 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleDoc: Scaling LLM-based Predicates over Large Document Collections
Sep 16, 2025Predicates are foundational components in data analysis systems. However, modern workloads increasingly involve unstructured documents, which demands semantic understanding, beyond traditional value-based predicates. Given enormous documents and ad-hoc queries, while Large Language Models (LLMs) demonstrate powerful zero-shot capabilities, their high inference cost leads to unacceptable overhead. Therefore, we introduce \textsc{ScaleDoc}, a novel system that addresses this by decoupling predicate execution into an offline representation phase and an optimized online filtering phase. In the offline phase, \textsc{ScaleDoc} leverages a LLM to generate semantic representations for each document. Online, for each query, it trains a lightweight proxy model on these representations to filter the majority of documents, forwarding only the ambiguous cases to the LLM for final decision. Furthermore, \textsc{ScaleDoc} proposes two core innovations to achieve significant efficiency: (1) a contrastive-learning-based framework that trains the proxy model to generate reliable predicating decision scores; (2) an adaptive cascade mechanism that determines the effective filtering policy while meeting specific accuracy targets. Our evaluations across three datasets demonstrate that \textsc{ScaleDoc} achieves over a 2$\times$ end-to-end speedup and reduces expensive LLM invocations by up to 85\%, making large-scale semantic analysis practical and efficient.
ROAD: Responsibility-Oriented Reward Design for Reinforcement Learning in Autonomous Driving
May 30, 2025Reinforcement learning (RL) in autonomous driving employs a trial-and-error mechanism, enhancing robustness in unpredictable environments. However, crafting effective reward functions remains challenging, as conventional approaches rely heavily on manual design and demonstrate limited efficacy in complex scenarios. To address this issue, this study introduces a responsibility-oriented reward function that explicitly incorporates traffic regulations into the RL framework. Specifically, we introduced a Traffic Regulation Knowledge Graph and leveraged Vision-Language Models alongside Retrieval-Augmented Generation techniques to automate reward assignment. This integration guides agents to adhere strictly to traffic laws, thus minimizing rule violations and optimizing decision-making performance in diverse driving conditions. Experimental validations demonstrate that the proposed methodology significantly improves the accuracy of assigning accident responsibilities and effectively reduces the agent's liability in traffic incidents.
TabGen-ICL: Residual-Aware In-Context Example Selection for Tabular Data Generation
Feb 23, 2025Large Language models (LLMs) have achieved encouraging results in tabular data generation. However, existing approaches require fine-tuning, which is computationally expensive. This paper explores an alternative: prompting a fixed LLM with in-context examples. We observe that using randomly selected in-context examples hampers the LLM's performance, resulting in sub-optimal generation quality. To address this, we propose a novel in-context learning framework: TabGen-ICL, to enhance the in-context learning ability of LLMs for tabular data generation. TabGen-ICL operates iteratively, retrieving a subset of real samples that represent the residual between currently generated samples and true data distributions. This approach serves two purposes: locally, it provides more effective in-context learning examples for the LLM in each iteration; globally, it progressively narrows the gap between generated and real data. Extensive experiments on five real-world tabular datasets demonstrate that TabGen-ICL significantly outperforms the random selection strategy. Specifically, it reduces the error rate by a margin of $3.5\%-42.2\%$ on fidelity metrics. We demonstrate for the first time that prompting a fixed LLM can yield high-quality synthetic tabular data. The code is provided in the \href{https://github.com/fangliancheng/TabGEN-ICL}{link}.
Emerging Microelectronic Materials by Design: Navigating Combinatorial Design Space with Scarce and Dispersed Data
Dec 23, 2024



The increasing demands of sustainable energy, electronics, and biomedical applications call for next-generation functional materials with unprecedented properties. Of particular interest are emerging materials that display exceptional physical properties, making them promising candidates in energy-efficient microelectronic devices. As the conventional Edisonian approach becomes significantly outpaced by growing societal needs, emerging computational modeling and machine learning (ML) methods are employed for the rational design of materials. However, the complex physical mechanisms, cost of first-principles calculations, and the dispersity and scarcity of data pose challenges to both physics-based and data-driven materials modeling. Moreover, the combinatorial composition-structure design space is high-dimensional and often disjoint, making design optimization nontrivial. In this Account, we review a team effort toward establishing a framework that integrates data-driven and physics-based methods to address these challenges and accelerate materials design. We begin by presenting our integrated materials design framework and its three components in a general context. We then provide an example of applying this materials design framework to metal-insulator transition (MIT) materials, a specific type of emerging materials with practical importance in next-generation memory technologies. We identify multiple new materials which may display this property and propose pathways for their synthesis. Finally, we identify some outstanding challenges in data-driven materials design, such as materials data quality issues and property-performance mismatch. We seek to raise awareness of these overlooked issues hindering materials design, thus stimulating efforts toward developing methods to mitigate the gaps.
TabDiff: a Multi-Modal Diffusion Model for Tabular Data Generation
Oct 29, 2024



Synthesizing high-quality tabular data is an important topic in many data science tasks, ranging from dataset augmentation to privacy protection. However, developing expressive generative models for tabular data is challenging due to its inherent heterogeneous data types, complex inter-correlations, and intricate column-wise distributions. In this paper, we introduce TabDiff, a joint diffusion framework that models all multi-modal distributions of tabular data in one model. Our key innovation is the development of a joint continuous-time diffusion process for numerical and categorical data, where we propose feature-wise learnable diffusion processes to counter the high disparity of different feature distributions. TabDiff is parameterized by a transformer handling different input types, and the entire framework can be efficiently optimized in an end-to-end fashion. We further introduce a multi-modal stochastic sampler to automatically correct the accumulated decoding error during sampling, and propose classifier-free guidance for conditional missing column value imputation. Comprehensive experiments on seven datasets demonstrate that TabDiff achieves superior average performance over existing competitive baselines across all eight metrics, with up to $22.5\%$ improvement over the state-of-the-art model on pair-wise column correlation estimations. Code is available at https://github.com/MinkaiXu/TabDiff.
Diffusion-nested Auto-Regressive Synthesis of Heterogeneous Tabular Data
Oct 28, 2024Autoregressive models are predominant in natural language generation, while their application in tabular data remains underexplored. We posit that this can be attributed to two factors: 1) tabular data contains heterogeneous data type, while the autoregressive model is primarily designed to model discrete-valued data; 2) tabular data is column permutation-invariant, requiring a generation model to generate columns in arbitrary order. This paper proposes a Diffusion-nested Autoregressive model (TabDAR) to address these issues. To enable autoregressive methods for continuous columns, TabDAR employs a diffusion model to parameterize the conditional distribution of continuous features. To ensure arbitrary generation order, TabDAR resorts to masked transformers with bi-directional attention, which simulate various permutations of column order, hence enabling it to learn the conditional distribution of a target column given an arbitrary combination of other columns. These designs enable TabDAR to not only freely handle heterogeneous tabular data but also support convenient and flexible unconditional/conditional sampling. We conduct extensive experiments on ten datasets with distinct properties, and the proposed TabDAR outperforms previous state-of-the-art methods by 18% to 45% on eight metrics across three distinct aspects.
Multi-Continental Healthcare Modelling Using Blockchain-Enabled Federated Learning
Oct 23, 2024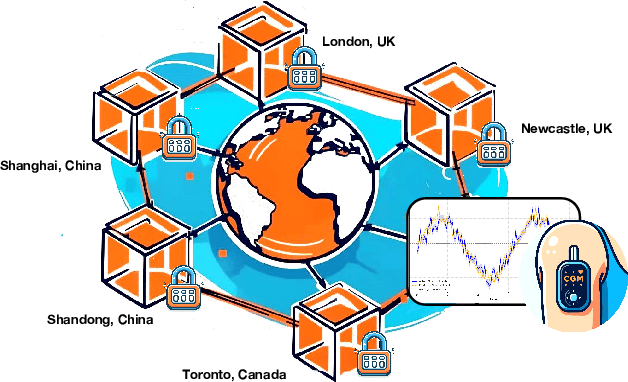
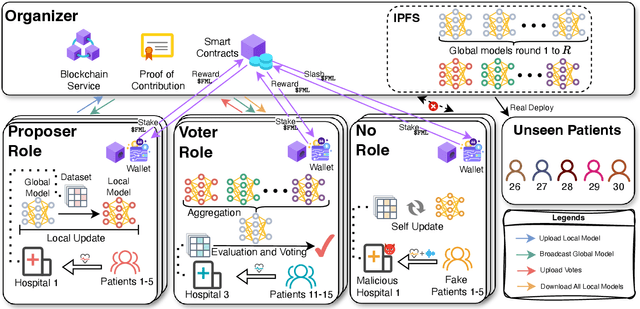
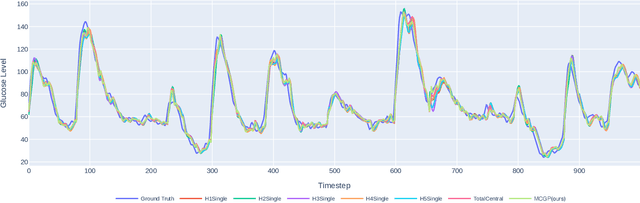
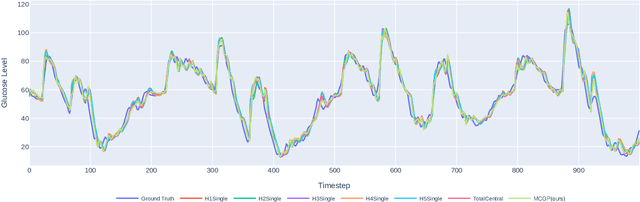
One of the biggest challenges of building artificial intelligence (AI) model in healthcare area is the data sharing. Since healthcare data is private, sensitive, and heterogeneous, collecting sufficient data for modelling is exhausted, costly, and sometimes impossible. In this paper, we propose a framework for global healthcare modelling using datasets from multi-continents (Europe, North America and Asia) while without sharing the local datasets, and choose glucose management as a study model to verify its effectiveness. Technically, blockchain-enabled federated learning is implemented with adaption to make it meet with the privacy and safety requirements of healthcare data, meanwhile rewards honest participation and penalize malicious activities using its on-chain incentive mechanism. Experimental results show that the proposed framework is effective, efficient, and privacy preserved. Its prediction accuracy is much better than the models trained from limited personal data and is similar to, and even slightly better than, the results from a centralized dataset. This work paves the way for international collaborations on healthcare projects, where additional data is crucial for reducing bias and providing benefits to humanity.
SGFormer: Single-Layer Graph Transformers with Approximation-Free Linear Complexity
Sep 13, 2024



Learning representations on large graphs is a long-standing challenge due to the inter-dependence nature. Transformers recently have shown promising performance on small graphs thanks to its global attention for capturing all-pair interactions beyond observed structures. Existing approaches tend to inherit the spirit of Transformers in language and vision tasks, and embrace complicated architectures by stacking deep attention-based propagation layers. In this paper, we attempt to evaluate the necessity of adopting multi-layer attentions in Transformers on graphs, which considerably restricts the efficiency. Specifically, we analyze a generic hybrid propagation layer, comprised of all-pair attention and graph-based propagation, and show that multi-layer propagation can be reduced to one-layer propagation, with the same capability for representation learning. It suggests a new technical path for building powerful and efficient Transformers on graphs, particularly through simplifying model architectures without sacrificing expressiveness. As exemplified by this work, we propose a Simplified Single-layer Graph Transformers (SGFormer), whose main component is a single-layer global attention that scales linearly w.r.t. graph sizes and requires none of any approximation for accommodating all-pair interactions. Empirically, SGFormer successfully scales to the web-scale graph ogbn-papers100M, yielding orders-of-magnitude inference acceleration over peer Transformers on medium-sized graphs, and demonstrates competitiveness with limited labeled data.
Do Graph Neural Networks Work for High Entropy Alloys?
Aug 29, 2024

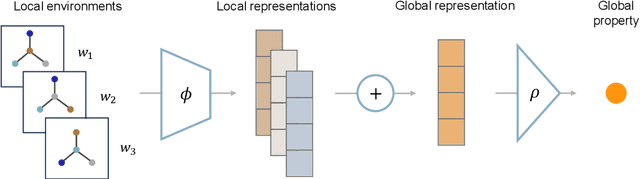
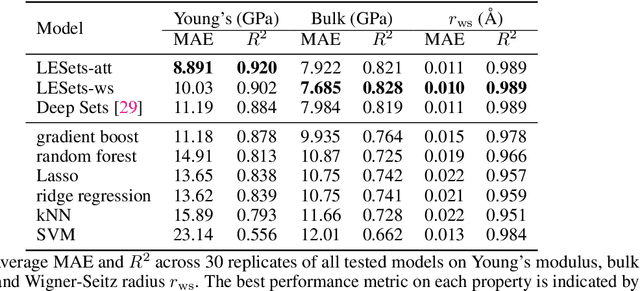
Graph neural networks (GNNs) have excelled in predictive modeling for both crystals and molecules, owing to the expressiveness of graph representations. High-entropy alloys (HEAs), however, lack chemical long-range order, limiting the applicability of current graph representations. To overcome this challenge, we propose a representation of HEAs as a collection of local environment (LE) graphs. Based on this representation, we introduce the LESets machine learning model, an accurate, interpretable GNN for HEA property prediction. We demonstrate the accuracy of LESets in modeling the mechanical properties of quaternary HEAs. Through analyses and interpretation, we further extract insights into the modeling and design of HEAs. In a broader sense, LESets extends the potential applicability of GNNs to disordered materials with combinatorial complexity formed by diverse constituents and their flexible configurations.
Kraken: Inherently Parallel Transformers For Efficient Multi-Device Inference
Aug 14, 2024



Large Transformer networks are increasingly used in settings where low inference latency can improve the end-user experience and enable new applications. However, autoregressive inference is resource intensive and requires parallelism for efficiency. Parallelism introduces collective communication that is both expensive and represents a phase when hardware resources are underutilized. Towards mitigating this, Kraken is an evolution of the standard Transformer architecture that is designed to complement existing tensor parallelism schemes for efficient inference on multi-device systems. By introducing a fixed degree of intra-layer model parallelism, the architecture allows collective operations to be overlapped with compute, decreasing latency and increasing hardware utilization. When trained on OpenWebText, Kraken models reach a similar perplexity as standard Transformers while also preserving their language modeling capabilities when evaluated on the SuperGLUE benchmark. Importantly, when tested on multi-GPU systems using TensorRT-LLM engines, Kraken speeds up Time To First Token by a mean of 35.6% across a range of model sizes, context lengths, and degrees of tensor parallelism.