 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRASST: Fast Cross-modal Retrieval-Augmented Simultaneous Speech Translation
Jan 30, 2026Simultaneous speech translation (SST) produces target text incrementally from partial speech input. Recent speech large language models (Speech LLMs) have substantially improved SST quality, yet they still struggle to correctly translate rare and domain-specific terminology. While retrieval augmentation has been effective for terminology translation in machine translation, bringing retrieval to SST is non-trivial: it requires fast and accurate cross-modal (speech-to-text) retrieval under partial, continually arriving input, and the model must decide whether and when to apply retrieved terms during incremental generation. We propose Retrieval-Augmented Simultaneous Speech Translation (RASST), which tightly integrates cross-modal retrieval into the SST pipeline. RASST trains a lightweight speech-text retriever and performs efficient sliding-window retrieval, providing chunkwise terminology hints to the Speech LLM. We further synthesize training data that teaches the Speech LLM to leverage retrieved terms precisely. Experiments on three language directions of the ACL 60/60 dev set show that RASST improves terminology translation accuracy by up to 16% and increases overall translation quality by up to 3 BLEU points, with ablations confirming the contribution of each component.
CMU's IWSLT 2025 Simultaneous Speech Translation System
Jun 16, 2025This paper presents CMU's submission to the IWSLT 2025 Simultaneous Speech Translation (SST) task for translating unsegmented English speech into Chinese and German text in a streaming manner. Our end-to-end speech-to-text system integrates a chunkwise causal Wav2Vec 2.0 speech encoder, an adapter, and the Qwen2.5-7B-Instruct as the decoder. We use a two-stage simultaneous training procedure on robust speech segments curated from LibriSpeech, CommonVoice, and VoxPopuli datasets, utilizing standard cross-entropy loss. Our model supports adjustable latency through a configurable latency multiplier. Experimental results demonstrate that our system achieves 44.3 BLEU for English-to-Chinese and 25.1 BLEU for English-to-German translations on the ACL60/60 development set, with computation-aware latencies of 2.7 seconds and 2.3 seconds, and theoretical latencies of 2.2 and 1.7 seconds, respectively.
InfiniSST: Simultaneous Translation of Unbounded Speech with Large Language Model
Mar 04, 2025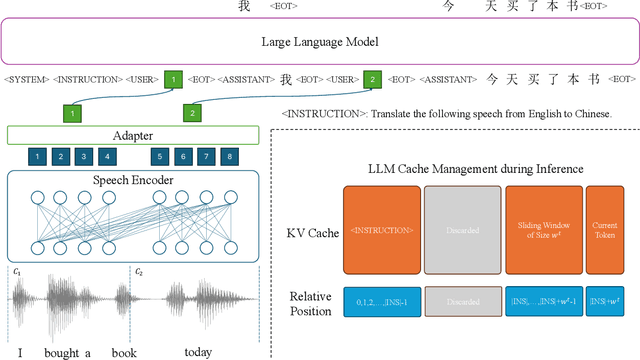



Simultaneous translation of unbounded streaming speech remains a challenging problem due to the need for effectively processing the history speech context and past translations so that quality and latency, including computation overhead, can be balanced. Most prior works assume pre-segmented speech, limiting their real-world applicability. In this paper, we propose InfiniSST, a novel approach that formulates SST as a multi-turn dialogue task, enabling seamless translation of unbounded speech. We construct translation trajectories and robust segments from MuST-C with multi-latency augmentation during training and develop a key-value (KV) cache management strategy to facilitate efficient inference. Experiments on MuST-C En-Es, En-De, and En-Zh demonstrate that InfiniSST reduces computation-aware latency by 0.5 to 1 second while maintaining the same translation quality compared to baselines. Ablation studies further validate the contributions of our data construction and cache management strategy. We release the code at https://github.com/LeiLiLab/InfiniSST
Anticipating Future with Large Language Model for Simultaneous Machine Translation
Oct 29, 2024



Simultaneous machine translation (SMT) takes streaming input utterances and incrementally produces target text. Existing SMT methods only use the partial utterance that has already arrived at the input and the generated hypothesis. Motivated by human interpreters' technique to forecast future words before hearing them, we propose $\textbf{T}$ranslation by $\textbf{A}$nticipating $\textbf{F}$uture (TAF), a method to improve translation quality while retraining low latency. Its core idea is to use a large language model (LLM) to predict future source words and opportunistically translate without introducing too much risk. We evaluate our TAF and multiple baselines of SMT on four language directions. Experiments show that TAF achieves the best translation quality-latency trade-off and outperforms the baselines by up to 5 BLEU points at the same latency (three words).
CA*: Addressing Evaluation Pitfalls in Computation-Aware Latency for Simultaneous Speech Translation
Oct 21, 2024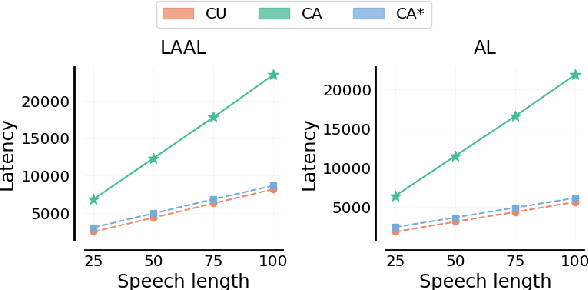

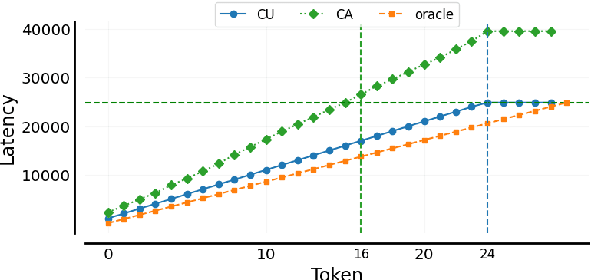
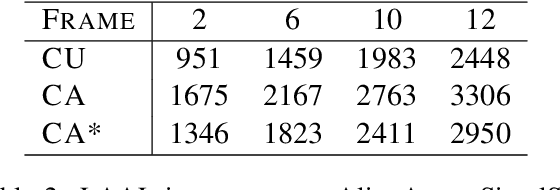
Simultaneous speech translation (SimulST) systems must balance translation quality with response time, making latency measurement crucial for evaluating their real-world performance. However, there has been a longstanding belief that current metrics yield unrealistically high latency measurements in unsegmented streaming settings. In this paper, we investigate this phenomenon, revealing its root cause in a fundamental misconception underlying existing latency evaluation approaches. We demonstrate that this issue affects not only streaming but also segment-level latency evaluation across different metrics. Furthermore, we propose a modification to correctly measure computation-aware latency for SimulST systems, addressing the limitations present in existing metrics.
Translation Canvas: An Explainable Interface to Pinpoint and Analyze Translation Systems
Oct 07, 2024


With the rapid advancement of machine translation research, evaluation toolkits have become essential for benchmarking system progress. Tools like COMET and SacreBLEU offer single quality score assessments that are effective for pairwise system comparisons. However, these tools provide limited insights for fine-grained system-level comparisons and the analysis of instance-level defects. To address these limitations, we introduce Translation Canvas, an explainable interface designed to pinpoint and analyze translation systems' performance: 1) Translation Canvas assists machine translation researchers in comprehending system-level model performance by identifying common errors (their frequency and severity) and analyzing relationships between different systems based on various evaluation metrics. 2) It supports fine-grained analysis by highlighting error spans with explanations and selectively displaying systems' predictions. According to human evaluation, Translation Canvas demonstrates superior performance over COMET and SacreBLEU packages under enjoyability and understandability criteria.
FASST: Fast LLM-based Simultaneous Speech Translation
Aug 18, 2024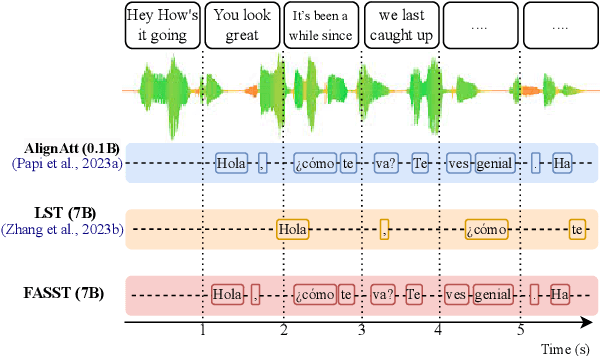


Simultaneous speech translation (SST) takes streaming speech input and generates text translation on the fly. Existing methods either have high latency due to recomputation of input representations, or fall behind of offline ST in translation quality. In this paper, we propose FASST, a fast large language model based method for streaming speech translation. We propose blockwise-causal speech encoding and consistency mask, so that streaming speech input can be encoded incrementally without recomputation. Furthermore, we develop a two-stage training strategy to optimize FASST for simultaneous inference. We evaluate FASST and multiple strong prior models on MuST-C dataset. Experiment results show that FASST achieves the best quality-latency trade-off. It outperforms the previous best model by an average of 1.5 BLEU under the same latency for English to Spanish translation.
CMU's IWSLT 2024 Simultaneous Speech Translation System
Aug 14, 2024This paper describes CMU's submission to the IWSLT 2024 Simultaneous Speech Translation (SST) task for translating English speech to German text in a streaming manner. Our end-to-end speech-to-text (ST) system integrates the WavLM speech encoder, a modality adapter, and the Llama2-7B-Base model as the decoder. We employ a two-stage training approach: initially, we align the representations of speech and text, followed by full fine-tuning. Both stages are trained on MuST-c v2 data with cross-entropy loss. We adapt our offline ST model for SST using a simple fixed hold-n policy. Experiments show that our model obtains an offline BLEU score of 31.1 and a BLEU score of 29.5 under 2 seconds latency on the MuST-C-v2 tst-COMMON.
Structure-Based Drug Design via 3D Molecular Generative Pre-training and Sampling
Feb 22, 2024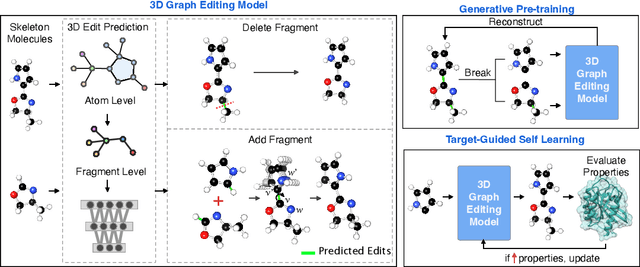
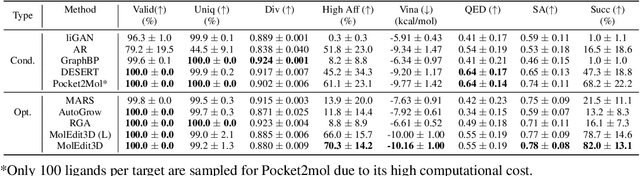

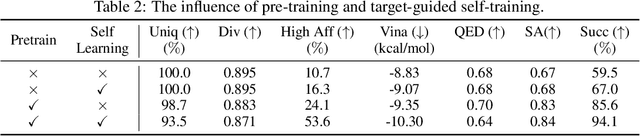
Structure-based drug design aims at generating high affinity ligands with prior knowledge of 3D target structures. Existing methods either use conditional generative model to learn the distribution of 3D ligands given target binding sites, or iteratively modify molecules to optimize a structure-based activity estimator. The former is highly constrained by data quantity and quality, which leaves optimization-based approaches more promising in practical scenario. However, existing optimization-based approaches choose to edit molecules in 2D space, and use molecular docking to estimate the activity using docking predicted 3D target-ligand complexes. The misalignment between the action space and the objective hinders the performance of these models, especially for those employ deep learning for acceleration. In this work, we propose MolEdit3D to combine 3D molecular generation with optimization frameworks. We develop a novel 3D graph editing model to generate molecules using fragments, and pre-train this model on abundant 3D ligands for learning target-independent properties. Then we employ a target-guided self-learning strategy to improve target-related properties using self-sampled molecules. MolEdit3D achieves state-of-the-art performance on majority of the evaluation metrics, and demonstrate strong capability of capturing both target-dependent and -independent properties.
Efficient Monotonic Multihead Attention
Dec 07, 2023
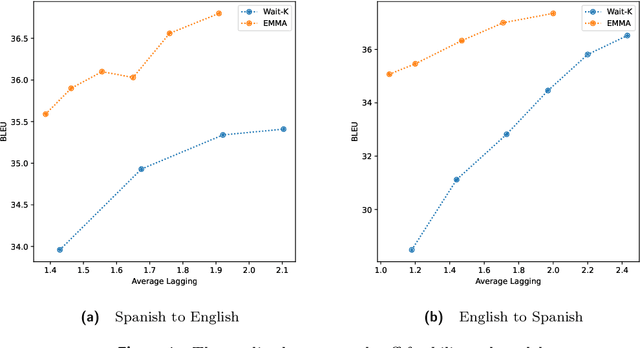
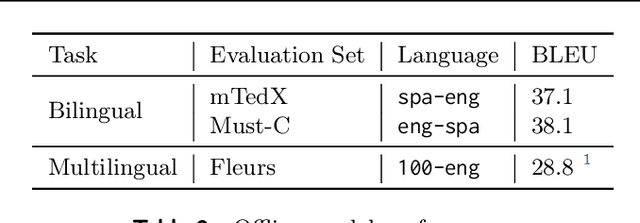
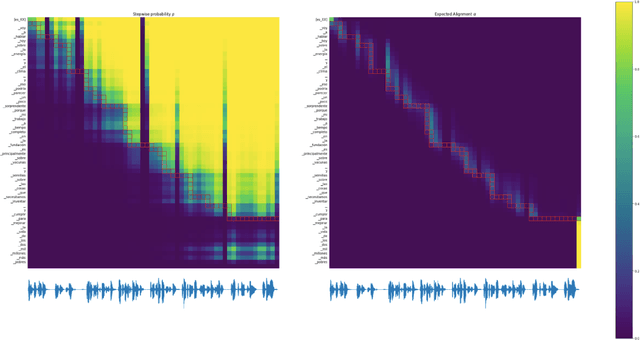
We introduce the Efficient Monotonic Multihead Attention (EMMA), a state-of-the-art simultaneous translation model with numerically-stable and unbiased monotonic alignment estimation. In addition, we present improved training and inference strategies, including simultaneous fine-tuning from an offline translation model and reduction of monotonic alignment variance. The experimental results demonstrate that the proposed model attains state-of-the-art performance in simultaneous speech-to-text translation on the Spanish and English translation task.