 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFED-PsyAU: Privacy-Preserving Micro-Expression Recognition via Psychological AU Coordination and Dynamic Facial Motion Modeling
Jul 28, 2025

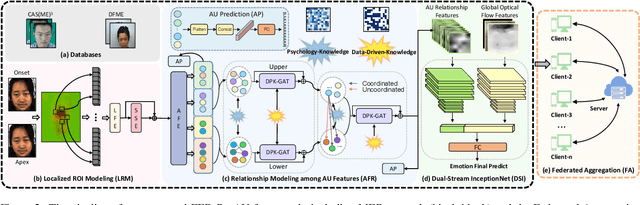

Micro-expressions (MEs) are brief, low-intensity, often localized facial expressions. They could reveal genuine emotions individuals may attempt to conceal, valuable in contexts like criminal interrogation and psychological counseling. However, ME recognition (MER) faces challenges, such as small sample sizes and subtle features, which hinder efficient modeling. Additionally, real-world applications encounter ME data privacy issues, leaving the task of enhancing recognition across settings under privacy constraints largely unexplored. To address these issues, we propose a FED-PsyAU research framework. We begin with a psychological study on the coordination of upper and lower facial action units (AUs) to provide structured prior knowledge of facial muscle dynamics. We then develop a DPK-GAT network that combines these psychological priors with statistical AU patterns, enabling hierarchical learning of facial motion features from regional to global levels, effectively enhancing MER performance. Additionally, our federated learning framework advances MER capabilities across multiple clients without data sharing, preserving privacy and alleviating the limited-sample issue for each client. Extensive experiments on commonly-used ME databases demonstrate the effectiveness of our approach.
SWE-Dev: Evaluating and Training Autonomous Feature-Driven Software Development
May 22, 2025Large Language Models (LLMs) have shown strong capability in diverse software engineering tasks, e.g. code completion, bug fixing, and document generation. However, feature-driven development (FDD), a highly prevalent real-world task that involves developing new functionalities for large, existing codebases, remains underexplored. We therefore introduce SWE-Dev, the first large-scale dataset (with 14,000 training and 500 test samples) designed to evaluate and train autonomous coding systems on real-world feature development tasks. To ensure verifiable and diverse training, SWE-Dev uniquely provides all instances with a runnable environment and its developer-authored executable unit tests. This collection not only provides high-quality data for Supervised Fine-Tuning (SFT), but also enables Reinforcement Learning (RL) by delivering accurate reward signals from executable unit tests. Our extensive evaluations on SWE-Dev, covering 17 chatbot LLMs, 10 reasoning models, and 10 Multi-Agent Systems (MAS), reveal that FDD is a profoundly challenging frontier for current AI (e.g., Claude-3.7-Sonnet achieves only 22.45\% Pass@3 on the hard test split). Crucially, we demonstrate that SWE-Dev serves as an effective platform for model improvement: fine-tuning on training set enabled a 7B model comparable to GPT-4o on \textit{hard} split, underscoring the value of its high-quality training data. Code is available here \href{https://github.com/justLittleWhite/SWE-Dev}{https://github.com/justLittleWhite/SWE-Dev}.
TransBench: Benchmarking Machine Translation for Industrial-Scale Applications
May 20, 2025Machine translation (MT) has become indispensable for cross-border communication in globalized industries like e-commerce, finance, and legal services, with recent advancements in large language models (LLMs) significantly enhancing translation quality. However, applying general-purpose MT models to industrial scenarios reveals critical limitations due to domain-specific terminology, cultural nuances, and stylistic conventions absent in generic benchmarks. Existing evaluation frameworks inadequately assess performance in specialized contexts, creating a gap between academic benchmarks and real-world efficacy. To address this, we propose a three-level translation capability framework: (1) Basic Linguistic Competence, (2) Domain-Specific Proficiency, and (3) Cultural Adaptation, emphasizing the need for holistic evaluation across these dimensions. We introduce TransBench, a benchmark tailored for industrial MT, initially targeting international e-commerce with 17,000 professionally translated sentences spanning 4 main scenarios and 33 language pairs. TransBench integrates traditional metrics (BLEU, TER) with Marco-MOS, a domain-specific evaluation model, and provides guidelines for reproducible benchmark construction. Our contributions include: (1) a structured framework for industrial MT evaluation, (2) the first publicly available benchmark for e-commerce translation, (3) novel metrics probing multi-level translation quality, and (4) open-sourced evaluation tools. This work bridges the evaluation gap, enabling researchers and practitioners to systematically assess and enhance MT systems for industry-specific needs.
COVID-VIT: Classification of COVID-19 from CT chest images based on vision transformer models
Jul 04, 2021

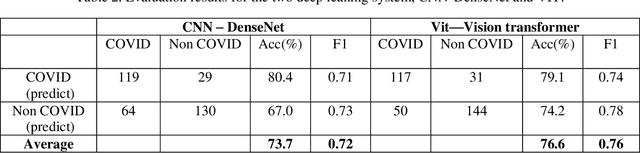
This paper is responding to the MIA-COV19 challenge to classify COVID from non-COVID based on CT lung images. The COVID-19 virus has devastated the world in the last eighteen months by infecting more than 182 million people and causing over 3.9 million deaths. The overarching aim is to predict the diagnosis of the COVID-19 virus from chest radiographs, through the development of explainable vision transformer deep learning techniques, leading to population screening in a more rapid, accurate and transparent way. In this competition, there are 5381 three-dimensional (3D) datasets in total, including 1552 for training, 374 for evaluation and 3455 for testing. While most of the data volumes are in axial view, there are a number of subjects' data are in coronal or sagittal views with 1 or 2 slices are in axial view. Hence, while 3D data based classification is investigated, in this competition, 2D images remains the main focus. Two deep learning methods are studied, which are vision transformer (ViT) based on attention models and DenseNet that is built upon conventional convolutional neural network (CNN). Initial evaluation results based on validation datasets whereby the ground truth is known indicate that ViT performs better than DenseNet with F1 scores being 0.76 and 0.72 respectively. Codes are available at GitHub at <https://github/xiaohong1/COVID-ViT>.
Can Sophisticated Dispatching Strategy Acquired by Reinforcement Learning? - A Case Study in Dynamic Courier Dispatching System
Mar 07, 2019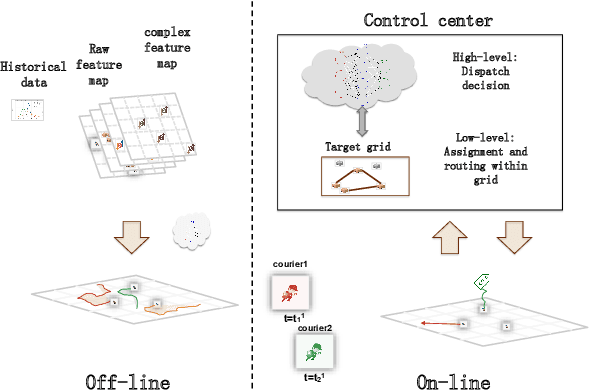

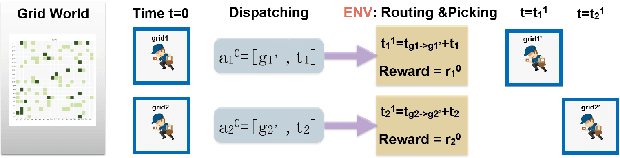
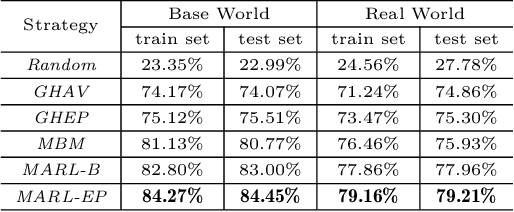
In this paper, we study a courier dispatching problem (CDP) raised from an online pickup-service platform of Alibaba. The CDP aims to assign a set of couriers to serve pickup requests with stochastic spatial and temporal arrival rate among urban regions. The objective is to maximize the revenue of served requests given a limited number of couriers over a period of time. Many online algorithms such as dynamic matching and vehicle routing strategy from existing literature could be applied to tackle this problem. However, these methods rely on appropriately predefined optimization objectives at each decision point, which is hard in dynamic situations. This paper formulates the CDP as a Markov decision process (MDP) and proposes a data-driven approach to derive the optimal dispatching rule-set under different scenarios. Our method stacks multi-layer images of the spatial-and-temporal map and apply multi-agent reinforcement learning (MARL) techniques to evolve dispatching models. This method solves the learning inefficiency caused by traditional centralized MDP modeling. Through comprehensive experiments on both artificial dataset and real-world dataset, we show: 1) By utilizing historical data and considering long-term revenue gains, MARL achieves better performance than myopic online algorithms; 2) MARL is able to construct the mapping between complex scenarios to sophisticated decisions such as the dispatching rule. 3) MARL has the scalability to adopt in large-scale real-world scenarios.
Instance Retrieval at Fine-grained Level Using Multi-Attribute Recognition
Nov 07, 2018
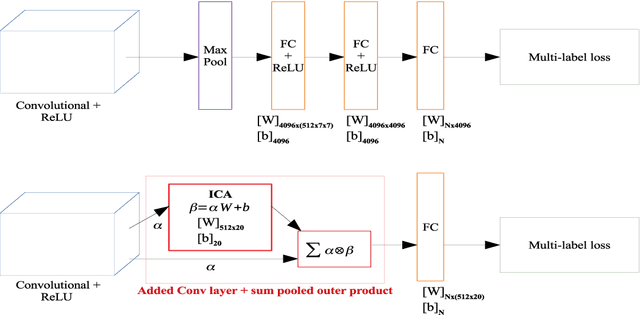
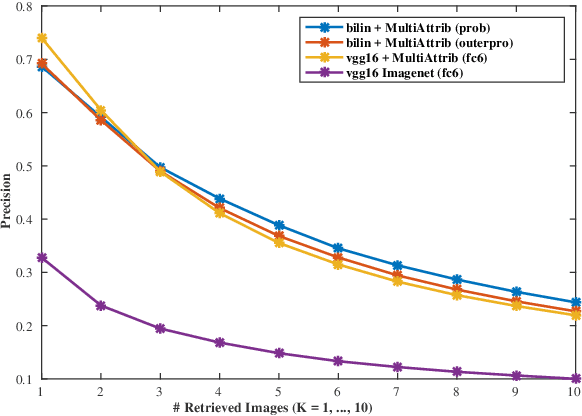
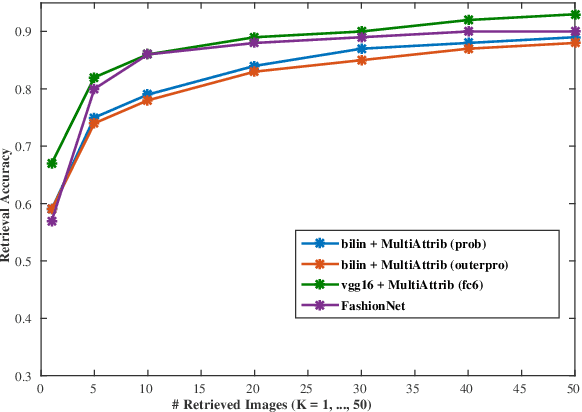
In this paper, we present a method for instance ranking and retrieval at fine-grained level based on the global features extracted from a multi-attribute recognition model which is not dependent on landmarks information or part-based annotations. Further, we make this architecture suitable for mobile-device application by adopting the bilinear CNN to make the multi-attribute recognition model smaller (in terms of the number of parameters). The experiments run on the Dress category of DeepFashion In-Shop Clothes Retrieval and CUB200 datasets show that the results of instance retrieval at fine-grained level are promising for these datasets, specially in terms of texture and color.
FineTag: Multi-attribute Classification at Fine-grained Level in Images
Oct 25, 2018
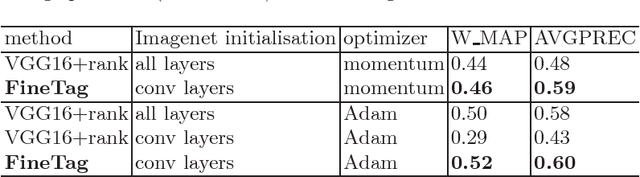

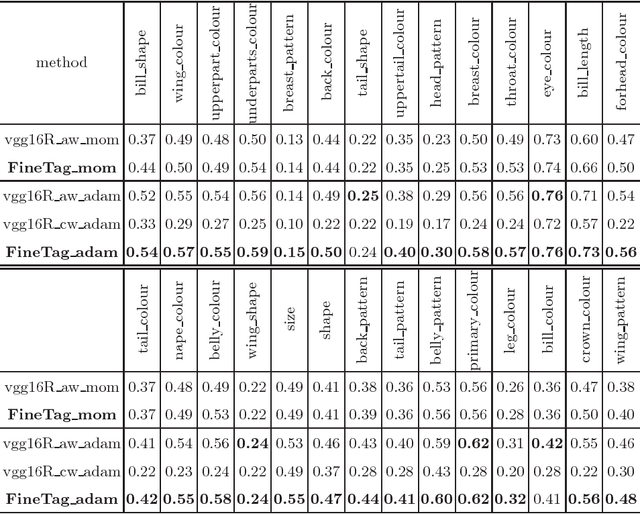
In this paper, we address the extraction of the fine-grained attributes of an instance as a `multi-attribute classification' problem. To this end, we propose an end-to-end architecture by adopting the bi-linear Convolutional Neural Network with the pairwise ranking loss. This is the first time such architecture is applied for the fine-grained attributes classification problem. We compared the proposed method with a competitive deep Convolutional Neural Network baseline. Extensive experiments show that the proposed method attains/outperforms the performance of compared baseline with significantly less number of parameters ($40\times$ less). We demonstrated our approach on CUB200 birds dataset whose annotations are adapted in this work for multi-attribute classification at fine-grained level.
Improving the Annotation of DeepFashion Images for Fine-grained Attribute Recognition
Jul 31, 2018
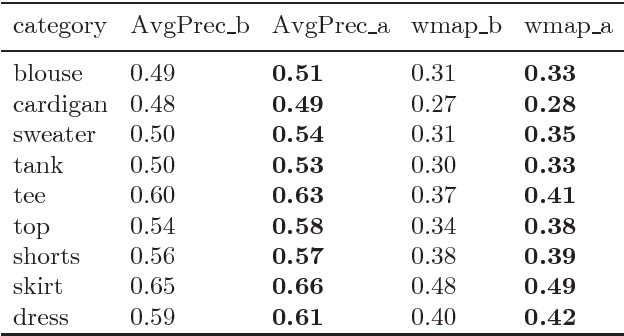
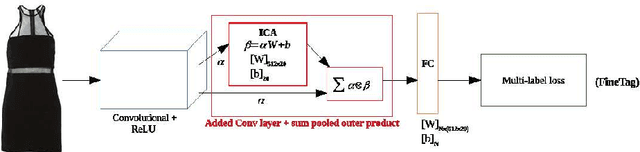
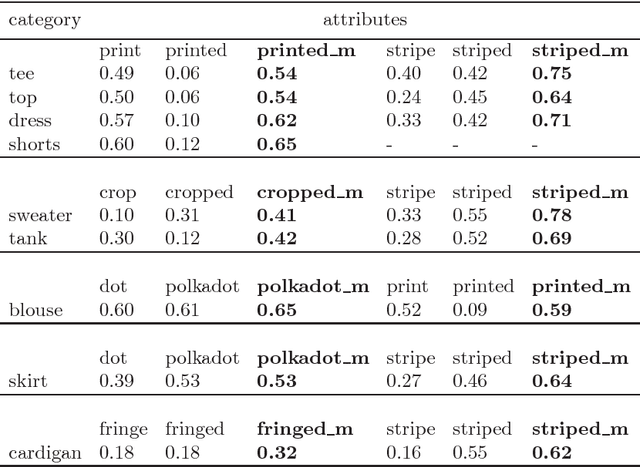
DeepFashion is a widely used clothing dataset with 50 categories and more than overall 200k images where each image is annotated with fine-grained attributes. This dataset is often used for clothes recognition and although it provides comprehensive annotations, the attributes distribution is unbalanced and repetitive specially for training fine-grained attribute recognition models. In this work, we tailored DeepFashion for fine-grained attribute recognition task by focusing on each category separately. After selecting categories with sufficient number of images for training, we remove very scarce attributes and merge the duplicate ones in each category, then we clean the dataset based on the new list of attributes. We use a bilinear convolutional neural network with pairwise ranking loss function for multi-label fine-grained attribute recognition and show that the new annotations improve the results for such a task. The detailed annotations for each of the selected categories are provided for public use.
Multi-kernel learning of deep convolutional features for action recognition
Nov 12, 2017



Image understanding using deep convolutional network has reached human-level performance, yet a closely related problem of video understanding especially, action recognition has not reached the requisite level of maturity. We combine multi-kernels based support-vector-machines (SVM) with a multi-stream deep convolutional neural network to achieve close to state-of-the-art performance on a 51-class activity recognition problem (HMDB-51 dataset); this specific dataset has proved to be particularly challenging for deep neural networks due to the heterogeneity in camera viewpoints, video quality, etc. The resulting architecture is named pillar networks as each (very) deep neural network acts as a pillar for the hierarchical classifiers. In addition, we illustrate that hand-crafted features such as improved dense trajectories (iDT) and Multi-skip Feature Stacking (MIFS), as additional pillars, can further supplement the performance.
Pillar Networks++: Distributed non-parametric deep and wide networks
Aug 18, 2017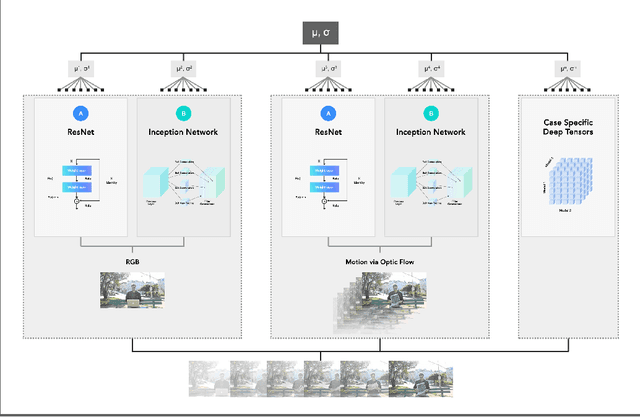


In recent work, it was shown that combining multi-kernel based support vector machines (SVMs) can lead to near state-of-the-art performance on an action recognition dataset (HMDB-51 dataset). This was 0.4\% lower than frameworks that used hand-crafted features in addition to the deep convolutional feature extractors. In the present work, we show that combining distributed Gaussian Processes with multi-stream deep convolutional neural networks (CNN) alleviate the need to augment a neural network with hand-crafted features. In contrast to prior work, we treat each deep neural convolutional network as an expert wherein the individual predictions (and their respective uncertainties) are combined into a Product of Experts (PoE) framework.