 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Bias in Locally Constrained Decoding via Tractable Proposals
Jun 01, 2026Generations from large language models often fail to conform to desired constraints such as JSON schema. Existing locally constrained decoding (LCD) approaches enforce constraints by myopically masking out next tokens, resulting in biased sampling and degradation in performance. Recent work uses sequential Monte Carlo (SMC) methods to mitigate such biases, but designing effective proposal distributions or potential functions remains a key challenge. In this work, we propose a generic approach to construct proposals and potentials for SMC sampling from $p_{\mathrm{lm}}( \cdot \mid \mathrm{constraint})$. First, we show that constraints specified as finite automata can be tensorized for efficient execution on GPUs, which we use to construct globally constrained decoding (GCD) proposals. In addition, leveraging the fact that tensorized finite automata share the same circuit structure as hidden Markov models, we circuit-multiply them to obtain the probabilistic GCD (P-GCD) proposals encoding both logical and probabilistic information about the target distributions. We evaluate (P-)GCD on the tasks of function calling, keyword-based generation, and SQL generation. Experiments show that under the same SMC sampling setup, compared to LCD proposals, (P-)GCD converges faster to the target distribution with significantly fewer particles.
Divergence Minimization Preference Optimization for Diffusion Model Alignment
Jul 10, 2025Diffusion models have achieved remarkable success in generating realistic and versatile images from text prompts. Inspired by the recent advancements of language models, there is an increasing interest in further improving the models by aligning with human preferences. However, we investigate alignment from a divergence minimization perspective and reveal that existing preference optimization methods are typically trapped in suboptimal mean-seeking optimization. In this paper, we introduce Divergence Minimization Preference Optimization (DMPO), a novel and principled method for aligning diffusion models by minimizing reverse KL divergence, which asymptotically enjoys the same optimization direction as original RL. We provide rigorous analysis to justify the effectiveness of DMPO and conduct comprehensive experiments to validate its empirical strength across both human evaluations and automatic metrics. Our extensive results show that diffusion models fine-tuned with DMPO can consistently outperform or match existing techniques, specifically outperforming all existing diffusion alignment baselines by at least 64.6% in PickScore across all evaluation datasets, demonstrating the method's superiority in aligning generative behavior with desired outputs. Overall, DMPO unlocks a robust and elegant pathway for preference alignment, bridging principled theory with practical performance in diffusion models.
Scaling Probabilistic Circuits via Monarch Matrices
Jun 14, 2025Probabilistic Circuits (PCs) are tractable representations of probability distributions allowing for exact and efficient computation of likelihoods and marginals. Recent advancements have improved the scalability of PCs either by leveraging their sparse properties or through the use of tensorized operations for better hardware utilization. However, no existing method fully exploits both aspects simultaneously. In this paper, we propose a novel sparse and structured parameterization for the sum blocks in PCs. By replacing dense matrices with sparse Monarch matrices, we significantly reduce the memory and computation costs, enabling unprecedented scaling of PCs. From a theory perspective, our construction arises naturally from circuit multiplication; from a practical perspective, compared to previous efforts on scaling up tractable probabilistic models, our approach not only achieves state-of-the-art generative modeling performance on challenging benchmarks like Text8, LM1B and ImageNet, but also demonstrates superior scaling behavior, achieving the same performance with substantially less compute as measured by the number of floating-point operations (FLOPs) during training.
Personalized Preference Fine-tuning of Diffusion Models
Jan 11, 2025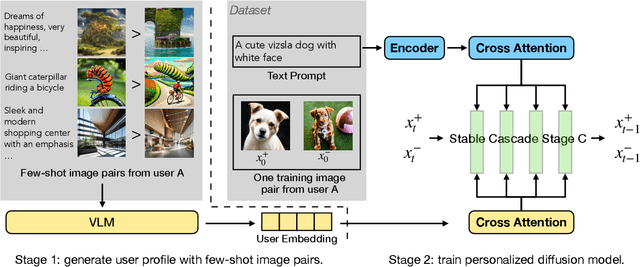
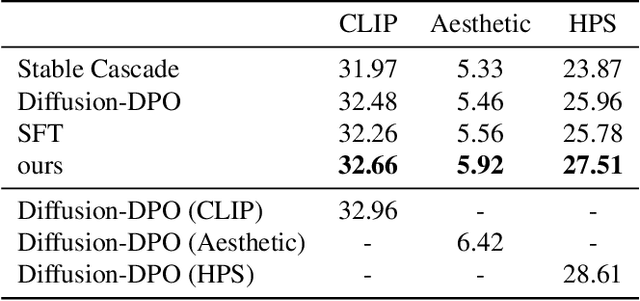
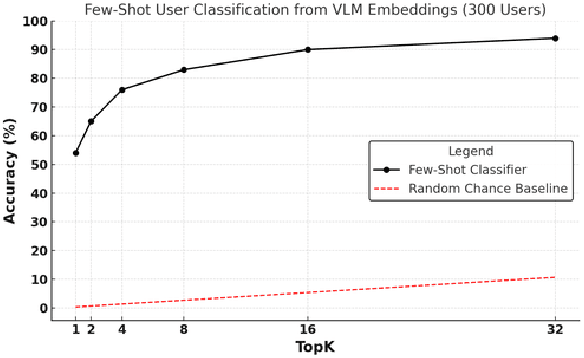

RLHF techniques like DPO can significantly improve the generation quality of text-to-image diffusion models. However, these methods optimize for a single reward that aligns model generation with population-level preferences, neglecting the nuances of individual users' beliefs or values. This lack of personalization limits the efficacy of these models. To bridge this gap, we introduce PPD, a multi-reward optimization objective that aligns diffusion models with personalized preferences. With PPD, a diffusion model learns the individual preferences of a population of users in a few-shot way, enabling generalization to unseen users. Specifically, our approach (1) leverages a vision-language model (VLM) to extract personal preference embeddings from a small set of pairwise preference examples, and then (2) incorporates the embeddings into diffusion models through cross attention. Conditioning on user embeddings, the text-to-image models are fine-tuned with the DPO objective, simultaneously optimizing for alignment with the preferences of multiple users. Empirical results demonstrate that our method effectively optimizes for multiple reward functions and can interpolate between them during inference. In real-world user scenarios, with as few as four preference examples from a new user, our approach achieves an average win rate of 76\% over Stable Cascade, generating images that more accurately reflect specific user preferences.
Structure-Based Drug Design via 3D Molecular Generative Pre-training and Sampling
Feb 22, 2024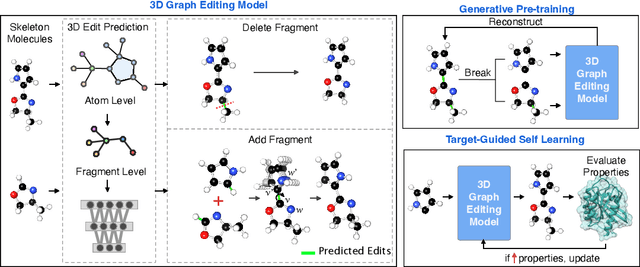
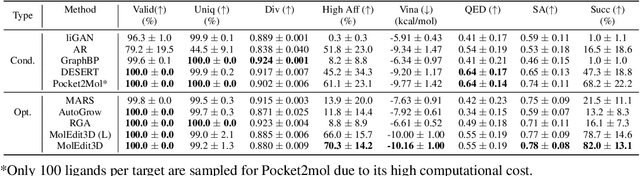

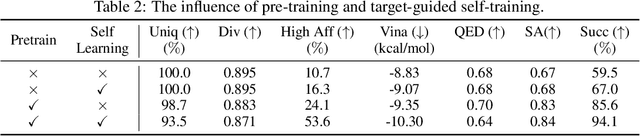
Structure-based drug design aims at generating high affinity ligands with prior knowledge of 3D target structures. Existing methods either use conditional generative model to learn the distribution of 3D ligands given target binding sites, or iteratively modify molecules to optimize a structure-based activity estimator. The former is highly constrained by data quantity and quality, which leaves optimization-based approaches more promising in practical scenario. However, existing optimization-based approaches choose to edit molecules in 2D space, and use molecular docking to estimate the activity using docking predicted 3D target-ligand complexes. The misalignment between the action space and the objective hinders the performance of these models, especially for those employ deep learning for acceleration. In this work, we propose MolEdit3D to combine 3D molecular generation with optimization frameworks. We develop a novel 3D graph editing model to generate molecules using fragments, and pre-train this model on abundant 3D ligands for learning target-independent properties. Then we employ a target-guided self-learning strategy to improve target-related properties using self-sampled molecules. MolEdit3D achieves state-of-the-art performance on majority of the evaluation metrics, and demonstrate strong capability of capturing both target-dependent and -independent properties.
Diffusion Model Alignment Using Direct Preference Optimization
Nov 21, 2023



Large language models (LLMs) are fine-tuned using human comparison data with Reinforcement Learning from Human Feedback (RLHF) methods to make them better aligned with users' preferences. In contrast to LLMs, human preference learning has not been widely explored in text-to-image diffusion models; the best existing approach is to fine-tune a pretrained model using carefully curated high quality images and captions to improve visual appeal and text alignment. We propose Diffusion-DPO, a method to align diffusion models to human preferences by directly optimizing on human comparison data. Diffusion-DPO is adapted from the recently developed Direct Preference Optimization (DPO), a simpler alternative to RLHF which directly optimizes a policy that best satisfies human preferences under a classification objective. We re-formulate DPO to account for a diffusion model notion of likelihood, utilizing the evidence lower bound to derive a differentiable objective. Using the Pick-a-Pic dataset of 851K crowdsourced pairwise preferences, we fine-tune the base model of the state-of-the-art Stable Diffusion XL (SDXL)-1.0 model with Diffusion-DPO. Our fine-tuned base model significantly outperforms both base SDXL-1.0 and the larger SDXL-1.0 model consisting of an additional refinement model in human evaluation, improving visual appeal and prompt alignment. We also develop a variant that uses AI feedback and has comparable performance to training on human preferences, opening the door for scaling of diffusion model alignment methods.
Scaling Pareto-Efficient Decision Making Via Offline Multi-Objective RL
Apr 30, 2023



The goal of multi-objective reinforcement learning (MORL) is to learn policies that simultaneously optimize multiple competing objectives. In practice, an agent's preferences over the objectives may not be known apriori, and hence, we require policies that can generalize to arbitrary preferences at test time. In this work, we propose a new data-driven setup for offline MORL, where we wish to learn a preference-agnostic policy agent using only a finite dataset of offline demonstrations of other agents and their preferences. The key contributions of this work are two-fold. First, we introduce D4MORL, (D)atasets for MORL that are specifically designed for offline settings. It contains 1.8 million annotated demonstrations obtained by rolling out reference policies that optimize for randomly sampled preferences on 6 MuJoCo environments with 2-3 objectives each. Second, we propose Pareto-Efficient Decision Agents (PEDA), a family of offline MORL algorithms that builds and extends Decision Transformers via a novel preference-and-return-conditioned policy. Empirically, we show that PEDA closely approximates the behavioral policy on the D4MORL benchmark and provides an excellent approximation of the Pareto-front with appropriate conditioning, as measured by the hypervolume and sparsity metrics.
Tractable Control for Autoregressive Language Generation
Apr 18, 2023



Despite the success of autoregressive large language models in text generation, it remains a major challenge to generate text that satisfies complex constraints: sampling from the conditional distribution $\Pr(\text{text} | \alpha)$ is intractable for even the simplest lexical constraints $\alpha$. To overcome this challenge, we propose to use tractable probabilistic models to impose lexical constraints in autoregressive text generation, which we refer to as GeLaTo. To demonstrate the effectiveness of this framework, we use distilled hidden Markov models to control autoregressive generation from GPT2. GeLaTo achieves state-of-the-art performance on CommonGen, a challenging benchmark for constrained text generation, beating a wide range of strong baselines by a large margin. Our work not only opens up new avenues for controlling large language models but also motivates the development of more expressive tractable probabilistic models.
Sparse Probabilistic Circuits via Pruning and Growing
Nov 22, 2022Probabilistic circuits (PCs) are a tractable representation of probability distributions allowing for exact and efficient computation of likelihoods and marginals. There has been significant recent progress on improving the scale and expressiveness of PCs. However, PC training performance plateaus as model size increases. We discover that most capacity in existing large PC structures is wasted: fully-connected parameter layers are only sparsely used. We propose two operations: pruning and growing, that exploit the sparsity of PC structures. Specifically, the pruning operation removes unimportant sub-networks of the PC for model compression and comes with theoretical guarantees. The growing operation increases model capacity by increasing the size of the latent space. By alternatingly applying pruning and growing, we increase the capacity that is meaningfully used, allowing us to significantly scale up PC learning. Empirically, our learner achieves state-of-the-art likelihoods on MNIST-family image datasets and on Penn Tree Bank language data compared to other PC learners and less tractable deep generative models such as flow-based models and variational autoencoders (VAEs).
Group Fairness by Probabilistic Modeling with Latent Fair Decisions
Sep 18, 2020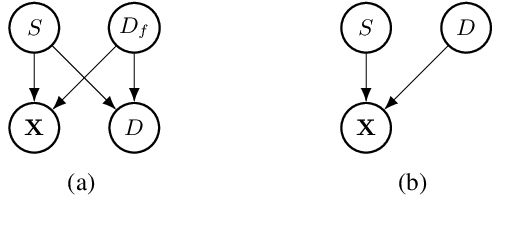
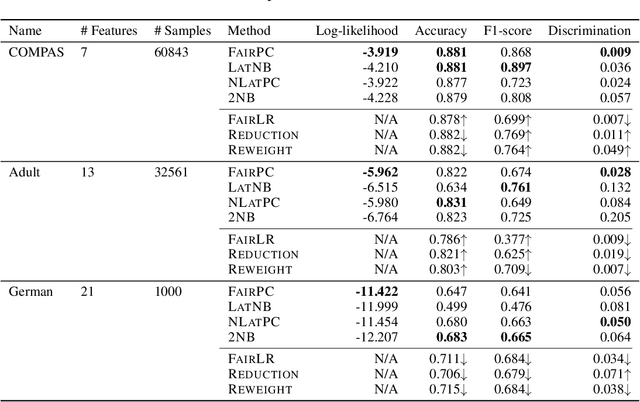
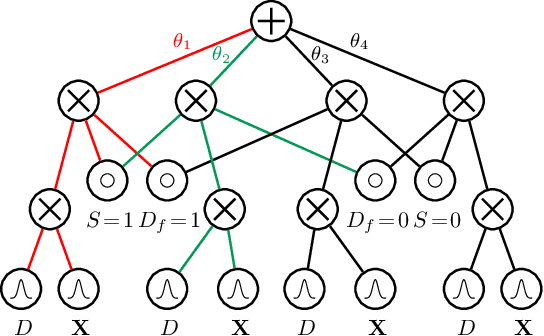

Machine learning systems are increasingly being used to make impactful decisions such as loan applications and criminal justice risk assessments, and as such, ensuring fairness of these systems is critical. This is often challenging as the labels in the data are biased. This paper studies learning fair probability distributions from biased data by explicitly modeling a latent variable that represents a hidden, unbiased label. In particular, we aim to achieve demographic parity by enforcing certain independencies in the learned model. We also show that group fairness guarantees are meaningful only if the distribution used to provide those guarantees indeed captures the real-world data. In order to closely model the data distribution, we employ probabilistic circuits, an expressive and tractable probabilistic model, and propose an algorithm to learn them from incomplete data. We evaluate our approach on a synthetic dataset in which observed labels indeed come from fair labels but with added bias, and demonstrate that the fair labels are successfully retrieved. Moreover, we show on real-world datasets that our approach not only is a better model than existing methods of how the data was generated but also achieves competitive accuracy.