 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Hallucination in Financial Retrieval-Augmented Generation via Fine-Grained Knowledge Verification
Feb 05, 2026In financial Retrieval-Augmented Generation (RAG) systems, models frequently rely on retrieved documents to generate accurate responses due to the time-sensitive nature of the financial domain. While retrieved documents help address knowledge gaps, model-generated responses still suffer from hallucinations that contradict the retrieved information. To mitigate this inconsistency, we propose a Reinforcement Learning framework enhanced with Fine-grained Knowledge Verification (RLFKV). Our method decomposes financial responses into atomic knowledge units and assesses the correctness of each unit to compute the fine-grained faithful reward. This reward offers more precise optimization signals, thereby improving alignment with the retrieved documents. Additionally, to prevent reward hacking (e.g., overly concise replies), we incorporate an informativeness reward that encourages the policy model to retain at least as many knowledge units as the base model. Experiments conducted on the public Financial Data Description (FDD) task and our newly proposed FDD-ANT dataset demonstrate consistent improvements, confirming the effectiveness of our approach.
StepHint: Multi-level Stepwise Hints Enhance Reinforcement Learning to Reason
Jul 03, 2025Reinforcement learning with verifiable rewards (RLVR) is a promising approach for improving the complex reasoning abilities of large language models (LLMs). However, current RLVR methods face two significant challenges: the near-miss reward problem, where a small mistake can invalidate an otherwise correct reasoning process, greatly hindering training efficiency; and exploration stagnation, where models tend to focus on solutions within their ``comfort zone,'' lacking the motivation to explore potentially more effective alternatives. To address these challenges, we propose StepHint, a novel RLVR algorithm that utilizes multi-level stepwise hints to help models explore the solution space more effectively. StepHint generates valid reasoning chains from stronger models and partitions these chains into reasoning steps using our proposed adaptive partitioning method. The initial few steps are used as hints, and simultaneously, multiple-level hints (each comprising a different number of steps) are provided to the model. This approach directs the model's exploration toward a promising solution subspace while preserving its flexibility for independent exploration. By providing hints, StepHint mitigates the near-miss reward problem, thereby improving training efficiency. Additionally, the external reasoning pathways help the model develop better reasoning abilities, enabling it to move beyond its ``comfort zone'' and mitigate exploration stagnation. StepHint outperforms competitive RLVR enhancement methods across six mathematical benchmarks, while also demonstrating superior generalization and excelling over baselines on out-of-domain benchmarks.
SENIOR: Efficient Query Selection and Preference-Guided Exploration in Preference-based Reinforcement Learning
Jun 17, 2025Preference-based Reinforcement Learning (PbRL) methods provide a solution to avoid reward engineering by learning reward models based on human preferences. However, poor feedback- and sample- efficiency still remain the problems that hinder the application of PbRL. In this paper, we present a novel efficient query selection and preference-guided exploration method, called SENIOR, which could select the meaningful and easy-to-comparison behavior segment pairs to improve human feedback-efficiency and accelerate policy learning with the designed preference-guided intrinsic rewards. Our key idea is twofold: (1) We designed a Motion-Distinction-based Selection scheme (MDS). It selects segment pairs with apparent motion and different directions through kernel density estimation of states, which is more task-related and easy for human preference labeling; (2) We proposed a novel preference-guided exploration method (PGE). It encourages the exploration towards the states with high preference and low visits and continuously guides the agent achieving the valuable samples. The synergy between the two mechanisms could significantly accelerate the progress of reward and policy learning. Our experiments show that SENIOR outperforms other five existing methods in both human feedback-efficiency and policy convergence speed on six complex robot manipulation tasks from simulation and four real-worlds.
DRL4AOI: A DRL Framework for Semantic-aware AOI Segmentation in Location-Based Services
Dec 06, 2024



In Location-Based Services (LBS), such as food delivery, a fundamental task is segmenting Areas of Interest (AOIs), aiming at partitioning the urban geographical spaces into non-overlapping regions. Traditional AOI segmentation algorithms primarily rely on road networks to partition urban areas. While promising in modeling the geo-semantics, road network-based models overlooked the service-semantic goals (e.g., workload equality) in LBS service. In this paper, we point out that the AOI segmentation problem can be naturally formulated as a Markov Decision Process (MDP), which gradually chooses a nearby AOI for each grid in the current AOI's border. Based on the MDP, we present the first attempt to generalize Deep Reinforcement Learning (DRL) for AOI segmentation, leading to a novel DRL-based framework called DRL4AOI. The DRL4AOI framework introduces different service-semantic goals in a flexible way by treating them as rewards that guide the AOI generation. To evaluate the effectiveness of DRL4AOI, we develop and release an AOI segmentation system. We also present a representative implementation of DRL4AOI - TrajRL4AOI - for AOI segmentation in the logistics service. It introduces a Double Deep Q-learning Network (DDQN) to gradually optimize the AOI generation for two specific semantic goals: i) trajectory modularity, i.e., maximize tightness of the trajectory connections within an AOI and the sparsity of connections between AOIs, ii) matchness with the road network, i.e., maximizing the matchness between AOIs and the road network. Quantitative and qualitative experiments conducted on synthetic and real-world data demonstrate the effectiveness and superiority of our method. The code and system is publicly available at https://github.com/Kogler7/AoiOpt.
Effective Generation of Feasible Solutions for Integer Programming via Guided Diffusion
Jun 18, 2024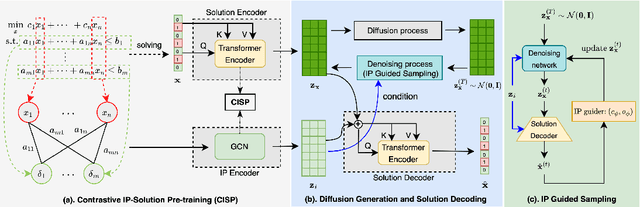
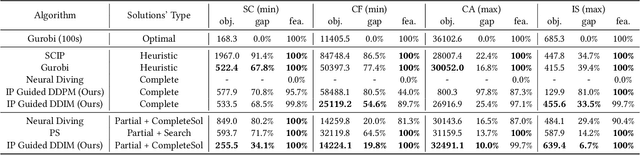
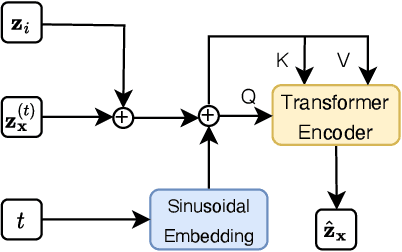

Feasible solutions are crucial for Integer Programming (IP) since they can substantially speed up the solving process. In many applications, similar IP instances often exhibit similar structures and shared solution distributions, which can be potentially modeled by deep learning methods. Unfortunately, existing deep-learning-based algorithms, such as Neural Diving and Predict-and-search framework, are limited to generating only partial feasible solutions, and they must rely on solvers like SCIP and Gurobi to complete the solutions for a given IP problem. In this paper, we propose a novel framework that generates complete feasible solutions end-to-end. Our framework leverages contrastive learning to characterize the relationship between IP instances and solutions, and learns latent embeddings for both IP instances and their solutions. Further, the framework employs diffusion models to learn the distribution of solution embeddings conditioned on IP representations, with a dedicated guided sampling strategy that accounts for both constraints and objectives. We empirically evaluate our framework on four typical datasets of IP problems, and show that it effectively generates complete feasible solutions with a high probability (> 89.7 \%) without the reliance of Solvers and the quality of solutions is comparable to the best heuristic solutions from Gurobi. Furthermore, by integrating our method's sampled partial solutions with the CompleteSol heuristic from SCIP, the resulting feasible solutions outperform those from state-of-the-art methods across all datasets, exhibiting a 3.7 to 33.7\% improvement in the gap to optimal values, and maintaining a feasible ratio of over 99.7\% for all datasets.
Differentiation of Multi-objective Data-driven Decision Pipeline
Jun 02, 2024Real-world scenarios frequently involve multi-objective data-driven optimization problems, characterized by unknown problem coefficients and multiple conflicting objectives. Traditional two-stage methods independently apply a machine learning model to estimate problem coefficients, followed by invoking a solver to tackle the predicted optimization problem. The independent use of optimization solvers and prediction models may lead to suboptimal performance due to mismatches between their objectives. Recent efforts have focused on end-to-end training of predictive models that use decision loss derived from the downstream optimization problem. However, these methods have primarily focused on single-objective optimization problems, thus limiting their applicability. We aim to propose a multi-objective decision-focused approach to address this gap. In order to better align with the inherent properties of multi-objective optimization problems, we propose a set of novel loss functions. These loss functions are designed to capture the discrepancies between predicted and true decision problems, considering solution space, objective space, and decision quality, named landscape loss, Pareto set loss, and decision loss, respectively. Our experimental results demonstrate that our proposed method significantly outperforms traditional two-stage methods and most current decision-focused methods.
Dr3: Ask Large Language Models Not to Give Off-Topic Answers in Open Domain Multi-Hop Question Answering
Mar 19, 2024



Open Domain Multi-Hop Question Answering (ODMHQA) plays a crucial role in Natural Language Processing (NLP) by aiming to answer complex questions through multi-step reasoning over retrieved information from external knowledge sources. Recently, Large Language Models (LLMs) have demonstrated remarkable performance in solving ODMHQA owing to their capabilities including planning, reasoning, and utilizing tools. However, LLMs may generate off-topic answers when attempting to solve ODMHQA, namely the generated answers are irrelevant to the original questions. This issue of off-topic answers accounts for approximately one-third of incorrect answers, yet remains underexplored despite its significance. To alleviate this issue, we propose the Discriminate->Re-Compose->Re- Solve->Re-Decompose (Dr3) mechanism. Specifically, the Discriminator leverages the intrinsic capabilities of LLMs to judge whether the generated answers are off-topic. In cases where an off-topic answer is detected, the Corrector performs step-wise revisions along the reversed reasoning chain (Re-Compose->Re-Solve->Re-Decompose) until the final answer becomes on-topic. Experimental results on the HotpotQA and 2WikiMultiHopQA datasets demonstrate that our Dr3 mechanism considerably reduces the occurrence of off-topic answers in ODMHQA by nearly 13%, improving the performance in Exact Match (EM) by nearly 3% compared to the baseline method without the Dr3 mechanism.
Robust Representation Learning for Unified Online Top-K Recommendation
Oct 24, 2023



In large-scale industrial e-commerce, the efficiency of an online recommendation system is crucial in delivering highly relevant item/content advertising that caters to diverse business scenarios. However, most existing studies focus solely on item advertising, neglecting the significance of content advertising. This oversight results in inconsistencies within the multi-entity structure and unfair retrieval. Furthermore, the challenge of retrieving top-k advertisements from multi-entity advertisements across different domains adds to the complexity. Recent research proves that user-entity behaviors within different domains exhibit characteristics of differentiation and homogeneity. Therefore, the multi-domain matching models typically rely on the hybrid-experts framework with domain-invariant and domain-specific representations. Unfortunately, most approaches primarily focus on optimizing the combination mode of different experts, failing to address the inherent difficulty in optimizing the expert modules themselves. The existence of redundant information across different domains introduces interference and competition among experts, while the distinct learning objectives of each domain lead to varying optimization challenges among experts. To tackle these issues, we propose robust representation learning for the unified online top-k recommendation. Our approach constructs unified modeling in entity space to ensure data fairness. The robust representation learning employs domain adversarial learning and multi-view wasserstein distribution learning to learn robust representations. Moreover, the proposed method balances conflicting objectives through the homoscedastic uncertainty weights and orthogonality constraints. Various experiments validate the effectiveness and rationality of our proposed method, which has been successfully deployed online to serve real business scenarios.
DRL4Route: A Deep Reinforcement Learning Framework for Pick-up and Delivery Route Prediction
Jul 30, 2023



Pick-up and Delivery Route Prediction (PDRP), which aims to estimate the future service route of a worker given his current task pool, has received rising attention in recent years. Deep neural networks based on supervised learning have emerged as the dominant model for the task because of their powerful ability to capture workers' behavior patterns from massive historical data. Though promising, they fail to introduce the non-differentiable test criteria into the training process, leading to a mismatch in training and test criteria. Which considerably trims down their performance when applied in practical systems. To tackle the above issue, we present the first attempt to generalize Reinforcement Learning (RL) to the route prediction task, leading to a novel RL-based framework called DRL4Route. It combines the behavior-learning abilities of previous deep learning models with the non-differentiable objective optimization ability of reinforcement learning. DRL4Route can serve as a plug-and-play component to boost the existing deep learning models. Based on the framework, we further implement a model named DRL4Route-GAE for PDRP in logistic service. It follows the actor-critic architecture which is equipped with a Generalized Advantage Estimator that can balance the bias and variance of the policy gradient estimates, thus achieving a more optimal policy. Extensive offline experiments and the online deployment show that DRL4Route-GAE improves Location Square Deviation (LSD) by 0.9%-2.7%, and Accuracy@3 (ACC@3) by 2.4%-3.2% over existing methods on the real-world dataset.
LaDe: The First Comprehensive Last-mile Delivery Dataset from Industry
Jun 19, 2023



Real-world last-mile delivery datasets are crucial for research in logistics, supply chain management, and spatio-temporal data mining. Despite a plethora of algorithms developed to date, no widely accepted, publicly available last-mile delivery dataset exists to support research in this field. In this paper, we introduce \texttt{LaDe}, the first publicly available last-mile delivery dataset with millions of packages from the industry. LaDe has three unique characteristics: (1) Large-scale. It involves 10,677k packages of 21k couriers over 6 months of real-world operation. (2) Comprehensive information. It offers original package information, such as its location and time requirements, as well as task-event information, which records when and where the courier is while events such as task-accept and task-finish events happen. (3) Diversity. The dataset includes data from various scenarios, including package pick-up and delivery, and from multiple cities, each with its unique spatio-temporal patterns due to their distinct characteristics such as populations. We verify LaDe on three tasks by running several classical baseline models per task. We believe that the large-scale, comprehensive, diverse feature of LaDe can offer unparalleled opportunities to researchers in the supply chain community, data mining community, and beyond. The dataset homepage is publicly available at https://huggingface.co/datasets/Cainiao-AI/LaDe.