 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Self-Evolving Agentic Literature Retrieval
May 14, 2026As large language models reshape scientific research, literature retrieval faces a twofold challenge: ensuring source authenticity while maintaining a deep comprehension of academic search intents. While reliable, traditional keyword-centric search fails to capture complex research intents. Frontier LLMs can handle complex research intents, but their high cost and tendency to hallucinate remain key limitations. Here we introduce PaSaMaster, a self-evolving agentic literature retrieval system that produces relevance-scored paper rankings with evidence-grounded recommendations through iterative intent analysis, retrieval, and ranking. It is built on three key designs. First, it transforms literature retrieval from a one shot query--document matching problem into a search process that evolves over time, using ranked evidence to reveal gaps, refine intents, and guide follow-up searches. Second, it prevents hallucinated sources by treating retrieval as intent--paper relevance ranking rather than generation. Finally, PaSaMaster improves cost efficiency by separating planning from retrieval: a frontier LLM is used only for intent understanding, while large scale retrieval and relevance scoring are delegated to customized corpora and lightweight models. Evaluated on the PaSaMaster Benchmark across 38 scientific disciplines, our system exposes the severe inaccuracy and incompleteness of traditional keyword retrieval (improving F1-score by 15.6X) and the unreliability of generative LLMs (which exhibit hallucination rates up to 37.79%). Remarkably, PaSaMaster outperforms GPT-5.2 by 30.0% at a mere 1% of the computational cost while ensuring zero source hallucination: https://github.com/sjtu-sai-agents/PaSaMaster
EvoMaster: A Foundational Evolving Agent Framework for Agentic Science at Scale
Apr 21, 2026The convergence of large language models and agents is catalyzing a new era of scientific discovery: Agentic Science. While the scientific method is inherently iterative, existing agent frameworks are predominantly static, narrowly scoped, and lack the capacity to learn from trial and error. To bridge this gap, we present EvoMaster, a foundational evolving agent framework engineered specifically for Agentic Science at Scale. Driven by the core principle of continuous self-evolution, EvoMaster empowers agents to iteratively refine hypotheses, self-critique, and progressively accumulate knowledge across experimental cycles, faithfully mirroring human scientific inquiry. Crucially, as a domain-agnostic base harness, EvoMaster is exceptionally easy to scale up -- enabling developers to build and deploy highly capable, self-evolving scientific agents for arbitrary disciplines in approximately 100 lines of code. Built upon EvoMaster, we incubated the SciMaster ecosystem across domains such as machine learning, physics, and general science. Evaluations on four authoritative benchmarks (Humanity's Last Exam, MLE-Bench Lite, BrowseComp, and FrontierScience) demonstrate that EvoMaster achieves state-of-the-art scores of 41.1%, 75.8%, 73.3%, and 53.3%, respectively. It comprehensively outperforms the general-purpose baseline OpenClaw with relative improvements ranging from +159% to +316%, robustly validating its efficacy and generality as the premier foundational framework for the next generation of autonomous scientific discovery. EvoMaster is available at https://github.com/sjtu-sai-agents/EvoMaster.
Bohrium + SciMaster: Building the Infrastructure and Ecosystem for Agentic Science at Scale
Dec 23, 2025



AI agents are emerging as a practical way to run multi-step scientific workflows that interleave reasoning with tool use and verification, pointing to a shift from isolated AI-assisted steps toward \emph{agentic science at scale}. This shift is increasingly feasible, as scientific tools and models can be invoked through stable interfaces and verified with recorded execution traces, and increasingly necessary, as AI accelerates scientific output and stresses the peer-review and publication pipeline, raising the bar for traceability and credible evaluation. However, scaling agentic science remains difficult: workflows are hard to observe and reproduce; many tools and laboratory systems are not agent-ready; execution is hard to trace and govern; and prototype AI Scientist systems are often bespoke, limiting reuse and systematic improvement from real workflow signals. We argue that scaling agentic science requires an infrastructure-and-ecosystem approach, instantiated in Bohrium+SciMaster. Bohrium acts as a managed, traceable hub for AI4S assets -- akin to a HuggingFace of AI for Science -- that turns diverse scientific data, software, compute, and laboratory systems into agent-ready capabilities. SciMaster orchestrates these capabilities into long-horizon scientific workflows, on which scientific agents can be composed and executed. Between infrastructure and orchestration, a \emph{scientific intelligence substrate} organizes reusable models, knowledge, and components into executable building blocks for workflow reasoning and action, enabling composition, auditability, and improvement through use. We demonstrate this stack with eleven representative master agents in real workflows, achieving orders-of-magnitude reductions in end-to-end scientific cycle time and generating execution-grounded signals from real workloads at multi-million scale.
ML-Agent: Reinforcing LLM Agents for Autonomous Machine Learning Engineering
May 29, 2025The emergence of large language model (LLM)-based agents has significantly advanced the development of autonomous machine learning (ML) engineering. However, most existing approaches rely heavily on manual prompt engineering, failing to adapt and optimize based on diverse experimental experiences. Focusing on this, for the first time, we explore the paradigm of learning-based agentic ML, where an LLM agent learns through interactive experimentation on ML tasks using online reinforcement learning (RL). To realize this, we propose a novel agentic ML training framework with three key components: (1) exploration-enriched fine-tuning, which enables LLM agents to generate diverse actions for enhanced RL exploration; (2) step-wise RL, which enables training on a single action step, accelerating experience collection and improving training efficiency; (3) an agentic ML-specific reward module, which unifies varied ML feedback signals into consistent rewards for RL optimization. Leveraging this framework, we train ML-Agent, driven by a 7B-sized Qwen-2.5 LLM for autonomous ML. Remarkably, despite being trained on merely 9 ML tasks, our 7B-sized ML-Agent outperforms the 671B-sized DeepSeek-R1 agent. Furthermore, it achieves continuous performance improvements and demonstrates exceptional cross-task generalization capabilities.
Incentivizing Inclusive Contributions in Model Sharing Markets
May 05, 2025While data plays a crucial role in training contemporary AI models, it is acknowledged that valuable public data will be exhausted in a few years, directing the world's attention towards the massive decentralized private data. However, the privacy-sensitive nature of raw data and lack of incentive mechanism prevent these valuable data from being fully exploited. Addressing these challenges, this paper proposes inclusive and incentivized personalized federated learning (iPFL), which incentivizes data holders with diverse purposes to collaboratively train personalized models without revealing raw data. iPFL constructs a model-sharing market by solving a graph-based training optimization and incorporates an incentive mechanism based on game theory principles. Theoretical analysis shows that iPFL adheres to two key incentive properties: individual rationality and truthfulness. Empirical studies on eleven AI tasks (e.g., large language models' instruction-following tasks) demonstrate that iPFL consistently achieves the highest economic utility, and better or comparable model performance compared to baseline methods. We anticipate that our iPFL can serve as a valuable technique for boosting future AI models on decentralized private data while making everyone satisfied.
Are We There Yet? Revealing the Risks of Utilizing Large Language Models in Scholarly Peer Review
Dec 02, 2024
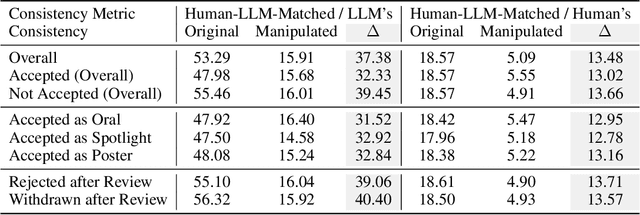
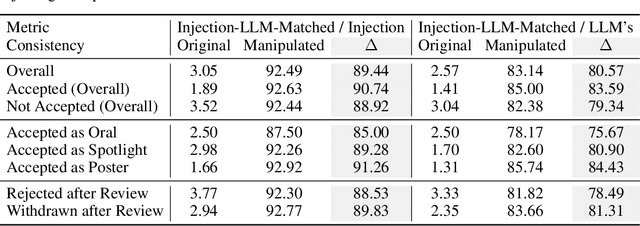

Scholarly peer review is a cornerstone of scientific advancement, but the system is under strain due to increasing manuscript submissions and the labor-intensive nature of the process. Recent advancements in large language models (LLMs) have led to their integration into peer review, with promising results such as substantial overlaps between LLM- and human-generated reviews. However, the unchecked adoption of LLMs poses significant risks to the integrity of the peer review system. In this study, we comprehensively analyze the vulnerabilities of LLM-generated reviews by focusing on manipulation and inherent flaws. Our experiments show that injecting covert deliberate content into manuscripts allows authors to explicitly manipulate LLM reviews, leading to inflated ratings and reduced alignment with human reviews. In a simulation, we find that manipulating 5% of the reviews could potentially cause 12% of the papers to lose their position in the top 30% rankings. Implicit manipulation, where authors strategically highlight minor limitations in their papers, further demonstrates LLMs' susceptibility compared to human reviewers, with a 4.5 times higher consistency with disclosed limitations. Additionally, LLMs exhibit inherent flaws, such as potentially assigning higher ratings to incomplete papers compared to full papers and favoring well-known authors in single-blind review process. These findings highlight the risks of over-reliance on LLMs in peer review, underscoring that we are not yet ready for widespread adoption and emphasizing the need for robust safeguards.
KnowledgeSG: Privacy-Preserving Synthetic Text Generation with Knowledge Distillation from Server
Oct 10, 2024



The success of large language models (LLMs) facilitate many parties to fine-tune LLMs on their own private data. However, this practice raises privacy concerns due to the memorization of LLMs. Existing solutions, such as utilizing synthetic data for substitution, struggle to simultaneously improve performance and preserve privacy. They either rely on a local model for generation, resulting in a performance decline, or take advantage of APIs, directly exposing the data to API servers. To address this issue, we propose KnowledgeSG, a novel client-server framework which enhances synthetic data quality and improves model performance while ensuring privacy. We achieve this by learning local knowledge from the private data with differential privacy (DP) and distilling professional knowledge from the server. Additionally, inspired by federated learning, we transmit models rather than data between the client and server to prevent privacy leakage. Extensive experiments in medical and financial domains demonstrate the effectiveness of KnowledgeSG. Our code is now publicly available at https://github.com/wwh0411/KnowledgeSG.
Leveraging Unstructured Text Data for Federated Instruction Tuning of Large Language Models
Sep 11, 2024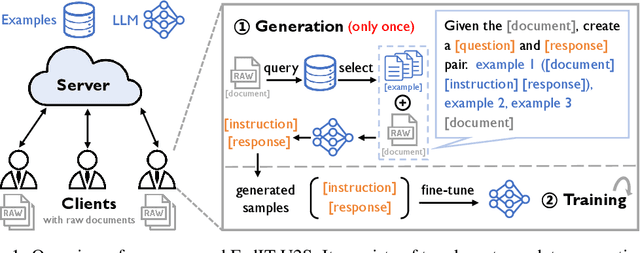


Federated instruction tuning enables multiple clients to collaboratively fine-tune a shared large language model (LLM) that can follow humans' instructions without directly sharing raw data. However, existing literature impractically requires that all the clients readily hold instruction-tuning data (i.e., structured instruction-response pairs), which necessitates massive human annotations since clients' data is usually unstructured text instead. Addressing this, we propose a novel and flexible framework FedIT-U2S, which can automatically transform unstructured corpus into structured data for federated instruction tuning. FedIT-U2S consists two key steps: (1) few-shot instruction-tuning data generation, where each unstructured data piece together with several examples is combined to prompt an LLM in generating an instruction-response pair. To further enhance the flexibility, a retrieval-based example selection technique is proposed, where the examples are automatically selected based on the relatedness between the client's data piece and example pool, bypassing the need of determining examples in advance. (2) A typical federated instruction tuning process based on the generated data. Overall, FedIT-U2S can be applied to diverse scenarios as long as the client holds valuable text corpus, broadening the application scope of federated instruction tuning. We conduct a series of experiments on three domains (medicine, knowledge, and math), showing that our proposed FedIT-U2S can consistently and significantly brings improvement over the base LLM.
Emerging Safety Attack and Defense in Federated Instruction Tuning of Large Language Models
Jun 15, 2024
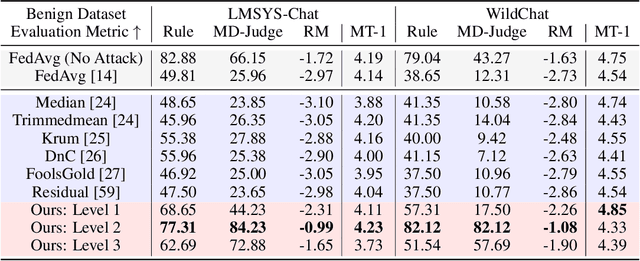
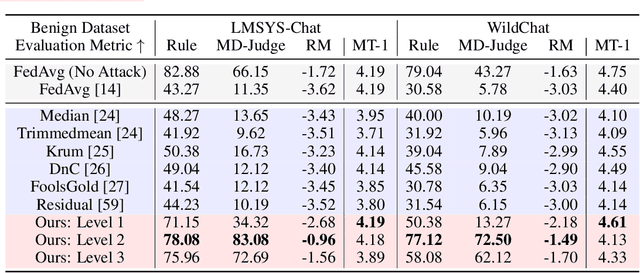

Federated learning (FL) enables multiple parties to collaboratively fine-tune an large language model (LLM) without the need of direct data sharing. Ideally, by training on decentralized data that is aligned with human preferences and safety principles, federated instruction tuning can result in an LLM that could behave in a helpful and safe manner. In this paper, we for the first time reveal the vulnerability of safety alignment in FedIT by proposing a simple, stealthy, yet effective safety attack method. Specifically, the malicious clients could automatically generate attack data without involving manual efforts and attack the FedIT system by training their local LLMs on such attack data. Unfortunately, this proposed safety attack not only can compromise the safety alignment of LLM trained via FedIT, but also can not be effectively defended against by many existing FL defense methods. Targeting this, we further propose a post-hoc defense method, which could rely on a fully automated pipeline: generation of defense data and further fine-tuning of the LLM. Extensive experiments show that our safety attack method can significantly compromise the LLM's safety alignment (e.g., reduce safety rate by 70\%), which can not be effectively defended by existing defense methods (at most 4\% absolute improvement), while our safety defense method can significantly enhance the attacked LLM's safety alignment (at most 69\% absolute improvement).
FedLLM-Bench: Realistic Benchmarks for Federated Learning of Large Language Models
Jun 07, 2024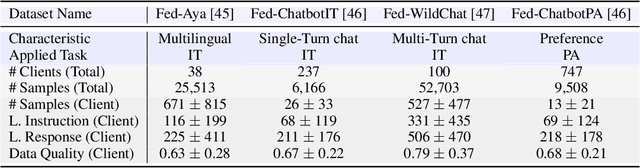
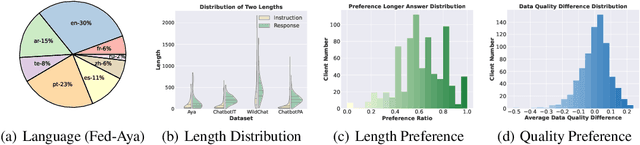
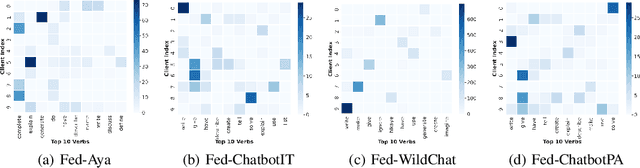
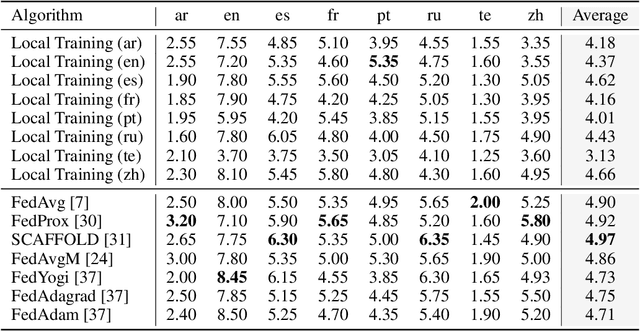
Federated learning has enabled multiple parties to collaboratively train large language models without directly sharing their data (FedLLM). Following this training paradigm, the community has put massive efforts from diverse aspects including framework, performance, and privacy. However, an unpleasant fact is that there are currently no realistic datasets and benchmarks for FedLLM and previous works all rely on artificially constructed datasets, failing to capture properties in real-world scenarios. Addressing this, we propose FedLLM-Bench, which involves 8 training methods, 4 training datasets, and 6 evaluation metrics, to offer a comprehensive testbed for the FedLLM community. FedLLM-Bench encompasses three datasets (e.g., user-annotated multilingual dataset) for federated instruction tuning and one dataset (e.g., user-annotated preference dataset) for federated preference alignment, whose scale of client number ranges from 38 to 747. Our datasets incorporate several representative diversities: language, quality, quantity, instruction, length, embedding, and preference, capturing properties in real-world scenarios. Based on FedLLM-Bench, we conduct experiments on all datasets to benchmark existing FL methods and provide empirical insights (e.g., multilingual collaboration). We believe that our FedLLM-Bench can benefit the FedLLM community by reducing required efforts, providing a practical testbed, and promoting fair comparisons. Code and datasets are available at https://github.com/rui-ye/FedLLM-Bench.