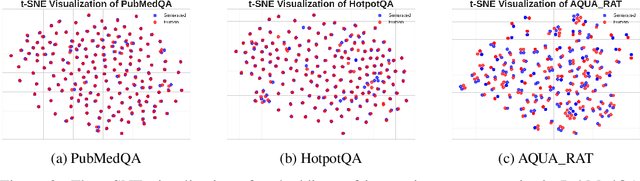
Federated instruction tuning enables multiple clients to collaboratively fine-tune a shared large language model (LLM) that can follow humans' instructions without directly sharing raw data. However, existing literature impractically requires that all the clients readily hold instruction-tuning data (i.e., structured instruction-response pairs), which necessitates massive human annotations since clients' data is usually unstructured text instead. Addressing this, we propose a novel and flexible framework FedIT-U2S, which can automatically transform unstructured corpus into structured data for federated instruction tuning. FedIT-U2S consists two key steps: (1) few-shot instruction-tuning data generation, where each unstructured data piece together with several examples is combined to prompt an LLM in generating an instruction-response pair. To further enhance the flexibility, a retrieval-based example selection technique is proposed, where the examples are automatically selected based on the relatedness between the client's data piece and example pool, bypassing the need of determining examples in advance. (2) A typical federated instruction tuning process based on the generated data. Overall, FedIT-U2S can be applied to diverse scenarios as long as the client holds valuable text corpus, broadening the application scope of federated instruction tuning. We conduct a series of experiments on three domains (medicine, knowledge, and math), showing that our proposed FedIT-U2S can consistently and significantly brings improvement over the base LLM.
FedLLM-Bench: Realistic Benchmarks for Federated Learning of Large Language Models
Jun 07, 2024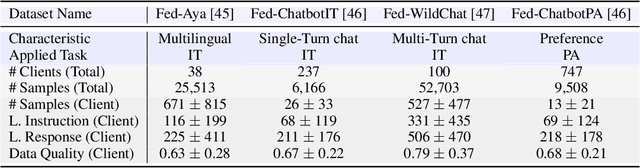
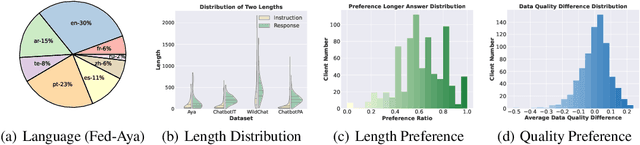
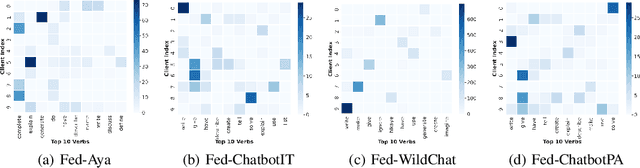
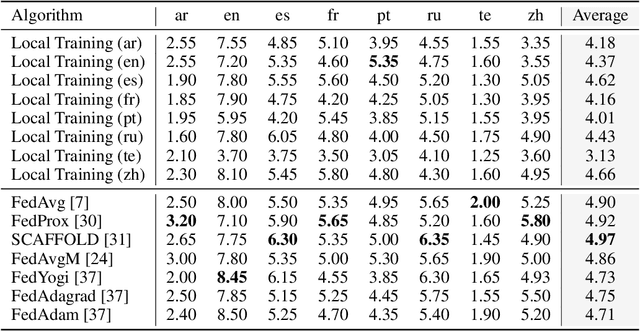
Federated learning has enabled multiple parties to collaboratively train large language models without directly sharing their data (FedLLM). Following this training paradigm, the community has put massive efforts from diverse aspects including framework, performance, and privacy. However, an unpleasant fact is that there are currently no realistic datasets and benchmarks for FedLLM and previous works all rely on artificially constructed datasets, failing to capture properties in real-world scenarios. Addressing this, we propose FedLLM-Bench, which involves 8 training methods, 4 training datasets, and 6 evaluation metrics, to offer a comprehensive testbed for the FedLLM community. FedLLM-Bench encompasses three datasets (e.g., user-annotated multilingual dataset) for federated instruction tuning and one dataset (e.g., user-annotated preference dataset) for federated preference alignment, whose scale of client number ranges from 38 to 747. Our datasets incorporate several representative diversities: language, quality, quantity, instruction, length, embedding, and preference, capturing properties in real-world scenarios. Based on FedLLM-Bench, we conduct experiments on all datasets to benchmark existing FL methods and provide empirical insights (e.g., multilingual collaboration). We believe that our FedLLM-Bench can benefit the FedLLM community by reducing required efforts, providing a practical testbed, and promoting fair comparisons. Code and datasets are available at https://github.com/rui-ye/FedLLM-Bench.