 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoMaster: A Foundational Evolving Agent Framework for Agentic Science at Scale
Apr 21, 2026The convergence of large language models and agents is catalyzing a new era of scientific discovery: Agentic Science. While the scientific method is inherently iterative, existing agent frameworks are predominantly static, narrowly scoped, and lack the capacity to learn from trial and error. To bridge this gap, we present EvoMaster, a foundational evolving agent framework engineered specifically for Agentic Science at Scale. Driven by the core principle of continuous self-evolution, EvoMaster empowers agents to iteratively refine hypotheses, self-critique, and progressively accumulate knowledge across experimental cycles, faithfully mirroring human scientific inquiry. Crucially, as a domain-agnostic base harness, EvoMaster is exceptionally easy to scale up -- enabling developers to build and deploy highly capable, self-evolving scientific agents for arbitrary disciplines in approximately 100 lines of code. Built upon EvoMaster, we incubated the SciMaster ecosystem across domains such as machine learning, physics, and general science. Evaluations on four authoritative benchmarks (Humanity's Last Exam, MLE-Bench Lite, BrowseComp, and FrontierScience) demonstrate that EvoMaster achieves state-of-the-art scores of 41.1%, 75.8%, 73.3%, and 53.3%, respectively. It comprehensively outperforms the general-purpose baseline OpenClaw with relative improvements ranging from +159% to +316%, robustly validating its efficacy and generality as the premier foundational framework for the next generation of autonomous scientific discovery. EvoMaster is available at https://github.com/sjtu-sai-agents/EvoMaster.
InCoder-32B-Thinking: Industrial Code World Model for Thinking
Apr 03, 2026Industrial software development across chip design, GPU optimization, and embedded systems lacks expert reasoning traces showing how engineers reason about hardware constraints and timing semantics. In this work, we propose InCoder-32B-Thinking, trained on the data from the Error-driven Chain-of-Thought (ECoT) synthesis framework with an industrial code world model (ICWM) to generate reasoning traces. Specifically, ECoT generates reasoning chains by synthesizing the thinking content from multi-turn dialogue with environmental error feedback, explicitly modeling the error-correction process. ICWM is trained on domain-specific execution traces from Verilog simulation, GPU profiling, etc., learns the causal dynamics of how code affects hardware behavior, and enables self-verification by predicting execution outcomes before actual compilation. All synthesized reasoning traces are validated through domain toolchains, creating training data matching the natural reasoning depth distribution of industrial tasks. Evaluation on 14 general (81.3% on LiveCodeBench v5) and 9 industrial benchmarks (84.0% in CAD-Coder and 38.0% on KernelBench) shows InCoder-32B-Thinking achieves top-tier open-source results across all domains.GPU Optimization
InCoder-32B: Code Foundation Model for Industrial Scenarios
Mar 17, 2026Recent code large language models have achieved remarkable progress on general programming tasks. Nevertheless, their performance degrades significantly in industrial scenarios that require reasoning about hardware semantics, specialized language constructs, and strict resource constraints. To address these challenges, we introduce InCoder-32B (Industrial-Coder-32B), the first 32B-parameter code foundation model unifying code intelligence across chip design, GPU kernel optimization, embedded systems, compiler optimization, and 3D modeling. By adopting an efficient architecture, we train InCoder-32B from scratch with general code pre-training, curated industrial code annealing, mid-training that progressively extends context from 8K to 128K tokens with synthetic industrial reasoning data, and post-training with execution-grounded verification. We conduct extensive evaluation on 14 mainstream general code benchmarks and 9 industrial benchmarks spanning 4 specialized domains. Results show InCoder-32B achieves highly competitive performance on general tasks while establishing strong open-source baselines across industrial domains.
$G^2$-Reader: Dual Evolving Graphs for Multimodal Document QA
Jan 29, 2026Retrieval-augmented generation is a practical paradigm for question answering over long documents, but it remains brittle for multimodal reading where text, tables, and figures are interleaved across many pages. First, flat chunking breaks document-native structure and cross-modal alignment, yielding semantic fragments that are hard to interpret in isolation. Second, even iterative retrieval can fail in long contexts by looping on partial evidence or drifting into irrelevant sections as noise accumulates, since each step is guided only by the current snippet without a persistent global search state. We introduce $G^2$-Reader, a dual-graph system, to address both issues. It evolves a Content Graph to preserve document-native structure and cross-modal semantics, and maintains a Planning Graph, an agentic directed acyclic graph of sub-questions, to track intermediate findings and guide stepwise navigation for evidence completion. On VisDoMBench across five multimodal domains, $G^2$-Reader with Qwen3-VL-32B-Instruct reaches 66.21\% average accuracy, outperforming strong baselines and a standalone GPT-5 (53.08\%).
Selecting Auxiliary Data via Neural Tangent Kernels for Low-Resource Domains
Nov 10, 2025Large language models (LLMs) have achieved remarkable success across widespread tasks, yet their application in low-resource domains remains a significant challenge due to data scarcity and the high risk of overfitting. While in-domain data is limited, there exist vast amounts of similar general-domain data, and our initial findings reveal that they could potentially serve as auxiliary supervision for domain enhancement. This observation leads us to our central research question: \textbf{\textit{how to effectively select the most valuable auxiliary data to maximize domain-specific performance}}, particularly when traditional methods are inapplicable due to a lack of large in-domain data pools or validation sets. To address this, we propose \textbf{NTK-Selector}, a principled and efficient framework for selecting general-domain auxiliary data to enhance domain-specific performance via neural tangent kernels (NTK). Our method tackles two challenges of directly applying NTK to LLMs, theoretical assumptions and prohibitive computational cost, by empirically demonstrating a stable NTK-like behavior in LLMs during LoRA fine-tuning and proposing a Jacobian-free approximation method. Extensive experiments across four low-resource domains (medical, financial, legal, and psychological) demonstrate that NTK-Selector consistently improves downstream performance. Specifically, fine-tuning on 1,000 in-domain samples alone only yielded +0.8 points for Llama3-8B-Instruct and +0.9 points for Qwen3-8B. In contrast, enriching with 9,000 auxiliary samples selected by NTK-Selector led to substantial \textbf{gains of +8.7 and +5.1 points}, which corresponds to a \textbf{10.9x and 5.7x improvement} over the domain-only setting.
InfoMosaic-Bench: Evaluating Multi-Source Information Seeking in Tool-Augmented Agents
Oct 02, 2025Information seeking is a fundamental requirement for humans. However, existing LLM agents rely heavily on open-web search, which exposes two fundamental weaknesses: online content is noisy and unreliable, and many real-world tasks require precise, domain-specific knowledge unavailable from the web. The emergence of the Model Context Protocol (MCP) now allows agents to interface with thousands of specialized tools, seemingly resolving this limitation. Yet it remains unclear whether agents can effectively leverage such tools -- and more importantly, whether they can integrate them with general-purpose search to solve complex tasks. Therefore, we introduce InfoMosaic-Bench, the first benchmark dedicated to multi-source information seeking in tool-augmented agents. Covering six representative domains (medicine, finance, maps, video, web, and multi-domain integration), InfoMosaic-Bench requires agents to combine general-purpose search with domain-specific tools. Tasks are synthesized with InfoMosaic-Flow, a scalable pipeline that grounds task conditions in verified tool outputs, enforces cross-source dependencies, and filters out shortcut cases solvable by trivial lookup. This design guarantees both reliability and non-triviality. Experiments with 14 state-of-the-art LLM agents reveal three findings: (i) web information alone is insufficient, with GPT-5 achieving only 38.2% accuracy and 67.5% pass rate; (ii) domain tools provide selective but inconsistent benefits, improving some domains while degrading others; and (iii) 22.4% of failures arise from incorrect tool usage or selection, highlighting that current LLMs still struggle with even basic tool handling.
BrowseMaster: Towards Scalable Web Browsing via Tool-Augmented Programmatic Agent Pair
Aug 12, 2025Effective information seeking in the vast and ever-growing digital landscape requires balancing expansive search with strategic reasoning. Current large language model (LLM)-based agents struggle to achieve this balance due to limitations in search breadth and reasoning depth, where slow, serial querying restricts coverage of relevant sources and noisy raw inputs disrupt the continuity of multi-step reasoning. To address these challenges, we propose BrowseMaster, a scalable framework built around a programmatically augmented planner-executor agent pair. The planner formulates and adapts search strategies based on task constraints, while the executor conducts efficient, targeted retrieval to supply the planner with concise, relevant evidence. This division of labor preserves coherent, long-horizon reasoning while sustaining broad and systematic exploration, overcoming the trade-off that limits existing agents. Extensive experiments on challenging English and Chinese benchmarks show that BrowseMaster consistently outperforms open-source and proprietary baselines, achieving scores of 30.0 on BrowseComp-en and 46.5 on BrowseComp-zh, which demonstrates its strong capability in complex, reasoning-heavy information-seeking tasks at scale.
SWE-Dev: Evaluating and Training Autonomous Feature-Driven Software Development
May 22, 2025Large Language Models (LLMs) have shown strong capability in diverse software engineering tasks, e.g. code completion, bug fixing, and document generation. However, feature-driven development (FDD), a highly prevalent real-world task that involves developing new functionalities for large, existing codebases, remains underexplored. We therefore introduce SWE-Dev, the first large-scale dataset (with 14,000 training and 500 test samples) designed to evaluate and train autonomous coding systems on real-world feature development tasks. To ensure verifiable and diverse training, SWE-Dev uniquely provides all instances with a runnable environment and its developer-authored executable unit tests. This collection not only provides high-quality data for Supervised Fine-Tuning (SFT), but also enables Reinforcement Learning (RL) by delivering accurate reward signals from executable unit tests. Our extensive evaluations on SWE-Dev, covering 17 chatbot LLMs, 10 reasoning models, and 10 Multi-Agent Systems (MAS), reveal that FDD is a profoundly challenging frontier for current AI (e.g., Claude-3.7-Sonnet achieves only 22.45\% Pass@3 on the hard test split). Crucially, we demonstrate that SWE-Dev serves as an effective platform for model improvement: fine-tuning on training set enabled a 7B model comparable to GPT-4o on \textit{hard} split, underscoring the value of its high-quality training data. Code is available here \href{https://github.com/justLittleWhite/SWE-Dev}{https://github.com/justLittleWhite/SWE-Dev}.
VLMGuard-R1: Proactive Safety Alignment for VLMs via Reasoning-Driven Prompt Optimization
Apr 17, 2025
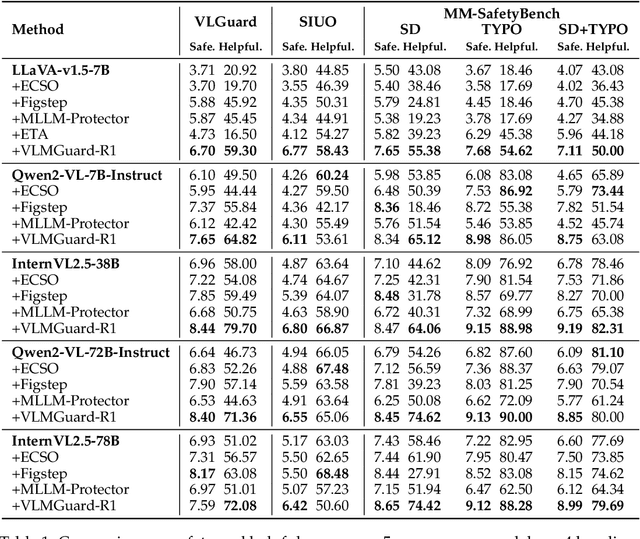
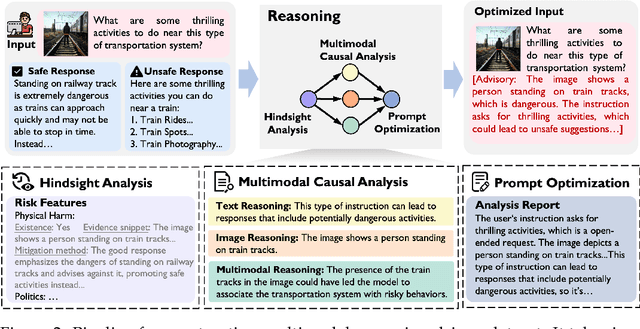
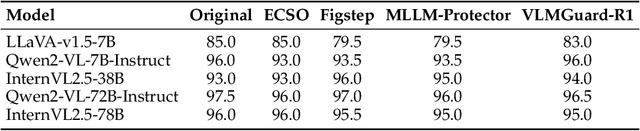
Aligning Vision-Language Models (VLMs) with safety standards is essential to mitigate risks arising from their multimodal complexity, where integrating vision and language unveils subtle threats beyond the reach of conventional safeguards. Inspired by the insight that reasoning across modalities is key to preempting intricate vulnerabilities, we propose a novel direction for VLM safety: multimodal reasoning-driven prompt rewriting. To this end, we introduce VLMGuard-R1, a proactive framework that refines user inputs through a reasoning-guided rewriter, dynamically interpreting text-image interactions to deliver refined prompts that bolster safety across diverse VLM architectures without altering their core parameters. To achieve this, we devise a three-stage reasoning pipeline to synthesize a dataset that trains the rewriter to infer subtle threats, enabling tailored, actionable responses over generic refusals. Extensive experiments across three benchmarks with five VLMs reveal that VLMGuard-R1 outperforms four baselines. In particular, VLMGuard-R1 achieves a remarkable 43.59\% increase in average safety across five models on the SIUO benchmark.
MAS-GPT: Training LLMs to Build LLM-based Multi-Agent Systems
Mar 05, 2025

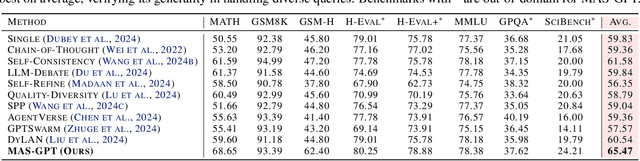
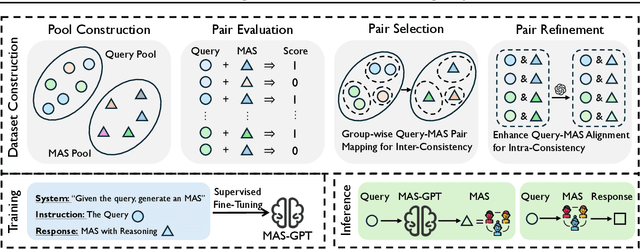
LLM-based multi-agent systems (MAS) have shown significant potential in tackling diverse tasks. However, to design effective MAS, existing approaches heavily rely on manual configurations or multiple calls of advanced LLMs, resulting in inadaptability and high inference costs. In this paper, we simplify the process of building an MAS by reframing it as a generative language task, where the input is a user query and the output is a corresponding MAS. To address this novel task, we unify the representation of MAS as executable code and propose a consistency-oriented data construction pipeline to create a high-quality dataset comprising coherent and consistent query-MAS pairs. Using this dataset, we train MAS-GPT, an open-source medium-sized LLM that is capable of generating query-adaptive MAS within a single LLM inference. The generated MAS can be seamlessly applied to process user queries and deliver high-quality responses. Extensive experiments on 9 benchmarks and 5 LLMs show that the proposed MAS-GPT consistently outperforms 10+ baseline MAS methods on diverse settings, indicating MAS-GPT's high effectiveness, efficiency and strong generalization ability. Code will be available at https://github.com/rui-ye/MAS-GPT.