 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivergence Minimization Preference Optimization for Diffusion Model Alignment
Jul 10, 2025Diffusion models have achieved remarkable success in generating realistic and versatile images from text prompts. Inspired by the recent advancements of language models, there is an increasing interest in further improving the models by aligning with human preferences. However, we investigate alignment from a divergence minimization perspective and reveal that existing preference optimization methods are typically trapped in suboptimal mean-seeking optimization. In this paper, we introduce Divergence Minimization Preference Optimization (DMPO), a novel and principled method for aligning diffusion models by minimizing reverse KL divergence, which asymptotically enjoys the same optimization direction as original RL. We provide rigorous analysis to justify the effectiveness of DMPO and conduct comprehensive experiments to validate its empirical strength across both human evaluations and automatic metrics. Our extensive results show that diffusion models fine-tuned with DMPO can consistently outperform or match existing techniques, specifically outperforming all existing diffusion alignment baselines by at least 64.6% in PickScore across all evaluation datasets, demonstrating the method's superiority in aligning generative behavior with desired outputs. Overall, DMPO unlocks a robust and elegant pathway for preference alignment, bridging principled theory with practical performance in diffusion models.
3D Interaction Geometric Pre-training for Molecular Relational Learning
Dec 04, 2024Molecular Relational Learning (MRL) is a rapidly growing field that focuses on understanding the interaction dynamics between molecules, which is crucial for applications ranging from catalyst engineering to drug discovery. Despite recent progress, earlier MRL approaches are limited to using only the 2D topological structure of molecules, as obtaining the 3D interaction geometry remains prohibitively expensive. This paper introduces a novel 3D geometric pre-training strategy for MRL (3DMRL) that incorporates a 3D virtual interaction environment, overcoming the limitations of costly traditional quantum mechanical calculation methods. With the constructed 3D virtual interaction environment, 3DMRL trains 2D MRL model to learn the overall 3D geometric information of molecular interaction through contrastive learning. Moreover, fine-grained interaction between molecules is learned through force prediction loss, which is crucial in understanding the wide range of molecular interaction processes. Extensive experiments on various tasks using real-world datasets, including out-of-distribution and extrapolation scenarios, demonstrate the effectiveness of 3DMRL, showing up to a 24.93\% improvement in performance across 40 tasks.
TabDiff: a Multi-Modal Diffusion Model for Tabular Data Generation
Oct 29, 2024



Synthesizing high-quality tabular data is an important topic in many data science tasks, ranging from dataset augmentation to privacy protection. However, developing expressive generative models for tabular data is challenging due to its inherent heterogeneous data types, complex inter-correlations, and intricate column-wise distributions. In this paper, we introduce TabDiff, a joint diffusion framework that models all multi-modal distributions of tabular data in one model. Our key innovation is the development of a joint continuous-time diffusion process for numerical and categorical data, where we propose feature-wise learnable diffusion processes to counter the high disparity of different feature distributions. TabDiff is parameterized by a transformer handling different input types, and the entire framework can be efficiently optimized in an end-to-end fashion. We further introduce a multi-modal stochastic sampler to automatically correct the accumulated decoding error during sampling, and propose classifier-free guidance for conditional missing column value imputation. Comprehensive experiments on seven datasets demonstrate that TabDiff achieves superior average performance over existing competitive baselines across all eight metrics, with up to $22.5\%$ improvement over the state-of-the-art model on pair-wise column correlation estimations. Code is available at https://github.com/MinkaiXu/TabDiff.
$f$-PO: Generalizing Preference Optimization with $f$-divergence Minimization
Oct 29, 2024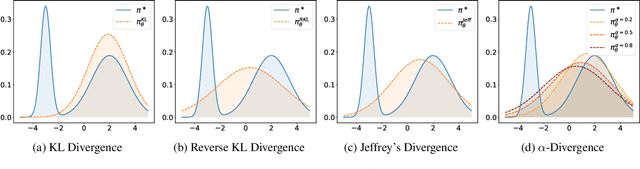

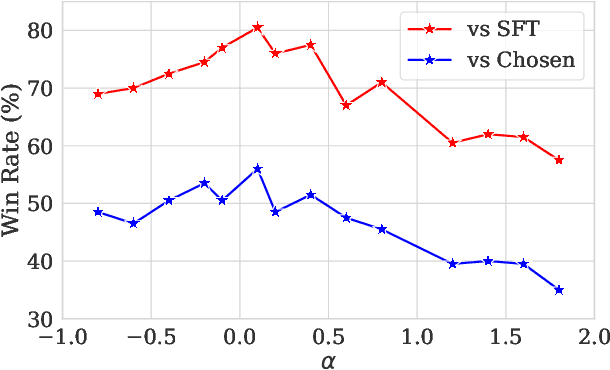

Preference optimization has made significant progress recently, with numerous methods developed to align language models with human preferences. This paper introduces $f$-divergence Preference Optimization ($f$-PO), a novel framework that generalizes and extends existing approaches. $f$-PO minimizes $f$-divergences between the optimized policy and the optimal policy, encompassing a broad family of alignment methods using various divergences. Our approach unifies previous algorithms like DPO and EXO, while offering new variants through different choices of $f$-divergences. We provide theoretical analysis of $f$-PO's properties and conduct extensive experiments on state-of-the-art language models using benchmark datasets. Results demonstrate $f$-PO's effectiveness across various tasks, achieving superior performance compared to existing methods on popular benchmarks such as AlpacaEval 2, Arena-Hard, and MT-Bench. Additionally, we present ablation studies exploring the impact of different $f$-divergences, offering insights into the trade-offs between regularization and performance in offline preference optimization. Our work contributes both practical algorithms and theoretical understanding to the field of language model alignment. Code is available at https://github.com/MinkaiXu/fPO.
Energy-Based Diffusion Language Models for Text Generation
Oct 28, 2024


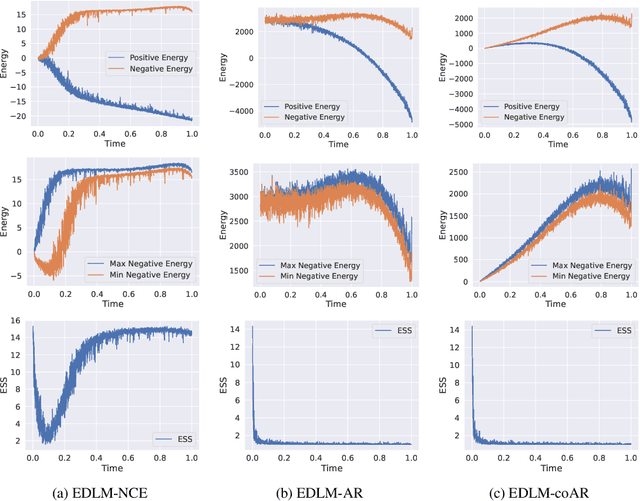
Despite remarkable progress in autoregressive language models, alternative generative paradigms beyond left-to-right generation are still being actively explored. Discrete diffusion models, with the capacity for parallel generation, have recently emerged as a promising alternative. Unfortunately, these models still underperform the autoregressive counterparts, with the performance gap increasing when reducing the number of sampling steps. Our analysis reveals that this degradation is a consequence of an imperfect approximation used by diffusion models. In this work, we propose Energy-based Diffusion Language Model (EDLM), an energy-based model operating at the full sequence level for each diffusion step, introduced to improve the underlying approximation used by diffusion models. More specifically, we introduce an EBM in a residual form, and show that its parameters can be obtained by leveraging a pretrained autoregressive model or by finetuning a bidirectional transformer via noise contrastive estimation. We also propose an efficient generation algorithm via parallel important sampling. Comprehensive experiments on language modeling benchmarks show that our model can consistently outperform state-of-the-art diffusion models by a significant margin, and approaches autoregressive models' perplexity. We further show that, without any generation performance drop, our framework offers a 1.3$\times$ sampling speedup over existing diffusion models.
Geometric Trajectory Diffusion Models
Oct 16, 2024
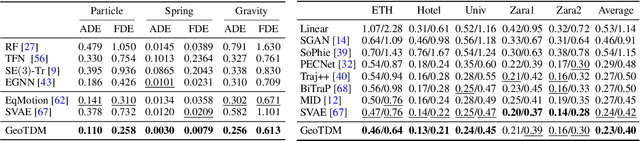

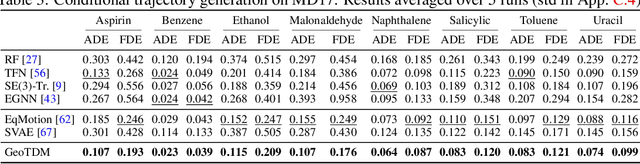
Generative models have shown great promise in generating 3D geometric systems, which is a fundamental problem in many natural science domains such as molecule and protein design. However, existing approaches only operate on static structures, neglecting the fact that physical systems are always dynamic in nature. In this work, we propose geometric trajectory diffusion models (GeoTDM), the first diffusion model for modeling the temporal distribution of 3D geometric trajectories. Modeling such distribution is challenging as it requires capturing both the complex spatial interactions with physical symmetries and temporal correspondence encapsulated in the dynamics. We theoretically justify that diffusion models with equivariant temporal kernels can lead to density with desired symmetry, and develop a novel transition kernel leveraging SE(3)-equivariant spatial convolution and temporal attention. Furthermore, to induce an expressive trajectory distribution for conditional generation, we introduce a generalized learnable geometric prior into the forward diffusion process to enhance temporal conditioning. We conduct extensive experiments on both unconditional and conditional generation in various scenarios, including physical simulation, molecular dynamics, and pedestrian motion. Empirical results on a wide suite of metrics demonstrate that GeoTDM can generate realistic geometric trajectories with significantly higher quality.
SuperCorrect: Supervising and Correcting Language Models with Error-Driven Insights
Oct 11, 2024



Large language models (LLMs) like GPT-4, PaLM, and LLaMA have shown significant improvements in various reasoning tasks. However, smaller models such as Llama-3-8B and DeepSeekMath-Base still struggle with complex mathematical reasoning because they fail to effectively identify and correct reasoning errors. Recent reflection-based methods aim to address these issues by enabling self-reflection and self-correction, but they still face challenges in independently detecting errors in their reasoning steps. To overcome these limitations, we propose SuperCorrect, a novel two-stage framework that uses a large teacher model to supervise and correct both the reasoning and reflection processes of a smaller student model. In the first stage, we extract hierarchical high-level and detailed thought templates from the teacher model to guide the student model in eliciting more fine-grained reasoning thoughts. In the second stage, we introduce cross-model collaborative direct preference optimization (DPO) to enhance the self-correction abilities of the student model by following the teacher's correction traces during training. This cross-model DPO approach teaches the student model to effectively locate and resolve erroneous thoughts with error-driven insights from the teacher model, breaking the bottleneck of its thoughts and acquiring new skills and knowledge to tackle challenging problems. Extensive experiments consistently demonstrate our superiority over previous methods. Notably, our SuperCorrect-7B model significantly surpasses powerful DeepSeekMath-7B by 7.8%/5.3% and Qwen2.5-Math-7B by 15.1%/6.3% on MATH/GSM8K benchmarks, achieving new SOTA performance among all 7B models. Code: https://github.com/YangLing0818/SuperCorrect-llm
Trans4D: Realistic Geometry-Aware Transition for Compositional Text-to-4D Synthesis
Oct 09, 2024Recent advances in diffusion models have demonstrated exceptional capabilities in image and video generation, further improving the effectiveness of 4D synthesis. Existing 4D generation methods can generate high-quality 4D objects or scenes based on user-friendly conditions, benefiting the gaming and video industries. However, these methods struggle to synthesize significant object deformation of complex 4D transitions and interactions within scenes. To address this challenge, we propose Trans4D, a novel text-to-4D synthesis framework that enables realistic complex scene transitions. Specifically, we first use multi-modal large language models (MLLMs) to produce a physic-aware scene description for 4D scene initialization and effective transition timing planning. Then we propose a geometry-aware 4D transition network to realize a complex scene-level 4D transition based on the plan, which involves expressive geometrical object deformation. Extensive experiments demonstrate that Trans4D consistently outperforms existing state-of-the-art methods in generating 4D scenes with accurate and high-quality transitions, validating its effectiveness. Code: https://github.com/YangLing0818/Trans4D
TFG: Unified Training-Free Guidance for Diffusion Models
Sep 24, 2024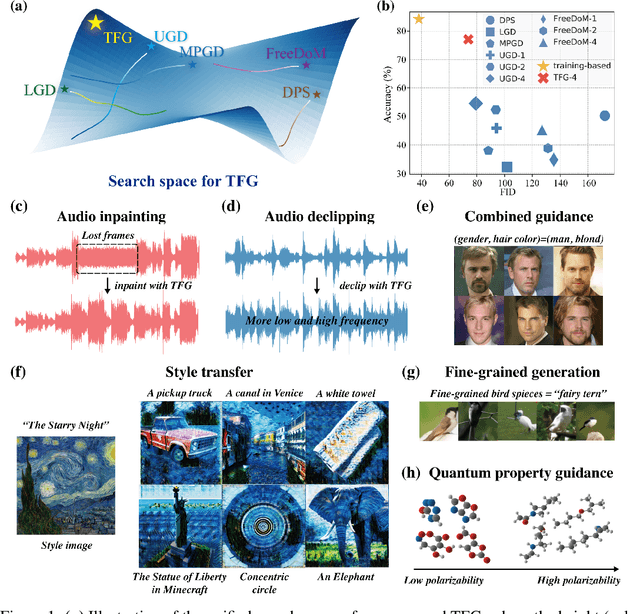
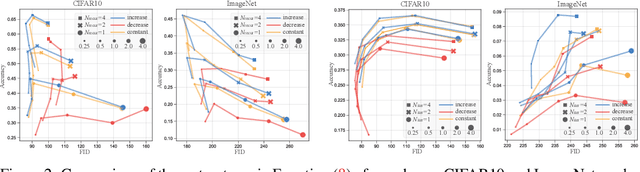

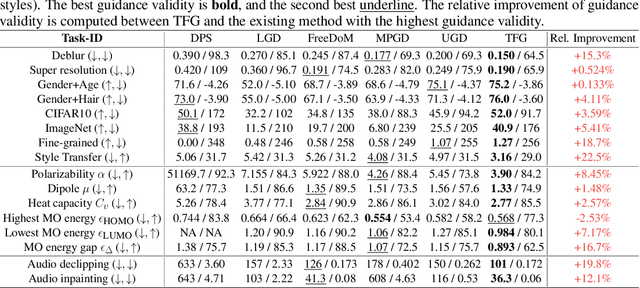
Given an unconditional diffusion model and a predictor for a target property of interest (e.g., a classifier), the goal of training-free guidance is to generate samples with desirable target properties without additional training. Existing methods, though effective in various individual applications, often lack theoretical grounding and rigorous testing on extensive benchmarks. As a result, they could even fail on simple tasks, and applying them to a new problem becomes unavoidably difficult. This paper introduces a novel algorithmic framework encompassing existing methods as special cases, unifying the study of training-free guidance into the analysis of an algorithm-agnostic design space. Via theoretical and empirical investigation, we propose an efficient and effective hyper-parameter searching strategy that can be readily applied to any downstream task. We systematically benchmark across 7 diffusion models on 16 tasks with 40 targets, and improve performance by 8.5% on average. Our framework and benchmark offer a solid foundation for conditional generation in a training-free manner.
The Heterophilic Graph Learning Handbook: Benchmarks, Models, Theoretical Analysis, Applications and Challenges
Jul 12, 2024



Homophily principle, \ie{} nodes with the same labels or similar attributes are more likely to be connected, has been commonly believed to be the main reason for the superiority of Graph Neural Networks (GNNs) over traditional Neural Networks (NNs) on graph-structured data, especially on node-level tasks. However, recent work has identified a non-trivial set of datasets where GNN's performance compared to the NN's is not satisfactory. Heterophily, i.e. low homophily, has been considered the main cause of this empirical observation. People have begun to revisit and re-evaluate most existing graph models, including graph transformer and its variants, in the heterophily scenario across various kinds of graphs, e.g. heterogeneous graphs, temporal graphs and hypergraphs. Moreover, numerous graph-related applications are found to be closely related to the heterophily problem. In the past few years, considerable effort has been devoted to studying and addressing the heterophily issue. In this survey, we provide a comprehensive review of the latest progress on heterophilic graph learning, including an extensive summary of benchmark datasets and evaluation of homophily metrics on synthetic graphs, meticulous classification of the most updated supervised and unsupervised learning methods, thorough digestion of the theoretical analysis on homophily/heterophily, and broad exploration of the heterophily-related applications. Notably, through detailed experiments, we are the first to categorize benchmark heterophilic datasets into three sub-categories: malignant, benign and ambiguous heterophily. Malignant and ambiguous datasets are identified as the real challenging datasets to test the effectiveness of new models on the heterophily challenge. Finally, we propose several challenges and future directions for heterophilic graph representation learning.