 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Policy Optimization for Simultaneous Translation of Unbounded Speech
Apr 22, 2026Simultaneous speech translation (SST) generates translations while receiving partial speech input. Recent advances show that large language models (LLMs) can substantially improve SST quality, but at the cost of high computational overhead. To reduce this cost, prior work reformulates SST as a multi-turn dialogue task, enabling full reuse of the LLM's key-value (KV) cache and eliminating redundant feature recomputation. However, this approach relies on supervised fine-tuning (SFT) data in dialogue form, for which few human annotations exist, and existing synthesis methods cannot guarantee data quality. In this work, we propose a Hierarchical Policy Optimization (HPO) approach that post-train models trained on imperfect SFT data. We introduce a hierarchical reward that balances translation quality and latency objectives. Experiments on English to Chinese/German/Japanese demonstrate improvements of over +7 COMET score and +1.25 MetricX score at a latency of 1.5 seconds. Comprehensive ablation studies further validate the effectiveness of different quality rewards, hierarchical reward formulations, and segmentation strategies. Code can be found here https://github.com/owaski/HPO
CS-FLEURS: A Massively Multilingual and Code-Switched Speech Dataset
Sep 17, 2025We present CS-FLEURS, a new dataset for developing and evaluating code-switched speech recognition and translation systems beyond high-resourced languages. CS-FLEURS consists of 4 test sets which cover in total 113 unique code-switched language pairs across 52 languages: 1) a 14 X-English language pair set with real voices reading synthetically generated code-switched sentences, 2) a 16 X-English language pair set with generative text-to-speech 3) a 60 {Arabic, Mandarin, Hindi, Spanish}-X language pair set with the generative text-to-speech, and 4) a 45 X-English lower-resourced language pair test set with concatenative text-to-speech. Besides the four test sets, CS-FLEURS also provides a training set with 128 hours of generative text-to-speech data across 16 X-English language pairs. Our hope is that CS-FLEURS helps to broaden the scope of future code-switched speech research. Dataset link: https://huggingface.co/datasets/byan/cs-fleurs.
Improving Multilingual ASR in the Wild Using Simple N-best Re-ranking
Sep 27, 2024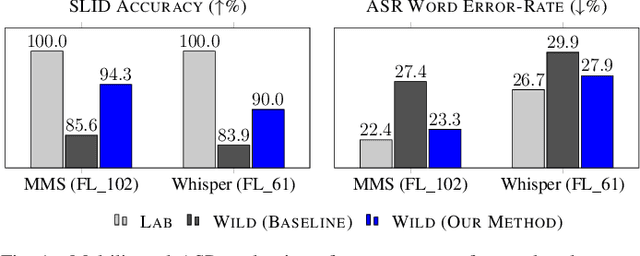
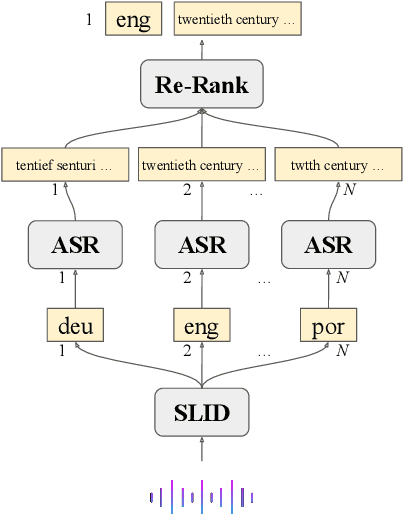
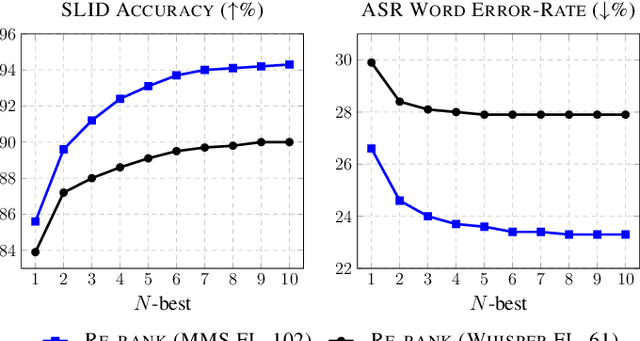

Multilingual Automatic Speech Recognition (ASR) models are typically evaluated in a setting where the ground-truth language of the speech utterance is known, however, this is often not the case for most practical settings. Automatic Spoken Language Identification (SLID) models are not perfect and misclassifications have a substantial impact on the final ASR accuracy. In this paper, we present a simple and effective N-best re-ranking approach to improve multilingual ASR accuracy for several prominent acoustic models by employing external features such as language models and text-based language identification models. Our results on FLEURS using the MMS and Whisper models show spoken language identification accuracy improvements of 8.7% and 6.1%, respectively and word error rates which are 3.3% and 2.0% lower on these benchmarks.
CMU's IWSLT 2024 Simultaneous Speech Translation System
Aug 14, 2024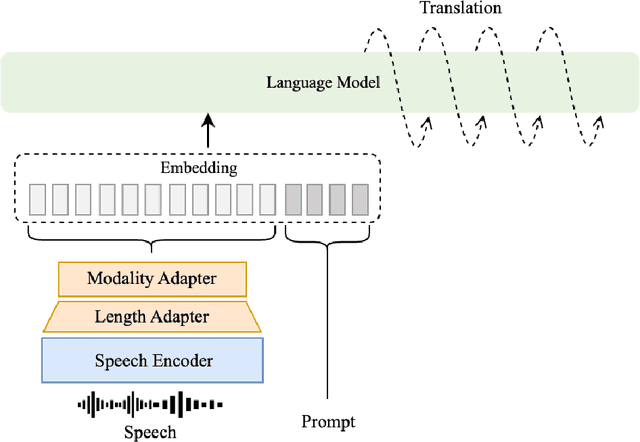
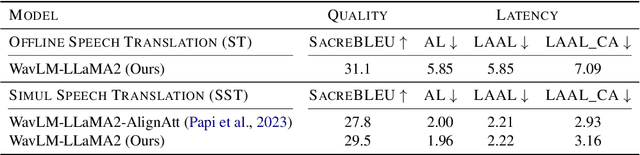
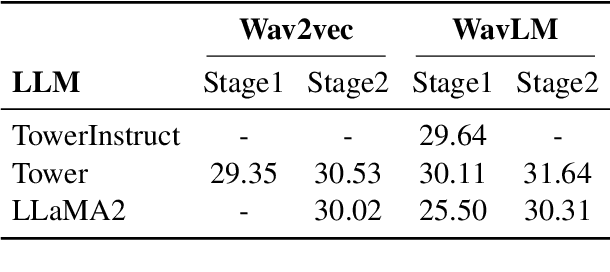
This paper describes CMU's submission to the IWSLT 2024 Simultaneous Speech Translation (SST) task for translating English speech to German text in a streaming manner. Our end-to-end speech-to-text (ST) system integrates the WavLM speech encoder, a modality adapter, and the Llama2-7B-Base model as the decoder. We employ a two-stage training approach: initially, we align the representations of speech and text, followed by full fine-tuning. Both stages are trained on MuST-c v2 data with cross-entropy loss. We adapt our offline ST model for SST using a simple fixed hold-n policy. Experiments show that our model obtains an offline BLEU score of 31.1 and a BLEU score of 29.5 under 2 seconds latency on the MuST-C-v2 tst-COMMON.
4D ASR: Joint Beam Search Integrating CTC, Attention, Transducer, and Mask Predict Decoders
Jun 05, 2024



End-to-end automatic speech recognition (E2E-ASR) can be classified into several network architectures, such as connectionist temporal classification (CTC), recurrent neural network transducer (RNN-T), attention-based encoder-decoder, and mask-predict models. Each network architecture has advantages and disadvantages, leading practitioners to switch between these different models depending on application requirements. Instead of building separate models, we propose a joint modeling scheme where four decoders (CTC, RNN-T, attention, and mask-predict) share the same encoder -- we refer to this as 4D modeling. The 4D model is trained using multitask learning, which will bring model regularization and maximize the model robustness thanks to their complementary properties. To efficiently train the 4D model, we introduce a two-stage training strategy that stabilizes multitask learning. In addition, we propose three novel one-pass beam search algorithms by combining three decoders (CTC, RNN-T, and attention) to further improve performance. These three beam search algorithms differ in which decoder is used as the primary decoder. We carefully evaluate the performance and computational tradeoffs associated with each algorithm. Experimental results demonstrate that the jointly trained 4D model outperforms the E2E-ASR models trained with only one individual decoder. Furthermore, we demonstrate that the proposed one-pass beam search algorithm outperforms the previously proposed CTC/attention decoding.
OWSM v3.1: Better and Faster Open Whisper-Style Speech Models based on E-Branchformer
Jan 30, 2024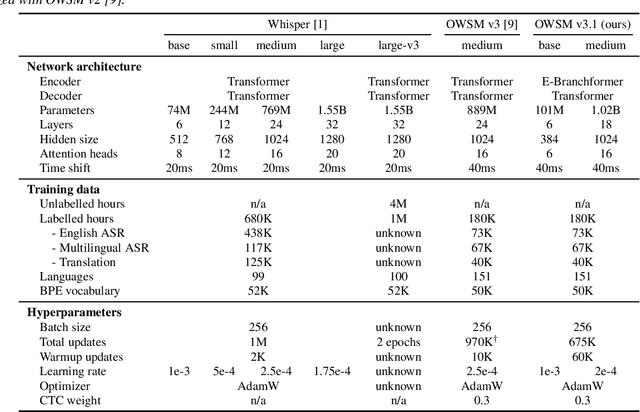
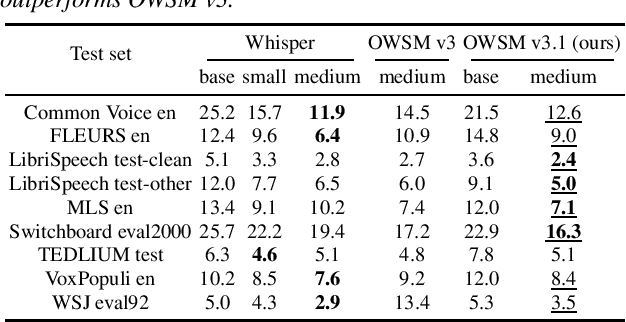
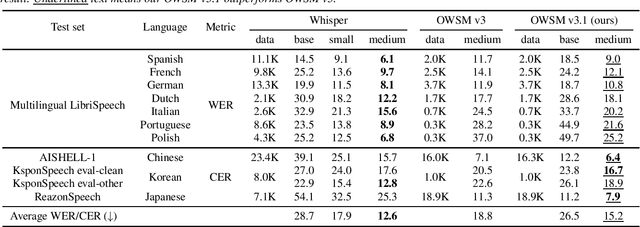
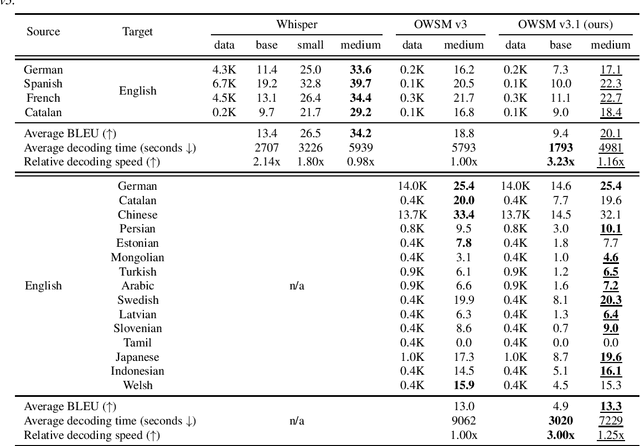
Recent studies have advocated for fully open foundation models to promote transparency and open science. As an initial step, the Open Whisper-style Speech Model (OWSM) reproduced OpenAI's Whisper using publicly available data and open-source toolkits. With the aim of reproducing Whisper, the previous OWSM v1 through v3 models were still based on Transformer, which might lead to inferior performance compared to other state-of-the-art speech encoders. In this work, we aim to improve the performance and efficiency of OWSM without extra training data. We present E-Branchformer based OWSM v3.1 models at two scales, i.e., 100M and 1B. The 1B model is the largest E-Branchformer based speech model that has been made publicly available. It outperforms the previous OWSM v3 in a vast majority of evaluation benchmarks, while demonstrating up to 25% faster inference speed. We publicly release the data preparation scripts, pre-trained models and training logs.
Reproducing Whisper-Style Training Using an Open-Source Toolkit and Publicly Available Data
Oct 02, 2023Pre-training speech models on large volumes of data has achieved remarkable success. OpenAI Whisper is a multilingual multitask model trained on 680k hours of supervised speech data. It generalizes well to various speech recognition and translation benchmarks even in a zero-shot setup. However, the full pipeline for developing such models (from data collection to training) is not publicly accessible, which makes it difficult for researchers to further improve its performance and address training-related issues such as efficiency, robustness, fairness, and bias. This work presents an Open Whisper-style Speech Model (OWSM), which reproduces Whisper-style training using an open-source toolkit and publicly available data. OWSM even supports more translation directions and can be more efficient to train. We will publicly release all scripts used for data preparation, training, inference, and scoring as well as pre-trained models and training logs to promote open science.
Joint Prediction and Denoising for Large-scale Multilingual Self-supervised Learning
Sep 28, 2023Multilingual self-supervised learning (SSL) has often lagged behind state-of-the-art (SOTA) methods due to the expenses and complexity required to handle many languages. This further harms the reproducibility of SSL, which is already limited to few research groups due to its resource usage. We show that more powerful techniques can actually lead to more efficient pre-training, opening SSL to more research groups. We propose WavLabLM, which extends WavLM's joint prediction and denoising to 40k hours of data across 136 languages. To build WavLabLM, we devise a novel multi-stage pre-training method, designed to address the language imbalance of multilingual data. WavLabLM achieves comparable performance to XLS-R on ML-SUPERB with less than 10% of the training data, making SSL realizable with academic compute. We show that further efficiency can be achieved with a vanilla HuBERT Base model, which can maintain 94% of XLS-R's performance with only 3% of the data, 4 GPUs, and limited trials. We open-source all code and models in ESPnet.
Speech collage: code-switched audio generation by collaging monolingual corpora
Sep 27, 2023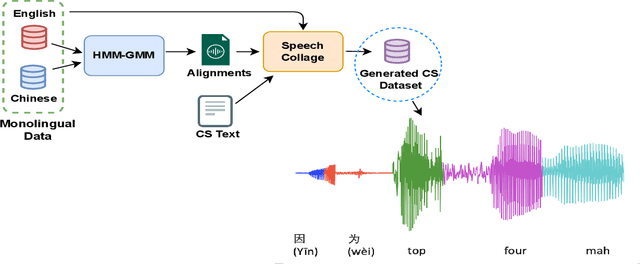
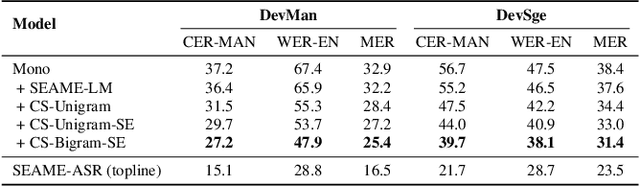
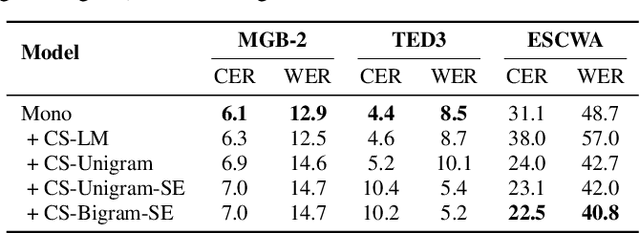
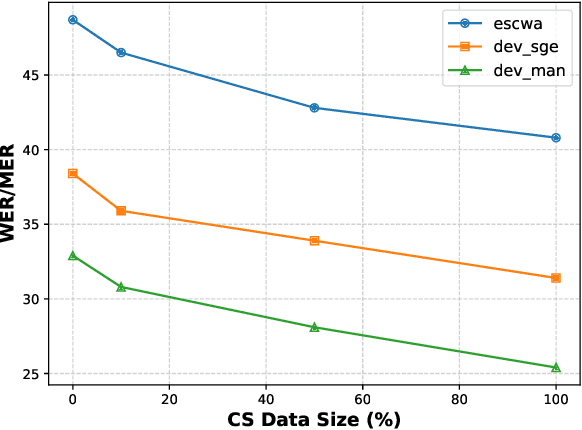
Designing effective automatic speech recognition (ASR) systems for Code-Switching (CS) often depends on the availability of the transcribed CS resources. To address data scarcity, this paper introduces Speech Collage, a method that synthesizes CS data from monolingual corpora by splicing audio segments. We further improve the smoothness quality of audio generation using an overlap-add approach. We investigate the impact of generated data on speech recognition in two scenarios: using in-domain CS text and a zero-shot approach with synthesized CS text. Empirical results highlight up to 34.4% and 16.2% relative reductions in Mixed-Error Rate and Word-Error Rate for in-domain and zero-shot scenarios, respectively. Lastly, we demonstrate that CS augmentation bolsters the model's code-switching inclination and reduces its monolingual bias.
Cross-Modal Multi-Tasking for Speech-to-Text Translation via Hard Parameter Sharing
Sep 27, 2023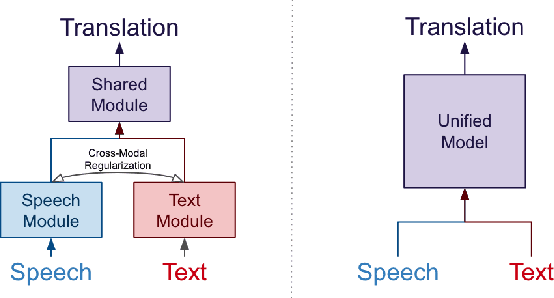

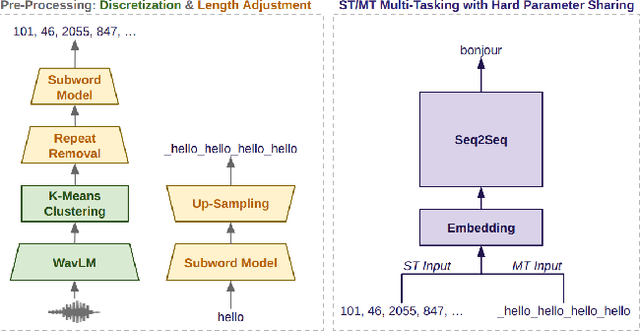

Recent works in end-to-end speech-to-text translation (ST) have proposed multi-tasking methods with soft parameter sharing which leverage machine translation (MT) data via secondary encoders that map text inputs to an eventual cross-modal representation. In this work, we instead propose a ST/MT multi-tasking framework with hard parameter sharing in which all model parameters are shared cross-modally. Our method reduces the speech-text modality gap via a pre-processing stage which converts speech and text inputs into two discrete token sequences of similar length -- this allows models to indiscriminately process both modalities simply using a joint vocabulary. With experiments on MuST-C, we demonstrate that our multi-tasking framework improves attentional encoder-decoder, Connectionist Temporal Classification (CTC), transducer, and joint CTC/attention models by an average of +0.5 BLEU without any external MT data. Further, we show that this framework incorporates external MT data, yielding +0.8 BLEU, and also improves transfer learning from pre-trained textual models, yielding +1.8 BLEU.